 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamControl-v2: Simpler and Scalable Autonomous Humanoid Skills via Trainable Guided Diffusion Priors
Mar 31, 2026Developing robust autonomous loco-manipulation skills for humanoids remains an open problem in robotics. While RL has been applied successfully to legged locomotion, applying it to complex, interaction-rich manipulation tasks is harder given long-horizon planning challenges for manipulation. A recent approach along these lines is DreamControl, which addresses these issues by leveraging off-the-shelf human motion diffusion models as a generative prior to guide RL policies during training. In this paper, we investigate the impact of DreamControl's motion prior and propose an improved framework that trains a guided diffusion model directly in the humanoid robot's motion space, aggregating diverse human and robot datasets into a unified embodiment space. We demonstrate that our approach captures a wider range of skills due to the larger training data mixture and establishes a more automated pipeline by removing the need for manual filtering interventions. Furthermore, we show that scaling the generation of reference trajectories is important for achieving robust downstream RL policies. We validate our approach through extensive experiments in simulation and on a real Unitree-G1.
DreamControl: Human-Inspired Whole-Body Humanoid Control for Scene Interaction via Guided Diffusion
Sep 17, 2025
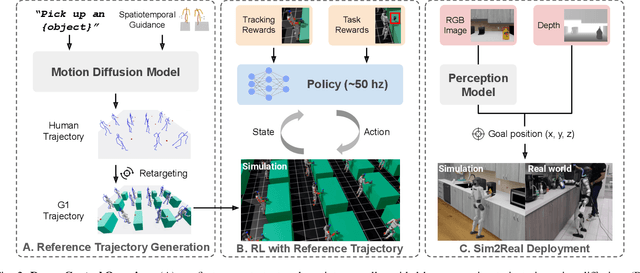

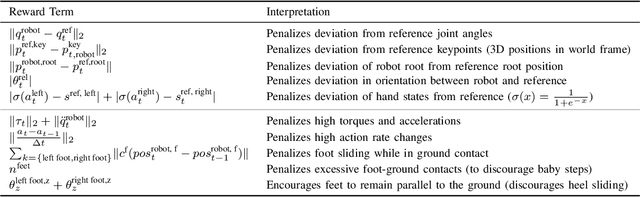
We introduce DreamControl, a novel methodology for learning autonomous whole-body humanoid skills. DreamControl leverages the strengths of diffusion models and Reinforcement Learning (RL): our core innovation is the use of a diffusion prior trained on human motion data, which subsequently guides an RL policy in simulation to complete specific tasks of interest (e.g., opening a drawer or picking up an object). We demonstrate that this human motion-informed prior allows RL to discover solutions unattainable by direct RL, and that diffusion models inherently promote natural looking motions, aiding in sim-to-real transfer. We validate DreamControl's effectiveness on a Unitree G1 robot across a diverse set of challenging tasks involving simultaneous lower and upper body control and object interaction.
LATTE-MV: Learning to Anticipate Table Tennis Hits from Monocular Videos
Mar 26, 2025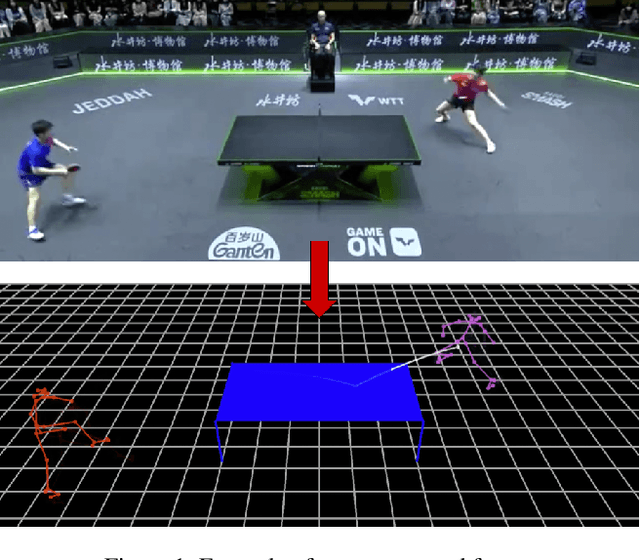


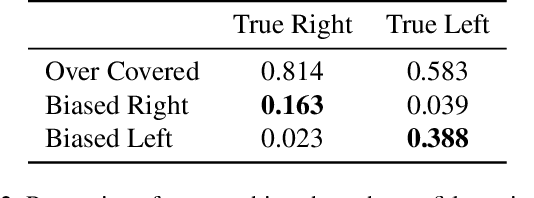
Physical agility is a necessary skill in competitive table tennis, but by no means sufficient. Champions excel in this fast-paced and highly dynamic environment by anticipating their opponent's intent - buying themselves the necessary time to react. In this work, we take one step towards designing such an anticipatory agent. Previous works have developed systems capable of real-time table tennis gameplay, though they often do not leverage anticipation. Among the works that forecast opponent actions, their approaches are limited by dataset size and variety. Our paper contributes (1) a scalable system for reconstructing monocular video of table tennis matches in 3D and (2) an uncertainty-aware controller that anticipates opponent actions. We demonstrate in simulation that our policy improves the ball return rate against high-speed hits from 49.9% to 59.0% as compared to a baseline non-anticipatory policy.
Real-Time Algorithms for Game-Theoretic Motion Planning and Control in Autonomous Racing using Near-Potential Function
Dec 12, 2024



Autonomous racing extends beyond the challenge of controlling a racecar at its physical limits. Professional racers employ strategic maneuvers to outwit other competing opponents to secure victory. While modern control algorithms can achieve human-level performance by computing offline racing lines for single-car scenarios, research on real-time algorithms for multi-car autonomous racing is limited. To bridge this gap, we develop game-theoretic modeling framework that incorporates the competitive aspect of autonomous racing like overtaking and blocking through a novel policy parametrization, while operating the car at its limit. Furthermore, we propose an algorithmic approach to compute the (approximate) Nash equilibrium strategy, which represents the optimal approach in the presence of competing agents. Specifically, we introduce an algorithm inspired by recently introduced framework of dynamic near-potential function, enabling real-time computation of the Nash equilibrium. Our approach comprises two phases: offline and online. During the offline phase, we use simulated racing data to learn a near-potential function that approximates utility changes for agents. This function facilitates the online computation of approximate Nash equilibria by maximizing its value. We evaluate our method in a head-to-head 3-car racing scenario, demonstrating superior performance compared to several existing baselines.
Agile Mobility with Rapid Online Adaptation via Meta-learning and Uncertainty-aware MPPI
Oct 09, 2024


Modern non-linear model-based controllers require an accurate physics model and model parameters to be able to control mobile robots at their limits. Also, due to surface slipping at high speeds, the friction parameters may continually change (like tire degradation in autonomous racing), and the controller may need to adapt rapidly. Many works derive a task-specific robot model with a parameter adaptation scheme that works well for the task but requires a lot of effort and tuning for each platform and task. In this work, we design a full model-learning-based controller based on meta pre-training that can very quickly adapt using few-shot dynamics data to any wheel-based robot with any model parameters, while also reasoning about model uncertainty. We demonstrate our results in small-scale numeric simulation, the large-scale Unity simulator, and on a medium-scale hardware platform with a wide range of settings. We show that our results are comparable to domain-specific well-engineered controllers, and have excellent generalization performance across all scenarios.
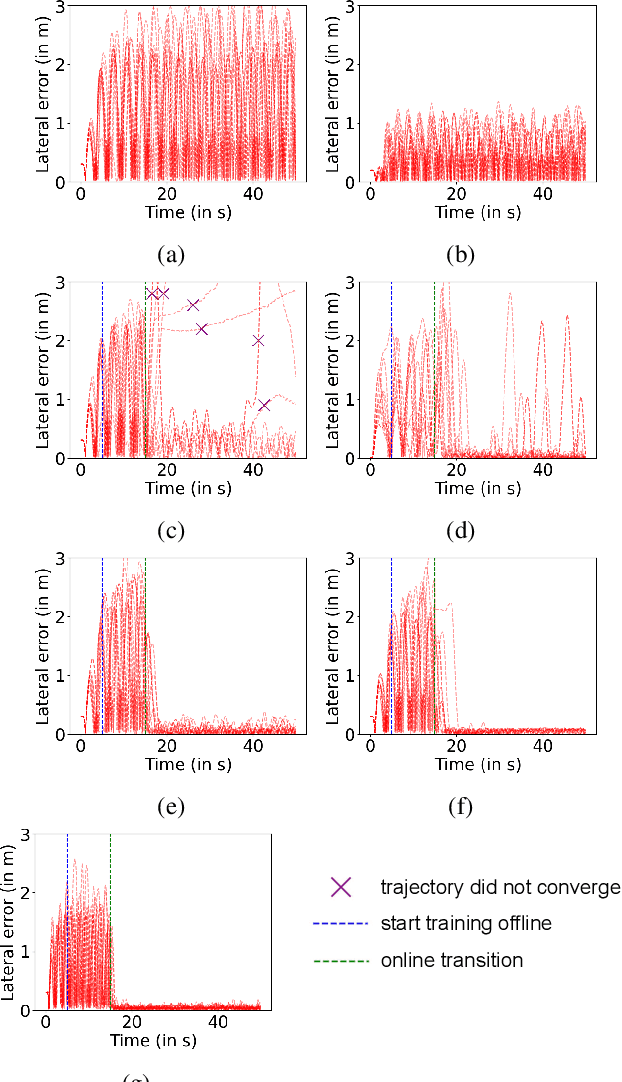
Disturbance Observer-based Control Barrier Functions with Residual Model Learning for Safe Reinforcement Learning
Oct 09, 2024
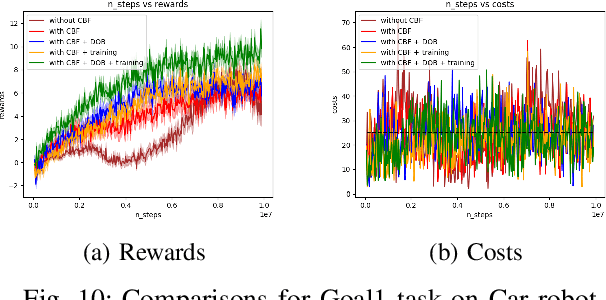
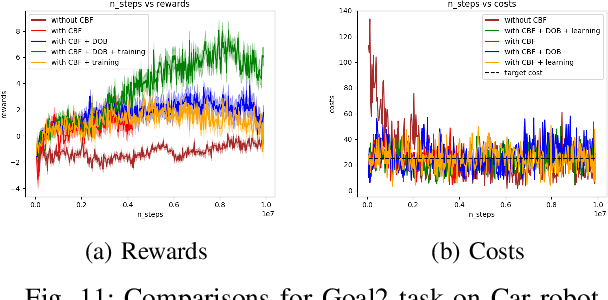

Reinforcement learning (RL) agents need to explore their environment to learn optimal behaviors and achieve maximum rewards. However, exploration can be risky when training RL directly on real systems, while simulation-based training introduces the tricky issue of the sim-to-real gap. Recent approaches have leveraged safety filters, such as control barrier functions (CBFs), to penalize unsafe actions during RL training. However, the strong safety guarantees of CBFs rely on a precise dynamic model. In practice, uncertainties always exist, including internal disturbances from the errors of dynamics and external disturbances such as wind. In this work, we propose a new safe RL framework based on disturbance rejection-guarded learning, which allows for an almost model-free RL with an assumed but not necessarily precise nominal dynamic model. We demonstrate our results on the Safety-gym benchmark for Point and Car robots on all tasks where we can outperform state-of-the-art approaches that use only residual model learning or a disturbance observer (DOB). We further validate the efficacy of our framework using a physical F1/10 racing car. Videos: https://sites.google.com/view/res-dob-cbf-rl
AnyCar to Anywhere: Learning Universal Dynamics Model for Agile and Adaptive Mobility
Sep 24, 2024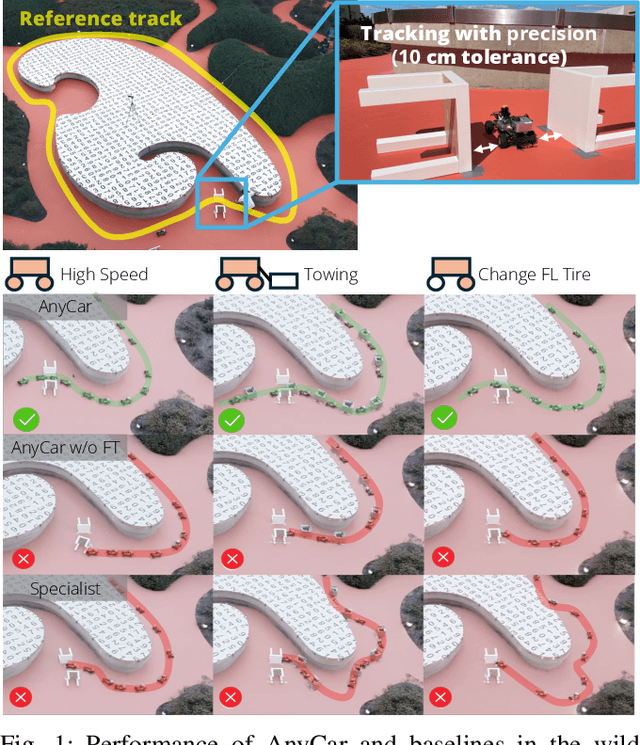
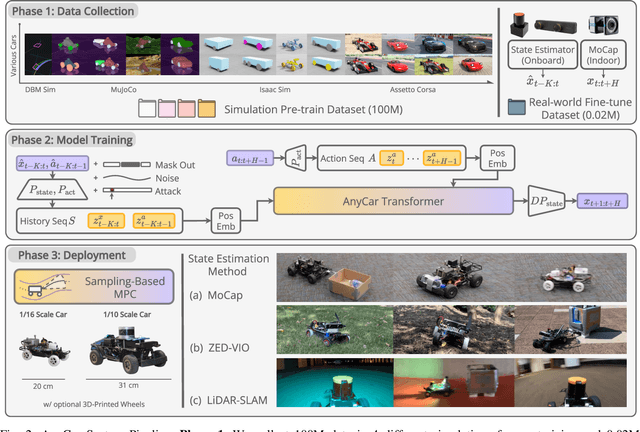


Recent works in the robot learning community have successfully introduced generalist models capable of controlling various robot embodiments across a wide range of tasks, such as navigation and locomotion. However, achieving agile control, which pushes the limits of robotic performance, still relies on specialist models that require extensive parameter tuning. To leverage generalist-model adaptability and flexibility while achieving specialist-level agility, we propose AnyCar, a transformer-based generalist dynamics model designed for agile control of various wheeled robots. To collect training data, we unify multiple simulators and leverage different physics backends to simulate vehicles with diverse sizes, scales, and physical properties across various terrains. With robust training and real-world fine-tuning, our model enables precise adaptation to different vehicles, even in the wild and under large state estimation errors. In real-world experiments, AnyCar shows both few-shot and zero-shot generalization across a wide range of vehicles and environments, where our model, combined with a sampling-based MPC, outperforms specialist models by up to 54%. These results represent a key step toward building a foundation model for agile wheeled robot control. We will also open-source our framework to support further research.
WROOM: An Autonomous Driving Approach for Off-Road Navigation
Apr 12, 2024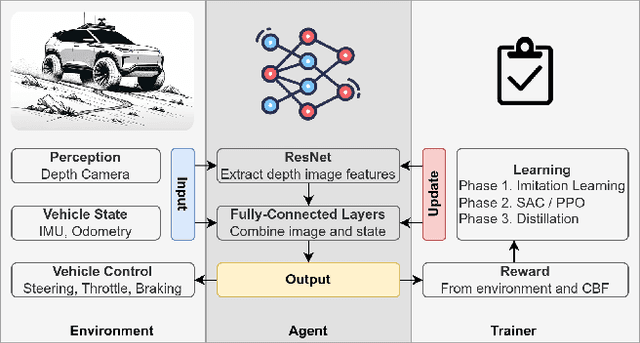



Off-road navigation is a challenging problem both at the planning level to get a smooth trajectory and at the control level to avoid flipping over, hitting obstacles, or getting stuck at a rough patch. There have been several recent works using classical approaches involving depth map prediction followed by smooth trajectory planning and using a controller to track it. We design an end-to-end reinforcement learning (RL) system for an autonomous vehicle in off-road environments using a custom-designed simulator in the Unity game engine. We warm-start the agent by imitating a rule-based controller and utilize Proximal Policy Optimization (PPO) to improve the policy based on a reward that incorporates Control Barrier Functions (CBF), facilitating the agent's ability to generalize effectively to real-world scenarios. The training involves agents concurrently undergoing domain-randomized trials in various environments. We also propose a novel simulation environment to replicate off-road driving scenarios and deploy our proposed approach on a real buggy RC car. Videos and additional results: https://sites.google.com/view/wroom-utd/home
Towards Optimal Head-to-head Autonomous Racing with Curriculum Reinforcement Learning
Aug 25, 2023



Head-to-head autonomous racing is a challenging problem, as the vehicle needs to operate at the friction or handling limits in order to achieve minimum lap times while also actively looking for strategies to overtake/stay ahead of the opponent. In this work we propose a head-to-head racing environment for reinforcement learning which accurately models vehicle dynamics. Some previous works have tried learning a policy directly in the complex vehicle dynamics environment but have failed to learn an optimal policy. In this work, we propose a curriculum learning-based framework by transitioning from a simpler vehicle model to a more complex real environment to teach the reinforcement learning agent a policy closer to the optimal policy. We also propose a control barrier function-based safe reinforcement learning algorithm to enforce the safety of the agent in a more effective way while not compromising on optimality.
Adaptive Planning and Control with Time-Varying Tire Models for Autonomous Racing Using Extreme Learning Machine
Mar 14, 2023



Autonomous racing is a challenging problem, as the vehicle needs to operate at the friction or handling limits in order to achieve minimum lap times. Autonomous race cars require highly accurate perception, state estimation, planning and precise application of controls. What makes it even more challenging is the accurate identification of vehicle model parameters that dictate the effects of the lateral tire slip, which may change over time, for example, due to wear and tear of the tires. Current works either propose model identification offline or need good parameters to start with (within 15-20\% of actual value), which is not enough to account for major changes in tire model that occur during actual races when driving at the control limits. We propose a unified framework which learns the tire model online from the collected data, as well as adjusts the model based on environmental changes even if the model parameters change by a higher margin. We demonstrate our approach in numeric and high-fidelity simulators for a 1:43 scale race car and a full-size car.