 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamControl: Human-Inspired Whole-Body Humanoid Control for Scene Interaction via Guided Diffusion
Sep 17, 2025
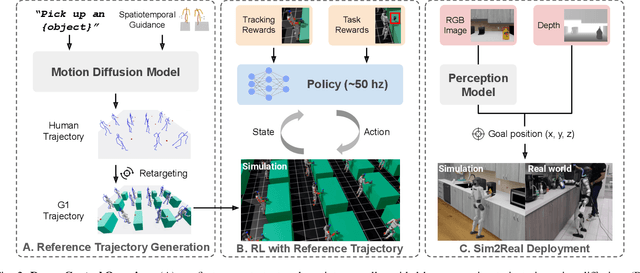

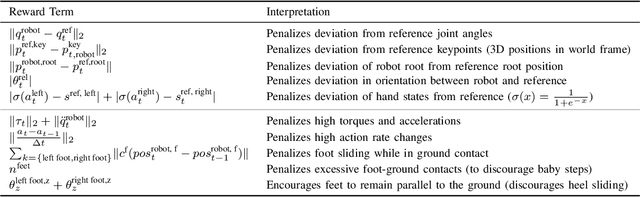
We introduce DreamControl, a novel methodology for learning autonomous whole-body humanoid skills. DreamControl leverages the strengths of diffusion models and Reinforcement Learning (RL): our core innovation is the use of a diffusion prior trained on human motion data, which subsequently guides an RL policy in simulation to complete specific tasks of interest (e.g., opening a drawer or picking up an object). We demonstrate that this human motion-informed prior allows RL to discover solutions unattainable by direct RL, and that diffusion models inherently promote natural looking motions, aiding in sim-to-real transfer. We validate DreamControl's effectiveness on a Unitree G1 robot across a diverse set of challenging tasks involving simultaneous lower and upper body control and object interaction.
Symbolic Graph Inference for Compound Scene Understanding
Oct 30, 2024


Scene understanding is a fundamental capability needed in many domains, ranging from question-answering to robotics. Unlike recent end-to-end approaches that must explicitly learn varying compositions of the same scene, our method reasons over their constituent objects and analyzes their arrangement to infer a scene's meaning. We propose a novel approach that reasons over a scene's scene- and knowledge-graph, capturing spatial information while being able to utilize general domain knowledge in a joint graph search. Empirically, we demonstrate the feasibility of our method on the ADE20K dataset and compare it to current scene understanding approaches.
WROOM: An Autonomous Driving Approach for Off-Road Navigation
Apr 12, 2024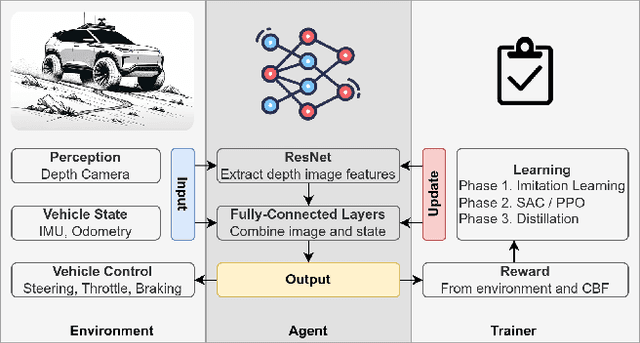



Off-road navigation is a challenging problem both at the planning level to get a smooth trajectory and at the control level to avoid flipping over, hitting obstacles, or getting stuck at a rough patch. There have been several recent works using classical approaches involving depth map prediction followed by smooth trajectory planning and using a controller to track it. We design an end-to-end reinforcement learning (RL) system for an autonomous vehicle in off-road environments using a custom-designed simulator in the Unity game engine. We warm-start the agent by imitating a rule-based controller and utilize Proximal Policy Optimization (PPO) to improve the policy based on a reward that incorporates Control Barrier Functions (CBF), facilitating the agent's ability to generalize effectively to real-world scenarios. The training involves agents concurrently undergoing domain-randomized trials in various environments. We also propose a novel simulation environment to replicate off-road driving scenarios and deploy our proposed approach on a real buggy RC car. Videos and additional results: https://sites.google.com/view/wroom-utd/home
ShapeGrasp: Zero-Shot Task-Oriented Grasping with Large Language Models through Geometric Decomposition
Mar 26, 2024Task-oriented grasping of unfamiliar objects is a necessary skill for robots in dynamic in-home environments. Inspired by the human capability to grasp such objects through intuition about their shape and structure, we present a novel zero-shot task-oriented grasping method leveraging a geometric decomposition of the target object into simple, convex shapes that we represent in a graph structure, including geometric attributes and spatial relationships. Our approach employs minimal essential information - the object's name and the intended task - to facilitate zero-shot task-oriented grasping. We utilize the commonsense reasoning capabilities of large language models to dynamically assign semantic meaning to each decomposed part and subsequently reason over the utility of each part for the intended task. Through extensive experiments on a real-world robotics platform, we demonstrate that our grasping approach's decomposition and reasoning pipeline is capable of selecting the correct part in 92% of the cases and successfully grasping the object in 82% of the tasks we evaluate. Additional videos, experiments, code, and data are available on our project website: https://shapegrasp.github.io/.
Knowledge-Guided Short-Context Action Anticipation in Human-Centric Videos
Sep 12, 2023



This work focuses on anticipating long-term human actions, particularly using short video segments, which can speed up editing workflows through improved suggestions while fostering creativity by suggesting narratives. To this end, we imbue a transformer network with a symbolic knowledge graph for action anticipation in video segments by boosting certain aspects of the transformer's attention mechanism at run-time. Demonstrated on two benchmark datasets, Breakfast and 50Salads, our approach outperforms current state-of-the-art methods for long-term action anticipation using short video context by up to 9%.
Sample-Efficient Learning of Novel Visual Concepts
Jun 15, 2023



Despite the advances made in visual object recognition, state-of-the-art deep learning models struggle to effectively recognize novel objects in a few-shot setting where only a limited number of examples are provided. Unlike humans who excel at such tasks, these models often fail to leverage known relationships between entities in order to draw conclusions about such objects. In this work, we show that incorporating a symbolic knowledge graph into a state-of-the-art recognition model enables a new approach for effective few-shot classification. In our proposed neuro-symbolic architecture and training methodology, the knowledge graph is augmented with additional relationships extracted from a small set of examples, improving its ability to recognize novel objects by considering the presence of interconnected entities. Unlike existing few-shot classifiers, we show that this enables our model to incorporate not only objects but also abstract concepts and affordances. The existence of the knowledge graph also makes this approach amenable to interpretability through analysis of the relationships contained within it. We empirically show that our approach outperforms current state-of-the-art few-shot multi-label classification methods on the COCO dataset and evaluate the addition of abstract concepts and affordances on the Visual Genome dataset.
Emotionally Enhanced Talking Face Generation
Mar 26, 2023



Several works have developed end-to-end pipelines for generating lip-synced talking faces with various real-world applications, such as teaching and language translation in videos. However, these prior works fail to create realistic-looking videos since they focus little on people's expressions and emotions. Moreover, these methods' effectiveness largely depends on the faces in the training dataset, which means they may not perform well on unseen faces. To mitigate this, we build a talking face generation framework conditioned on a categorical emotion to generate videos with appropriate expressions, making them more realistic and convincing. With a broad range of six emotions, i.e., \emph{happiness}, \emph{sadness}, \emph{fear}, \emph{anger}, \emph{disgust}, and \emph{neutral}, we show that our model can adapt to arbitrary identities, emotions, and languages. Our proposed framework is equipped with a user-friendly web interface with a real-time experience for talking face generation with emotions. We also conduct a user study for subjective evaluation of our interface's usability, design, and functionality. Project page: https://midas.iiitd.edu.in/emo/
FaIRCoP: Facial Image Retrieval using Contrastive Personalization
May 28, 2022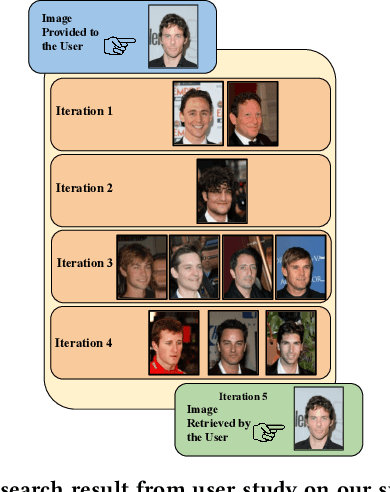
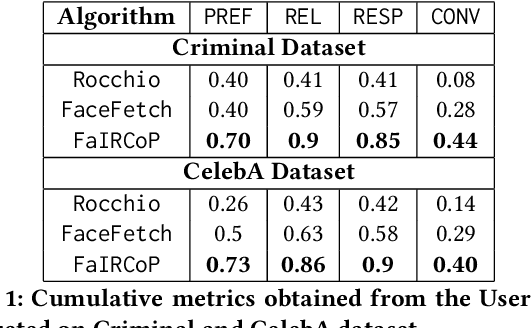

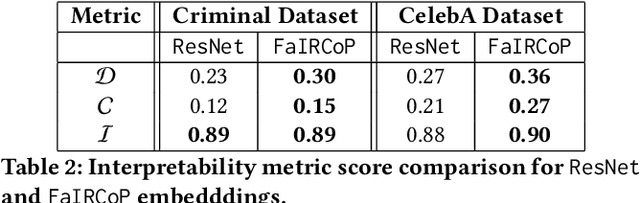
Retrieving facial images from attributes plays a vital role in various systems such as face recognition and suspect identification. Compared to other image retrieval tasks, facial image retrieval is more challenging due to the high subjectivity involved in describing a person's facial features. Existing methods do so by comparing specific characteristics from the user's mental image against the suggested images via high-level supervision such as using natural language. In contrast, we propose a method that uses a relatively simpler form of binary supervision by utilizing the user's feedback to label images as either similar or dissimilar to the target image. Such supervision enables us to exploit the contrastive learning paradigm for encapsulating each user's personalized notion of similarity. For this, we propose a novel loss function optimized online via user feedback. We validate the efficacy of our proposed approach using a carefully designed testbed to simulate user feedback and a large-scale user study. Our experiments demonstrate that our method iteratively improves personalization, leading to faster convergence and enhanced recommendation relevance, thereby, improving user satisfaction. Our proposed framework is also equipped with a user-friendly web interface with a real-time experience for facial image retrieval.
Target-Following Double Deep Q-Networks for UAVs
May 12, 2021
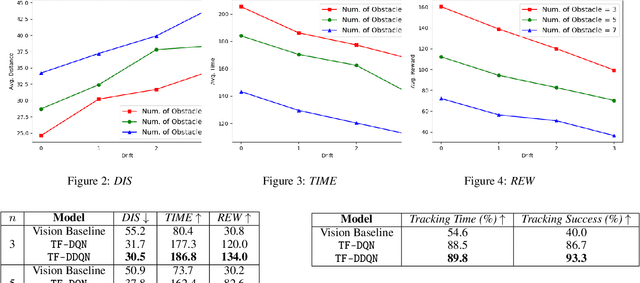


Target tracking in unknown real-world environments in the presence of obstacles and target motion uncertainty demand agents to develop an intrinsic understanding of the environment in order to predict the suitable actions to be taken at each time step. This task requires the agents to maximize the visibility of the mobile target maneuvering randomly in a network of roads by learning a policy that takes into consideration the various aspects of a real-world environment. In this paper, we propose a DDQN-based extension to the state-of-the-art in target tracking using a UAV TF-DQN, that we call TF-DDQN, that isolates the value estimation and evaluation steps. Additionally, in order to carefully benchmark the performance of any given target tracking algorithm, we introduce a novel target tracking evaluation scheme that quantifies its efficacy in terms of a wide set of diverse parameters. To replicate the real-world setting, we test our approach against standard baselines for the task of target tracking in complex environments with varying drift conditions and changes in environmental configuration.
Emerging Trends of Multimodal Research in Vision and Language
Oct 19, 2020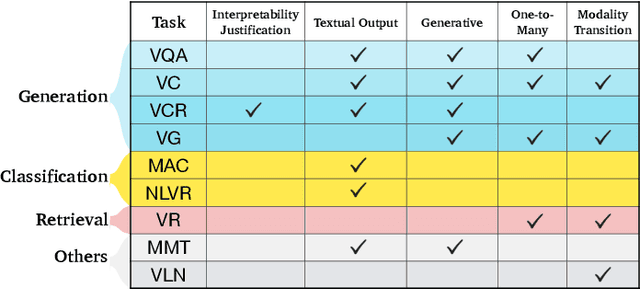
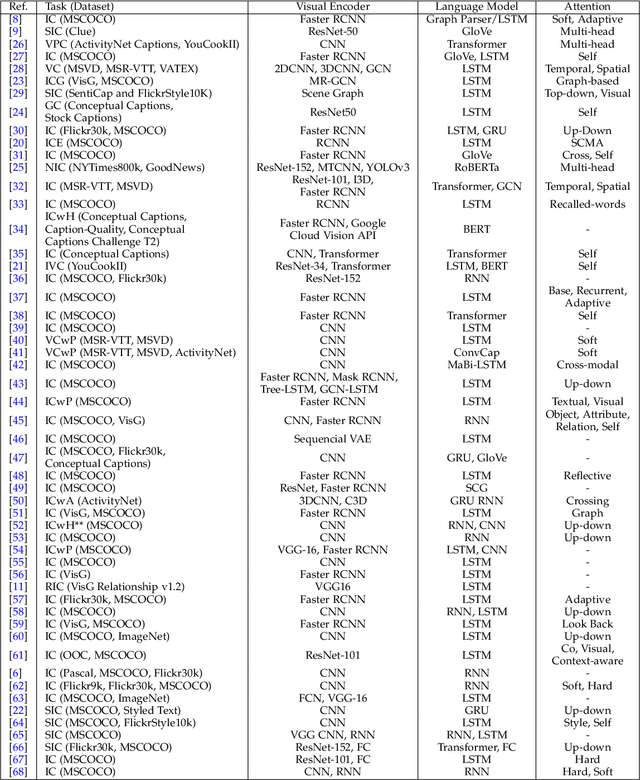
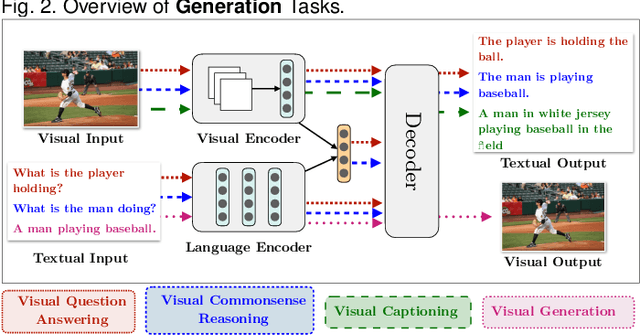
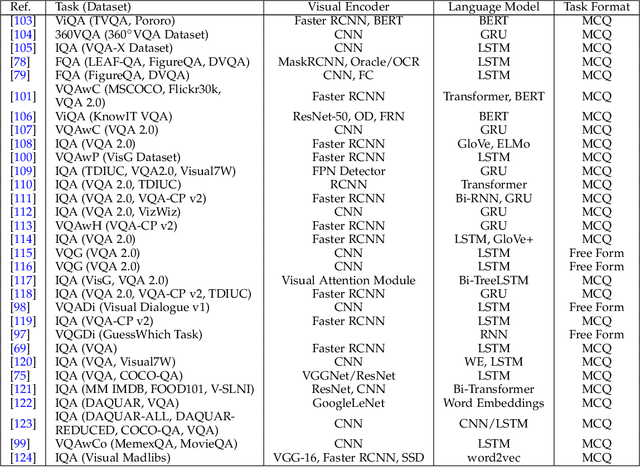
Deep Learning and its applications have cascaded impactful research and development with a diverse range of modalities present in the real-world data. More recently, this has enhanced research interests in the intersection of the Vision and Language arena with its numerous applications and fast-paced growth. In this paper, we present a detailed overview of the latest trends in research pertaining to visual and language modalities. We look at its applications in their task formulations and how to solve various problems related to semantic perception and content generation. We also address task-specific trends, along with their evaluation strategies and upcoming challenges. Moreover, we shed some light on multi-disciplinary patterns and insights that have emerged in the recent past, directing this field towards more modular and transparent intelligent systems. This survey identifies key trends gravitating recent literature in VisLang research and attempts to unearth directions that the field is heading towards.