 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCALAR: Learning and Composing Skills through LLM Guided Symbolic Planning and Deep RL Grounding
Mar 10, 2026LM-based agents excel when given high-level action APIs but struggle to ground language into low-level control. Prior work has LLMs generate skills or reward functions for RL, but these one-shot approaches lack feedback to correct specification errors. We introduce SCALAR, a bidirectional framework coupling LLM planning with RL through a learned skill library. The LLM proposes skills with preconditions and effects; RL trains policies for each skill and feeds back execution results to iteratively refine specifications, improving robustness to initial errors. Pivotal Trajectory Analysis corrects LLM priors by analyzing RL trajectories; Frontier Checkpointing optionally saves environment states at skill boundaries to improve sample efficiency. On Craftax, SCALAR achieves 88.2% diamond collection, a 1.9x improvement over the best baseline, and reaches the Gnomish Mines 9.1% of the time where prior methods fail entirely.
Overcoming Valid Action Suppression in Unmasked Policy Gradient Algorithms
Mar 10, 2026In reinforcement learning environments with state-dependent action validity, action masking consistently outperforms penalty-based handling of invalid actions, yet existing theory only shows that masking preserves the policy gradient theorem. We identify a distinct failure mode of unmasked training: it systematically suppresses valid actions at states the agent has not yet visited. This occurs because gradients pushing down invalid actions at visited states propagate through shared network parameters to unvisited states where those actions are valid. We prove that for softmax policies with shared features, when an action is invalid at visited states but valid at an unvisited state $s^*$, the probability $π(a \mid s^*)$ is bounded by exponential decay due to parameter sharing and the zero-sum identity of softmax logits. This bound reveals that entropy regularization trades off between protecting valid actions and sample efficiency, a tradeoff that masking eliminates. We validate empirically that deep networks exhibit the feature alignment condition required for suppression, and experiments on Craftax, Craftax-Classic, and MiniHack confirm the predicted exponential suppression and demonstrate that feasibility classification enables deployment without oracle masks.
Adaptively Coordinating with Novel Partners via Learned Latent Strategies
Nov 16, 2025Adaptation is the cornerstone of effective collaboration among heterogeneous team members. In human-agent teams, artificial agents need to adapt to their human partners in real time, as individuals often have unique preferences and policies that may change dynamically throughout interactions. This becomes particularly challenging in tasks with time pressure and complex strategic spaces, where identifying partner behaviors and selecting suitable responses is difficult. In this work, we introduce a strategy-conditioned cooperator framework that learns to represent, categorize, and adapt to a broad range of potential partner strategies in real-time. Our approach encodes strategies with a variational autoencoder to learn a latent strategy space from agent trajectory data, identifies distinct strategy types through clustering, and trains a cooperator agent conditioned on these clusters by generating partners of each strategy type. For online adaptation to novel partners, we leverage a fixed-share regret minimization algorithm that dynamically infers and adjusts the partner's strategy estimation during interaction. We evaluate our method in a modified version of the Overcooked domain, a complex collaborative cooking environment that requires effective coordination among two players with a diverse potential strategy space. Through these experiments and an online user study, we demonstrate that our proposed agent achieves state of the art performance compared to existing baselines when paired with novel human, and agent teammates.
Enhancing Safety of Foundation Models for Visual Navigation through Collision Avoidance via Repulsive Estimation
Jun 04, 2025We propose CARE (Collision Avoidance via Repulsive Estimation), a plug-and-play module that enhances the safety of vision-based navigation without requiring additional range sensors or fine-tuning of pretrained models. While recent foundation models using only RGB inputs have shown strong performance, they often fail to generalize in out-of-distribution (OOD) environments with unseen objects or variations in camera parameters (e.g., field of view, pose, or focal length). Without fine-tuning, these models may generate unsafe trajectories that lead to collisions, requiring costly data collection and retraining. CARE addresses this limitation by seamlessly integrating with any RGB-based navigation system that outputs local trajectories, dynamically adjusting them using repulsive force vectors derived from monocular depth maps. We evaluate CARE by combining it with state-of-the-art vision-based navigation models across multiple robot platforms. CARE consistently reduces collision rates (up to 100%) without sacrificing goal-reaching performance and improves collision-free travel distance by up to 10.7x in exploration tasks.
Distributed Multi-robot Source Seeking in Unknown Environments with Unknown Number of Sources
Mar 14, 2025We introduce a novel distributed source seeking framework, DIAS, designed for multi-robot systems in scenarios where the number of sources is unknown and potentially exceeds the number of robots. Traditional robotic source seeking methods typically focused on directing each robot to a specific strong source and may fall short in comprehensively identifying all potential sources. DIAS addresses this gap by introducing a hybrid controller that identifies the presence of sources and then alternates between exploration for data gathering and exploitation for guiding robots to identified sources. It further enhances search efficiency by dividing the environment into Voronoi cells and approximating source density functions based on Gaussian process regression. Additionally, DIAS can be integrated with existing source seeking algorithms. We compare DIAS with existing algorithms, including DoSS and GMES in simulated gas leakage scenarios where the number of sources outnumbers or is equal to the number of robots. The numerical results show that DIAS outperforms the baseline methods in both the efficiency of source identification by the robots and the accuracy of the estimated environmental density function.
B3C: A Minimalist Approach to Offline Multi-Agent Reinforcement Learning
Jan 30, 2025



Overestimation arising from selecting unseen actions during policy evaluation is a major challenge in offline reinforcement learning (RL). A minimalist approach in the single-agent setting -- adding behavior cloning (BC) regularization to existing online RL algorithms -- has been shown to be effective; however, this approach is understudied in multi-agent settings. In particular, overestimation becomes worse in multi-agent settings due to the presence of multiple actions, resulting in the BC regularization-based approach easily suffering from either over-regularization or critic divergence. To address this, we propose a simple yet effective method, Behavior Cloning regularization with Critic Clipping (B3C), which clips the target critic value in policy evaluation based on the maximum return in the dataset and pushes the limit of the weight on the RL objective over BC regularization, thereby improving performance. Additionally, we leverage existing value factorization techniques, particularly non-linear factorization, which is understudied in offline settings. Integrated with non-linear value factorization, B3C outperforms state-of-the-art algorithms on various offline multi-agent benchmarks.
HiMemFormer: Hierarchical Memory-Aware Transformer for Multi-Agent Action Anticipation
Nov 03, 2024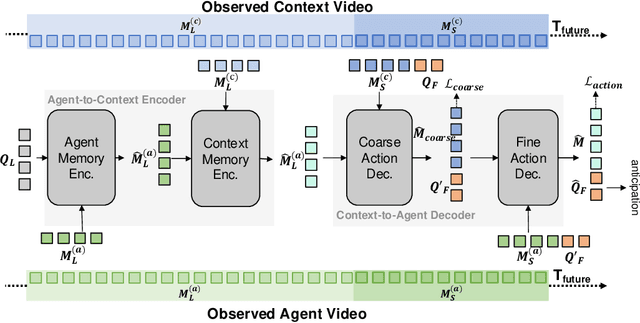
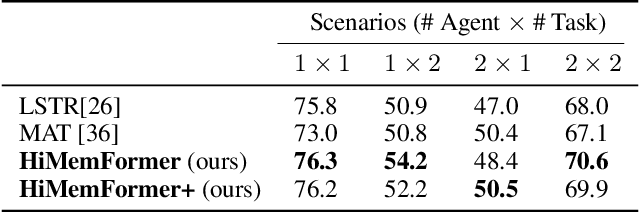

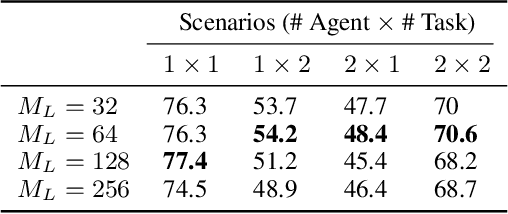
Understanding and predicting human actions has been a long-standing challenge and is a crucial measure of perception in robotics AI. While significant progress has been made in anticipating the future actions of individual agents, prior work has largely overlooked a key aspect of real-world human activity -- interactions. To address this gap in human-like forecasting within multi-agent environments, we present the Hierarchical Memory-Aware Transformer (HiMemFormer), a transformer-based model for online multi-agent action anticipation. HiMemFormer integrates and distributes global memory that captures joint historical information across all agents through a transformer framework, with a hierarchical local memory decoder that interprets agent-specific features based on these global representations using a coarse-to-fine strategy. In contrast to previous approaches, HiMemFormer uniquely hierarchically applies the global context with agent-specific preferences to avoid noisy or redundant information in multi-agent action anticipation. Extensive experiments on various multi-agent scenarios demonstrate the significant performance of HiMemFormer, compared with other state-of-the-art methods.
DyPNIPP: Predicting Environment Dynamics for RL-based Robust Informative Path Planning
Oct 22, 2024



Informative path planning (IPP) is an important planning paradigm for various real-world robotic applications such as environment monitoring. IPP involves planning a path that can learn an accurate belief of the quantity of interest, while adhering to planning constraints. Traditional IPP methods typically require high computation time during execution, giving rise to reinforcement learning (RL) based IPP methods. However, the existing RL-based methods do not consider spatio-temporal environments which involve their own challenges due to variations in environment characteristics. In this paper, we propose DyPNIPP, a robust RL-based IPP framework, designed to operate effectively across spatio-temporal environments with varying dynamics. To achieve this, DyPNIPP incorporates domain randomization to train the agent across diverse environments and introduces a dynamics prediction model to capture and adapt the agent actions to specific environment dynamics. Our extensive experiments in a wildfire environment demonstrate that DyPNIPP outperforms existing RL-based IPP algorithms by significantly improving robustness and performing across diverse environment conditions.
OffRIPP: Offline RL-based Informative Path Planning
Sep 25, 2024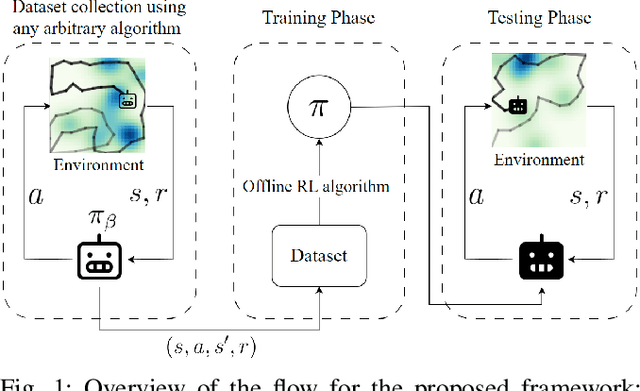
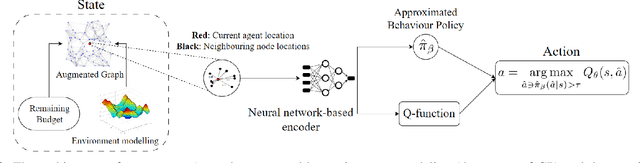
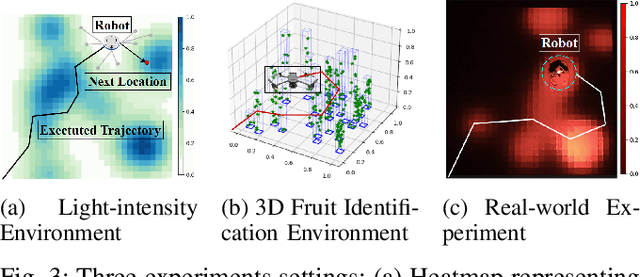
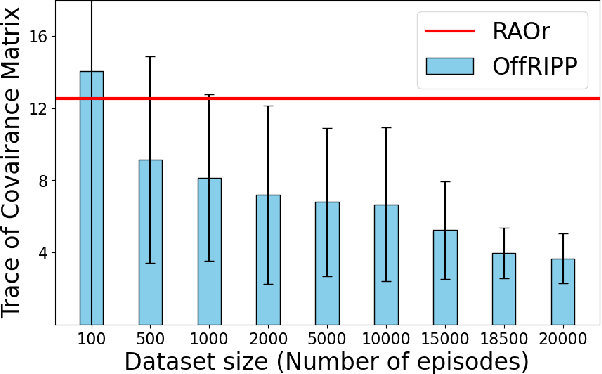
Informative path planning (IPP) is a crucial task in robotics, where agents must design paths to gather valuable information about a target environment while adhering to resource constraints. Reinforcement learning (RL) has been shown to be effective for IPP, however, it requires environment interactions, which are risky and expensive in practice. To address this problem, we propose an offline RL-based IPP framework that optimizes information gain without requiring real-time interaction during training, offering safety and cost-efficiency by avoiding interaction, as well as superior performance and fast computation during execution -- key advantages of RL. Our framework leverages batch-constrained reinforcement learning to mitigate extrapolation errors, enabling the agent to learn from pre-collected datasets generated by arbitrary algorithms. We validate the framework through extensive simulations and real-world experiments. The numerical results show that our framework outperforms the baselines, demonstrating the effectiveness of the proposed approach.
Escaping Local Minima: Hybrid Artificial Potential Field with Wall-Follower for Decentralized Multi-Robot Navigation
Sep 16, 2024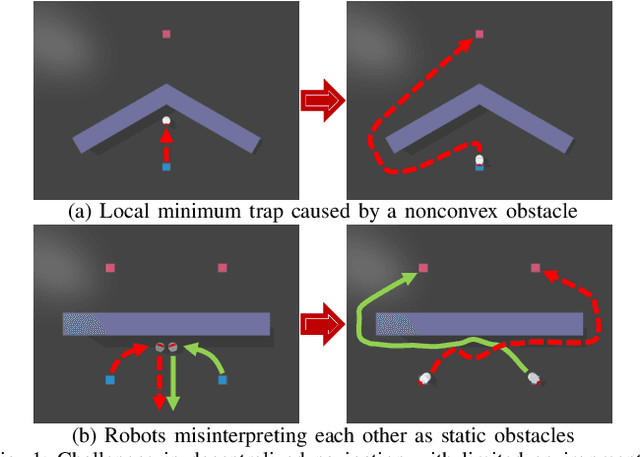
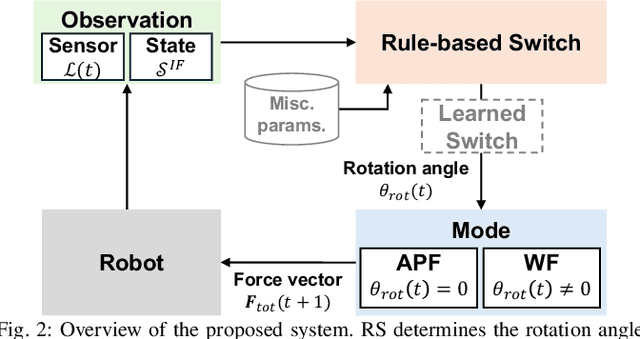

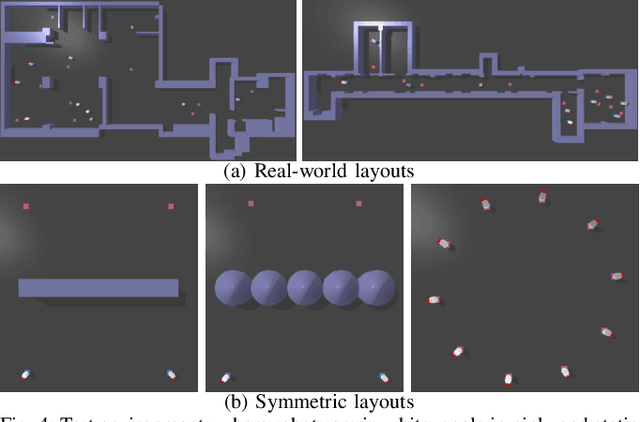
We tackle the challenges of decentralized multi-robot navigation in environments with nonconvex obstacles, where complete environmental knowledge is unavailable. While reactive methods like Artificial Potential Field (APF) offer simplicity and efficiency, they suffer from local minima, causing robots to become trapped due to their lack of global environmental awareness. Other existing solutions either rely on inter-robot communication, are limited to single-robot scenarios, or struggle to overcome nonconvex obstacles effectively. Our proposed methods enable collision-free navigation using only local sensor and state information without a map. By incorporating a wall-following (WF) behavior into the APF approach, our method allows robots to escape local minima, even in the presence of nonconvex and dynamic obstacles including other robots. We introduce two algorithms for switching between APF and WF: a rule-based system and an encoder network trained on expert demonstrations. Experimental results show that our approach achieves substantially higher success rates compared to state-of-the-art methods, highlighting its ability to overcome the limitations of local minima in complex environments