 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Invariant Per-Frame Feature Extraction for Cross-Domain Imitation Learning with Visual Observations
Feb 05, 2025Imitation learning (IL) enables agents to mimic expert behavior without reward signals but faces challenges in cross-domain scenarios with high-dimensional, noisy, and incomplete visual observations. To address this, we propose Domain-Invariant Per-Frame Feature Extraction for Imitation Learning (DIFF-IL), a novel IL method that extracts domain-invariant features from individual frames and adapts them into sequences to isolate and replicate expert behaviors. We also introduce a frame-wise time labeling technique to segment expert behaviors by timesteps and assign rewards aligned with temporal contexts, enhancing task performance. Experiments across diverse visual environments demonstrate the effectiveness of DIFF-IL in addressing complex visual tasks.
Domain Adaptive Imitation Learning with Visual Observation
Dec 01, 2023In this paper, we consider domain-adaptive imitation learning with visual observation, where an agent in a target domain learns to perform a task by observing expert demonstrations in a source domain. Domain adaptive imitation learning arises in practical scenarios where a robot, receiving visual sensory data, needs to mimic movements by visually observing other robots from different angles or observing robots of different shapes. To overcome the domain shift in cross-domain imitation learning with visual observation, we propose a novel framework for extracting domain-independent behavioral features from input observations that can be used to train the learner, based on dual feature extraction and image reconstruction. Empirical results demonstrate that our approach outperforms previous algorithms for imitation learning from visual observation with domain shift.
Robust Imitation Learning against Variations in Environment Dynamics
Jun 19, 2022
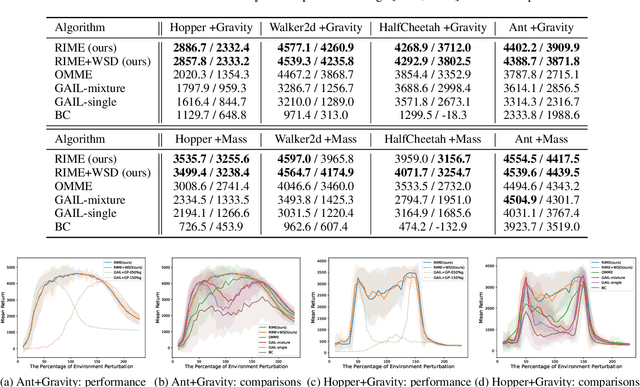
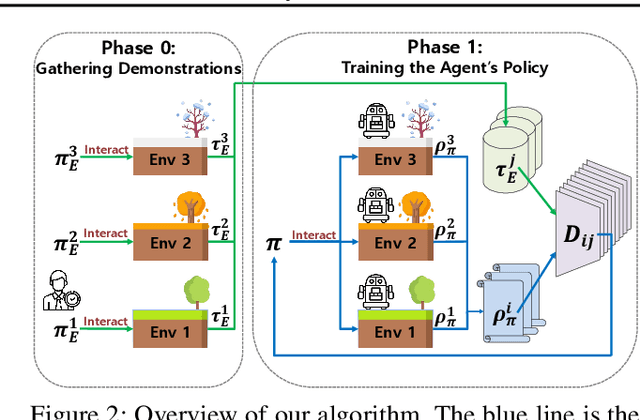
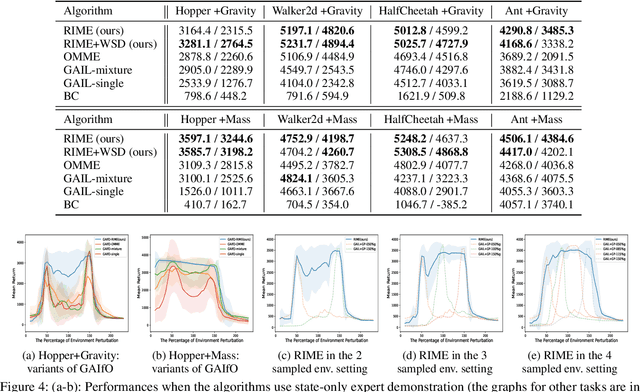
In this paper, we propose a robust imitation learning (IL) framework that improves the robustness of IL when environment dynamics are perturbed. The existing IL framework trained in a single environment can catastrophically fail with perturbations in environment dynamics because it does not capture the situation that underlying environment dynamics can be changed. Our framework effectively deals with environments with varying dynamics by imitating multiple experts in sampled environment dynamics to enhance the robustness in general variations in environment dynamics. In order to robustly imitate the multiple sample experts, we minimize the risk with respect to the Jensen-Shannon divergence between the agent's policy and each of the sample experts. Numerical results show that our algorithm significantly improves robustness against dynamics perturbations compared to conventional IL baselines.
Blockwise Sequential Model Learning for Partially Observable Reinforcement Learning
Dec 10, 2021

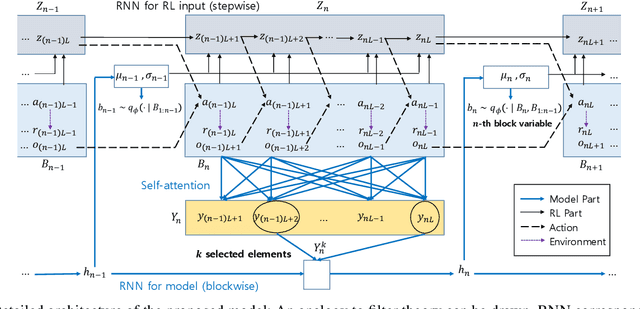
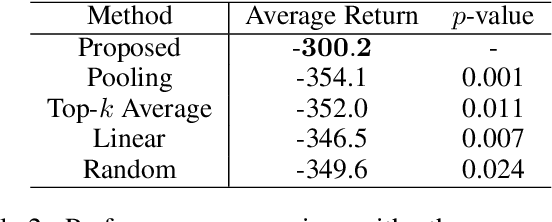
This paper proposes a new sequential model learning architecture to solve partially observable Markov decision problems. Rather than compressing sequential information at every timestep as in conventional recurrent neural network-based methods, the proposed architecture generates a latent variable in each data block with a length of multiple timesteps and passes the most relevant information to the next block for policy optimization. The proposed blockwise sequential model is implemented based on self-attention, making the model capable of detailed sequential learning in partial observable settings. The proposed model builds an additional learning network to efficiently implement gradient estimation by using self-normalized importance sampling, which does not require the complex blockwise input data reconstruction in the model learning. Numerical results show that the proposed method significantly outperforms previous methods in various partially observable environments.
Cross-Domain Imitation Learning with a Dual Structure
Jun 04, 2020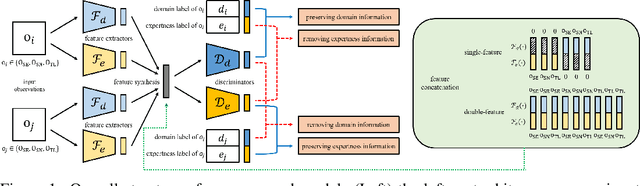
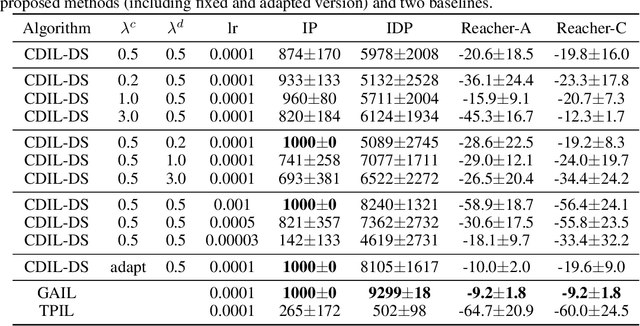
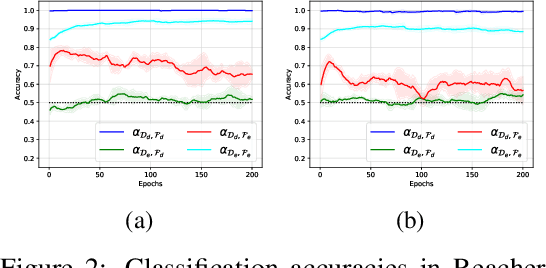
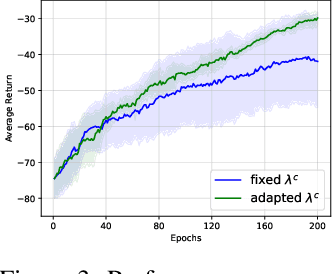
In this paper, we consider cross-domain imitation learning (CDIL) in which an agent in a target domain learns a policy to perform well in the target domain by observing expert demonstrations in a source domain without accessing any reward function. In order to overcome the domain difference for imitation learning, we propose a dual-structured learning method. The proposed learning method extracts two feature vectors from each input observation such that one vector contains domain information and the other vector contains policy expertness information, and then enhances feature vectors by synthesizing new feature vectors containing both target-domain and policy expertness information. The proposed CDIL method is tested on several MuJoCo tasks where the domain difference is determined by image angles or colors. Numerical results show that the proposed method shows superior performance in CDIL to other existing algorithms and achieves almost the same performance as imitation learning without domain difference.