 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlockwise Sequential Model Learning for Partially Observable Reinforcement Learning
Paper and Code


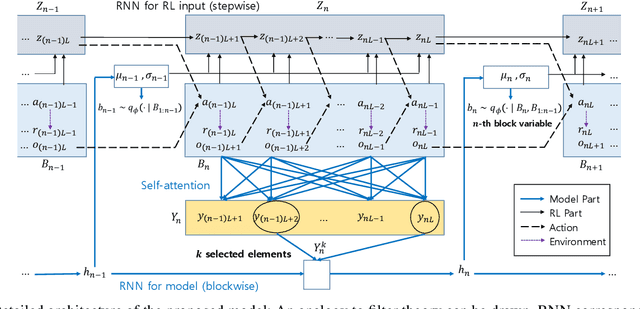
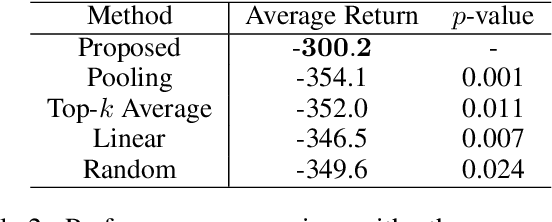
This paper proposes a new sequential model learning architecture to solve partially observable Markov decision problems. Rather than compressing sequential information at every timestep as in conventional recurrent neural network-based methods, the proposed architecture generates a latent variable in each data block with a length of multiple timesteps and passes the most relevant information to the next block for policy optimization. The proposed blockwise sequential model is implemented based on self-attention, making the model capable of detailed sequential learning in partial observable settings. The proposed model builds an additional learning network to efficiently implement gradient estimation by using self-normalized importance sampling, which does not require the complex blockwise input data reconstruction in the model learning. Numerical results show that the proposed method significantly outperforms previous methods in various partially observable environments.