 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Dimension Reduction for Scalable Multi-Objective Reinforcement Learning
Feb 28, 2025In this paper, we introduce a simple yet effective reward dimension reduction method to tackle the scalability challenges of multi-objective reinforcement learning algorithms. While most existing approaches focus on optimizing two to four objectives, their abilities to scale to environments with more objectives remain uncertain. Our method uses a dimension reduction approach to enhance learning efficiency and policy performance in multi-objective settings. While most traditional dimension reduction methods are designed for static datasets, our approach is tailored for online learning and preserves Pareto-optimality after transformation. We propose a new training and evaluation framework for reward dimension reduction in multi-objective reinforcement learning and demonstrate the superiority of our method in environments including one with sixteen objectives, significantly outperforming existing online dimension reduction methods.
The Max-Min Formulation of Multi-Objective Reinforcement Learning: From Theory to a Model-Free Algorithm
Jun 12, 2024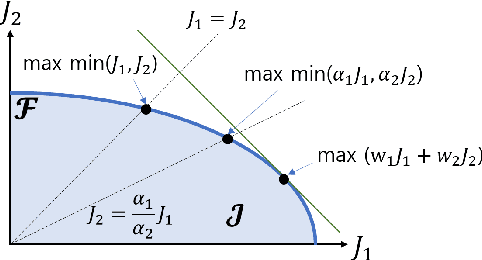
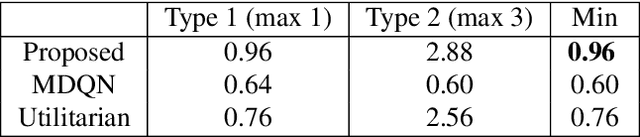
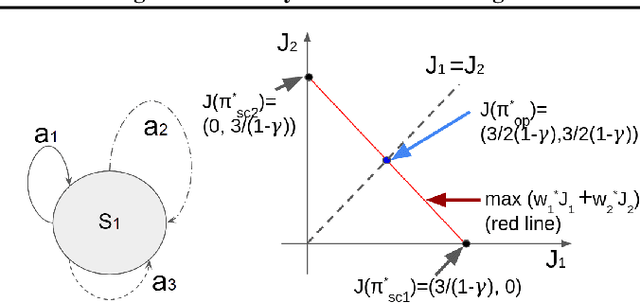
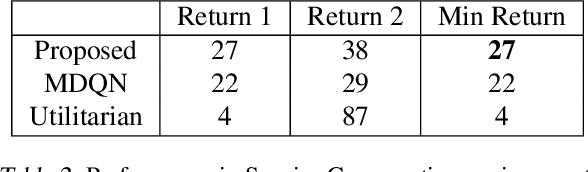
In this paper, we consider multi-objective reinforcement learning, which arises in many real-world problems with multiple optimization goals. We approach the problem with a max-min framework focusing on fairness among the multiple goals and develop a relevant theory and a practical model-free algorithm under the max-min framework. The developed theory provides a theoretical advance in multi-objective reinforcement learning, and the proposed algorithm demonstrates a notable performance improvement over existing baseline methods.
Blockwise Sequential Model Learning for Partially Observable Reinforcement Learning
Dec 10, 2021

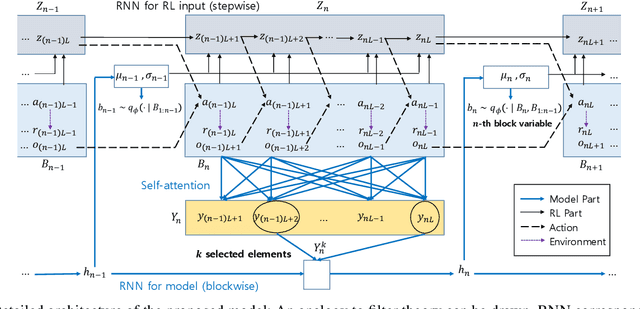
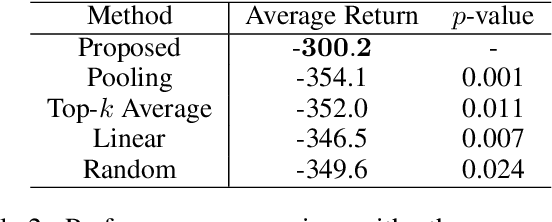
This paper proposes a new sequential model learning architecture to solve partially observable Markov decision problems. Rather than compressing sequential information at every timestep as in conventional recurrent neural network-based methods, the proposed architecture generates a latent variable in each data block with a length of multiple timesteps and passes the most relevant information to the next block for policy optimization. The proposed blockwise sequential model is implemented based on self-attention, making the model capable of detailed sequential learning in partial observable settings. The proposed model builds an additional learning network to efficiently implement gradient estimation by using self-normalized importance sampling, which does not require the complex blockwise input data reconstruction in the model learning. Numerical results show that the proposed method significantly outperforms previous methods in various partially observable environments.
Population-Guided Parallel Policy Search for Reinforcement Learning
Jan 09, 2020



In this paper, a new population-guided parallel learning scheme is proposed to enhance the performance of off-policy reinforcement learning (RL). In the proposed scheme, multiple identical learners with their own value-functions and policies share a common experience replay buffer, and search a good policy in collaboration with the guidance of the best policy information. The key point is that the information of the best policy is fused in a soft manner by constructing an augmented loss function for policy update to enlarge the overall search region by the multiple learners. The guidance by the previous best policy and the enlarged range enable faster and better policy search. Monotone improvement of the expected cumulative return by the proposed scheme is proved theoretically. Working algorithms are constructed by applying the proposed scheme to the twin delayed deep deterministic (TD3) policy gradient algorithm. Numerical results show that the constructed algorithm outperforms most of the current state-of-the-art RL algorithms, and the gain is significant in the case of sparse reward environment.