 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptive Imitation Learning with Visual Observation
Dec 01, 2023In this paper, we consider domain-adaptive imitation learning with visual observation, where an agent in a target domain learns to perform a task by observing expert demonstrations in a source domain. Domain adaptive imitation learning arises in practical scenarios where a robot, receiving visual sensory data, needs to mimic movements by visually observing other robots from different angles or observing robots of different shapes. To overcome the domain shift in cross-domain imitation learning with visual observation, we propose a novel framework for extracting domain-independent behavioral features from input observations that can be used to train the learner, based on dual feature extraction and image reconstruction. Empirical results demonstrate that our approach outperforms previous algorithms for imitation learning from visual observation with domain shift.
A Variational Approach to Mutual Information-Based Coordination for Multi-Agent Reinforcement Learning
Mar 01, 2023In this paper, we propose a new mutual information framework for multi-agent reinforcement learning to enable multiple agents to learn coordinated behaviors by regularizing the accumulated return with the simultaneous mutual information between multi-agent actions. By introducing a latent variable to induce nonzero mutual information between multi-agent actions and applying a variational bound, we derive a tractable lower bound on the considered MMI-regularized objective function. The derived tractable objective can be interpreted as maximum entropy reinforcement learning combined with uncertainty reduction of other agents actions. Applying policy iteration to maximize the derived lower bound, we propose a practical algorithm named variational maximum mutual information multi-agent actor-critic, which follows centralized learning with decentralized execution. We evaluated VM3-AC for several games requiring coordination, and numerical results show that VM3-AC outperforms other MARL algorithms in multi-agent tasks requiring high-quality coordination.
Quantile Constrained Reinforcement Learning: A Reinforcement Learning Framework Constraining Outage Probability
Nov 28, 2022Constrained reinforcement learning (RL) is an area of RL whose objective is to find an optimal policy that maximizes expected cumulative return while satisfying a given constraint. Most of the previous constrained RL works consider expected cumulative sum cost as the constraint. However, optimization with this constraint cannot guarantee a target probability of outage event that the cumulative sum cost exceeds a given threshold. This paper proposes a framework, named Quantile Constrained RL (QCRL), to constrain the quantile of the distribution of the cumulative sum cost that is a necessary and sufficient condition to satisfy the outage constraint. This is the first work that tackles the issue of applying the policy gradient theorem to the quantile and provides theoretical results for approximating the gradient of the quantile. Based on the derived theoretical results and the technique of the Lagrange multiplier, we construct a constrained RL algorithm named Quantile Constrained Policy Optimization (QCPO). We use distributional RL with the Large Deviation Principle (LDP) to estimate quantiles and tail probability of the cumulative sum cost for the implementation of QCPO. The implemented algorithm satisfies the outage probability constraint after the training period.
MASER: Multi-Agent Reinforcement Learning with Subgoals Generated from Experience Replay Buffer
Jun 20, 2022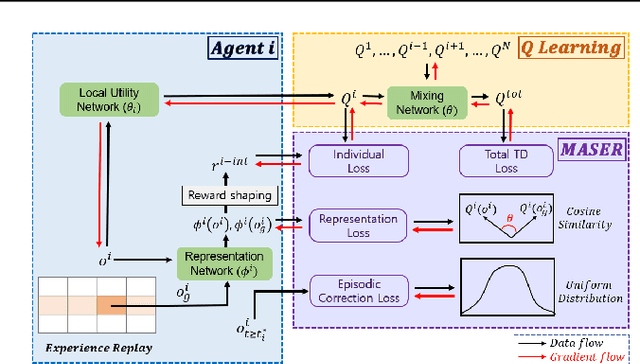



In this paper, we consider cooperative multi-agent reinforcement learning (MARL) with sparse reward. To tackle this problem, we propose a novel method named MASER: MARL with subgoals generated from experience replay buffer. Under the widely-used assumption of centralized training with decentralized execution and consistent Q-value decomposition for MARL, MASER automatically generates proper subgoals for multiple agents from the experience replay buffer by considering both individual Q-value and total Q-value. Then, MASER designs individual intrinsic reward for each agent based on actionable representation relevant to Q-learning so that the agents reach their subgoals while maximizing the joint action value. Numerical results show that MASER significantly outperforms StarCraft II micromanagement benchmark compared to other state-of-the-art MARL algorithms.
Robust Imitation Learning against Variations in Environment Dynamics
Jun 19, 2022
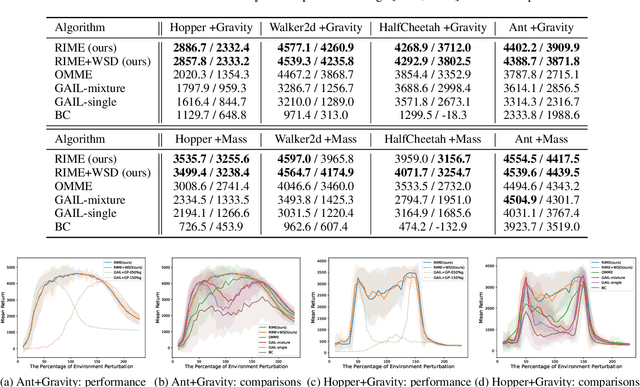
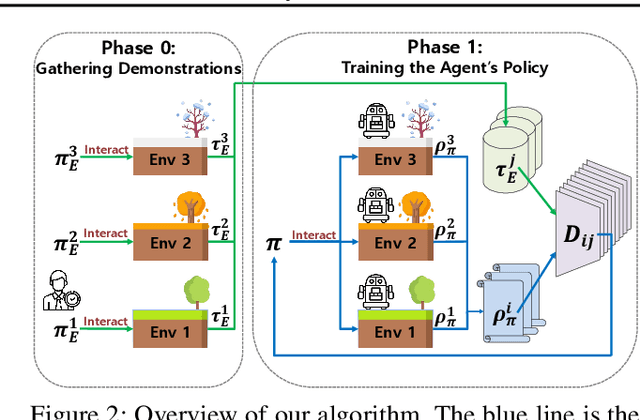
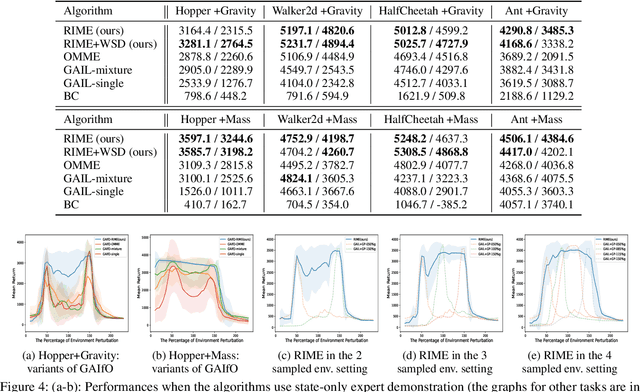
In this paper, we propose a robust imitation learning (IL) framework that improves the robustness of IL when environment dynamics are perturbed. The existing IL framework trained in a single environment can catastrophically fail with perturbations in environment dynamics because it does not capture the situation that underlying environment dynamics can be changed. Our framework effectively deals with environments with varying dynamics by imitating multiple experts in sampled environment dynamics to enhance the robustness in general variations in environment dynamics. In order to robustly imitate the multiple sample experts, we minimize the risk with respect to the Jensen-Shannon divergence between the agent's policy and each of the sample experts. Numerical results show that our algorithm significantly improves robustness against dynamics perturbations compared to conventional IL baselines.
Population-Guided Parallel Policy Search for Reinforcement Learning
Jan 09, 2020



In this paper, a new population-guided parallel learning scheme is proposed to enhance the performance of off-policy reinforcement learning (RL). In the proposed scheme, multiple identical learners with their own value-functions and policies share a common experience replay buffer, and search a good policy in collaboration with the guidance of the best policy information. The key point is that the information of the best policy is fused in a soft manner by constructing an augmented loss function for policy update to enlarge the overall search region by the multiple learners. The guidance by the previous best policy and the enlarged range enable faster and better policy search. Monotone improvement of the expected cumulative return by the proposed scheme is proved theoretically. Working algorithms are constructed by applying the proposed scheme to the twin delayed deep deterministic (TD3) policy gradient algorithm. Numerical results show that the constructed algorithm outperforms most of the current state-of-the-art RL algorithms, and the gain is significant in the case of sparse reward environment.