 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetaining Suboptimal Actions to Follow Shifting Optima in Multi-Agent Reinforcement Learning
Feb 19, 2026Value decomposition is a core approach for cooperative multi-agent reinforcement learning (MARL). However, existing methods still rely on a single optimal action and struggle to adapt when the underlying value function shifts during training, often converging to suboptimal policies. To address this limitation, we propose Successive Sub-value Q-learning (S2Q), which learns multiple sub-value functions to retain alternative high-value actions. Incorporating these sub-value functions into a Softmax-based behavior policy, S2Q encourages persistent exploration and enables $Q^{\text{tot}}$ to adjust quickly to the changing optima. Experiments on challenging MARL benchmarks confirm that S2Q consistently outperforms various MARL algorithms, demonstrating improved adaptability and overall performance. Our code is available at https://github.com/hyeon1996/S2Q.
Strict Subgoal Execution: Reliable Long-Horizon Planning in Hierarchical Reinforcement Learning
Jun 26, 2025Long-horizon goal-conditioned tasks pose fundamental challenges for reinforcement learning (RL), particularly when goals are distant and rewards are sparse. While hierarchical and graph-based methods offer partial solutions, they often suffer from subgoal infeasibility and inefficient planning. We introduce Strict Subgoal Execution (SSE), a graph-based hierarchical RL framework that enforces single-step subgoal reachability by structurally constraining high-level decision-making. To enhance exploration, SSE employs a decoupled exploration policy that systematically traverses underexplored regions of the goal space. Furthermore, a failure-aware path refinement, which refines graph-based planning by dynamically adjusting edge costs according to observed low-level success rates, thereby improving subgoal reliability. Experimental results across diverse long-horizon benchmarks demonstrate that SSE consistently outperforms existing goal-conditioned RL and hierarchical RL approaches in both efficiency and success rate.
Center of Gravity-Guided Focusing Influence Mechanism for Multi-Agent Reinforcement Learning
Jun 24, 2025



Cooperative multi-agent reinforcement learning (MARL) under sparse rewards presents a fundamental challenge due to limited exploration and insufficient coordinated attention among agents. In this work, we propose the Focusing Influence Mechanism (FIM), a novel framework that enhances cooperation by directing agent influence toward task-critical elements, referred to as Center of Gravity (CoG) state dimensions, inspired by Clausewitz's military theory. FIM consists of three core components: (1) identifying CoG state dimensions based on their stability under agent behavior, (2) designing counterfactual intrinsic rewards to promote meaningful influence on these dimensions, and (3) encouraging persistent and synchronized focus through eligibility-trace-based credit accumulation. These mechanisms enable agents to induce more targeted and effective state transitions, facilitating robust cooperation even in extremely sparse reward settings. Empirical evaluations across diverse MARL benchmarks demonstrate that the proposed FIM significantly improves cooperative performance compared to baselines.
PRISM: A Robust Framework for Skill-based Meta-Reinforcement Learning with Noisy Demonstrations
Feb 06, 2025



Meta-reinforcement learning (Meta-RL) facilitates rapid adaptation to unseen tasks but faces challenges in long-horizon environments. Skill-based approaches tackle this by decomposing state-action sequences into reusable skills and employing hierarchical decision-making. However, these methods are highly susceptible to noisy offline demonstrations, resulting in unstable skill learning and degraded performance. To overcome this, we propose Prioritized Refinement for Skill-Based Meta-RL (PRISM), a robust framework that integrates exploration near noisy data to generate online trajectories and combines them with offline data. Through prioritization, PRISM extracts high-quality data to learn task-relevant skills effectively. By addressing the impact of noise, our method ensures stable skill learning and achieves superior performance in long-horizon tasks, even with noisy and sub-optimal data.
Wolfpack Adversarial Attack for Robust Multi-Agent Reinforcement Learning
Feb 05, 2025



Traditional robust methods in multi-agent reinforcement learning (MARL) often struggle against coordinated adversarial attacks in cooperative scenarios. To address this limitation, we propose the Wolfpack Adversarial Attack framework, inspired by wolf hunting strategies, which targets an initial agent and its assisting agents to disrupt cooperation. Additionally, we introduce the Wolfpack-Adversarial Learning for MARL (WALL) framework, which trains robust MARL policies to defend against the proposed Wolfpack attack by fostering system-wide collaboration. Experimental results underscore the devastating impact of the Wolfpack attack and the significant robustness improvements achieved by WALL.
Domain-Invariant Per-Frame Feature Extraction for Cross-Domain Imitation Learning with Visual Observations
Feb 05, 2025Imitation learning (IL) enables agents to mimic expert behavior without reward signals but faces challenges in cross-domain scenarios with high-dimensional, noisy, and incomplete visual observations. To address this, we propose Domain-Invariant Per-Frame Feature Extraction for Imitation Learning (DIFF-IL), a novel IL method that extracts domain-invariant features from individual frames and adapts them into sequences to isolate and replicate expert behaviors. We also introduce a frame-wise time labeling technique to segment expert behaviors by timesteps and assign rewards aligned with temporal contexts, enhancing task performance. Experiments across diverse visual environments demonstrate the effectiveness of DIFF-IL in addressing complex visual tasks.
Task-Aware Virtual Training: Enhancing Generalization in Meta-Reinforcement Learning for Out-of-Distribution Tasks
Feb 05, 2025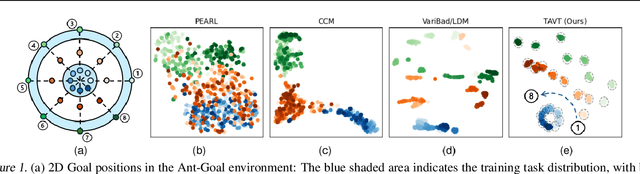
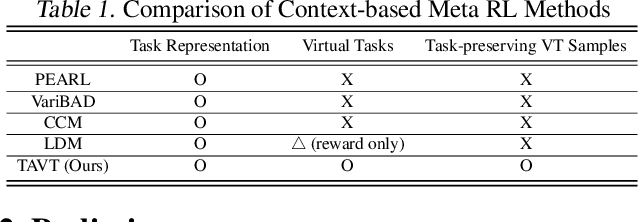
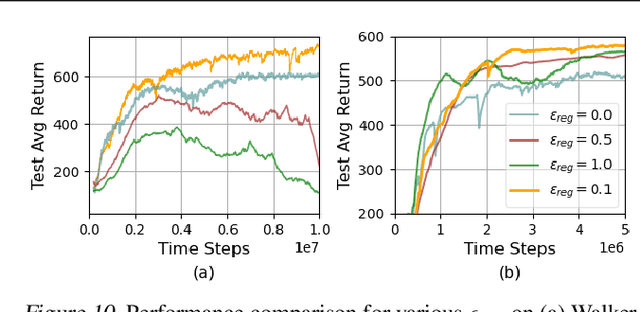
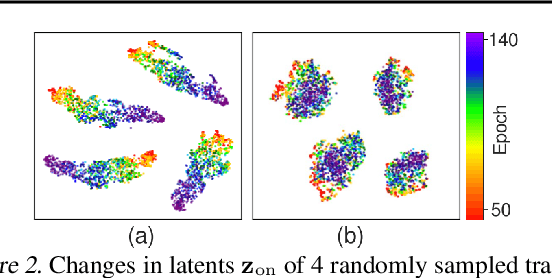
Meta reinforcement learning aims to develop policies that generalize to unseen tasks sampled from a task distribution. While context-based meta-RL methods improve task representation using task latents, they often struggle with out-of-distribution (OOD) tasks. To address this, we propose Task-Aware Virtual Training (TAVT), a novel algorithm that accurately captures task characteristics for both training and OOD scenarios using metric-based representation learning. Our method successfully preserves task characteristics in virtual tasks and employs a state regularization technique to mitigate overestimation errors in state-varying environments. Numerical results demonstrate that TAVT significantly enhances generalization to OOD tasks across various MuJoCo and MetaWorld environments.
Exclusively Penalized Q-learning for Offline Reinforcement Learning
May 23, 2024



Constraint-based offline reinforcement learning (RL) involves policy constraints or imposing penalties on the value function to mitigate overestimation errors caused by distributional shift. This paper focuses on a limitation in existing offline RL methods with penalized value function, indicating the potential for underestimation bias due to unnecessary bias introduced in the value function. To address this concern, we propose Exclusively Penalized Q-learning (EPQ), which reduces estimation bias in the value function by selectively penalizing states that are prone to inducing estimation errors. Numerical results show that our method significantly reduces underestimation bias and improves performance in various offline control tasks compared to other offline RL methods
Domain Adaptive Imitation Learning with Visual Observation
Dec 01, 2023In this paper, we consider domain-adaptive imitation learning with visual observation, where an agent in a target domain learns to perform a task by observing expert demonstrations in a source domain. Domain adaptive imitation learning arises in practical scenarios where a robot, receiving visual sensory data, needs to mimic movements by visually observing other robots from different angles or observing robots of different shapes. To overcome the domain shift in cross-domain imitation learning with visual observation, we propose a novel framework for extracting domain-independent behavioral features from input observations that can be used to train the learner, based on dual feature extraction and image reconstruction. Empirical results demonstrate that our approach outperforms previous algorithms for imitation learning from visual observation with domain shift.
FoX: Formation-aware exploration in multi-agent reinforcement learning
Aug 22, 2023



Recently, deep multi-agent reinforcement learning (MARL) has gained significant popularity due to its success in various cooperative multi-agent tasks. However, exploration still remains a challenging problem in MARL due to the partial observability of the agents and the exploration space that can grow exponentially as the number of agents increases. Firstly, in order to address the scalability issue of the exploration space, we define a formation-based equivalence relation on the exploration space and aim to reduce the search space by exploring only meaningful states in different formations. Then, we propose a novel formation-aware exploration (FoX) framework that encourages partially observable agents to visit the states in diverse formations by guiding them to be well aware of their current formation solely based on their own observations. Numerical results show that the proposed FoX framework significantly outperforms the state-of-the-art MARL algorithms on Google Research Football (GRF) and sparse Starcraft II multi-agent challenge (SMAC) tasks.