 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAIRS-Former: Spatio-Temporal Attention with Interleaved Recursive Structure Transformer for Offline Multi-task Multi-agent Reinforcement Learning
Mar 12, 2026Offline multi-agent reinforcement learning (MARL) with multi-task datasets is challenging due to varying numbers of agents across tasks and the need to generalize to unseen scenarios. Prior works employ transformers with observation tokenization and hierarchical skill learning to address these issues. However, they underutilize the transformer attention mechanism for inter-agent coordination and rely on a single history token, which limits their ability to capture long-horizon temporal dependencies in partially observable MARL settings. In this paper, we propose STAIRS-Former, a transformer architecture augmented with spatial and temporal hierarchies that enables effective attention over critical tokens while capturing long interaction histories. We further introduce token dropout to enhance robustness and generalization across varying agent populations. Extensive experiments on diverse multi-agent benchmarks, including SMAC, SMAC-v2, MPE, and MaMuJoCo, with multi-task datasets demonstrate that STAIRS-Former consistently outperforms prior methods and achieves new state-of-the-art performance.
A Variational Approach to Mutual Information-Based Coordination for Multi-Agent Reinforcement Learning
Mar 01, 2023In this paper, we propose a new mutual information framework for multi-agent reinforcement learning to enable multiple agents to learn coordinated behaviors by regularizing the accumulated return with the simultaneous mutual information between multi-agent actions. By introducing a latent variable to induce nonzero mutual information between multi-agent actions and applying a variational bound, we derive a tractable lower bound on the considered MMI-regularized objective function. The derived tractable objective can be interpreted as maximum entropy reinforcement learning combined with uncertainty reduction of other agents actions. Applying policy iteration to maximize the derived lower bound, we propose a practical algorithm named variational maximum mutual information multi-agent actor-critic, which follows centralized learning with decentralized execution. We evaluated VM3-AC for several games requiring coordination, and numerical results show that VM3-AC outperforms other MARL algorithms in multi-agent tasks requiring high-quality coordination.
Quantile Constrained Reinforcement Learning: A Reinforcement Learning Framework Constraining Outage Probability
Nov 28, 2022Constrained reinforcement learning (RL) is an area of RL whose objective is to find an optimal policy that maximizes expected cumulative return while satisfying a given constraint. Most of the previous constrained RL works consider expected cumulative sum cost as the constraint. However, optimization with this constraint cannot guarantee a target probability of outage event that the cumulative sum cost exceeds a given threshold. This paper proposes a framework, named Quantile Constrained RL (QCRL), to constrain the quantile of the distribution of the cumulative sum cost that is a necessary and sufficient condition to satisfy the outage constraint. This is the first work that tackles the issue of applying the policy gradient theorem to the quantile and provides theoretical results for approximating the gradient of the quantile. Based on the derived theoretical results and the technique of the Lagrange multiplier, we construct a constrained RL algorithm named Quantile Constrained Policy Optimization (QCPO). We use distributional RL with the Large Deviation Principle (LDP) to estimate quantiles and tail probability of the cumulative sum cost for the implementation of QCPO. The implemented algorithm satisfies the outage probability constraint after the training period.
Robust Imitation Learning against Variations in Environment Dynamics
Jun 19, 2022
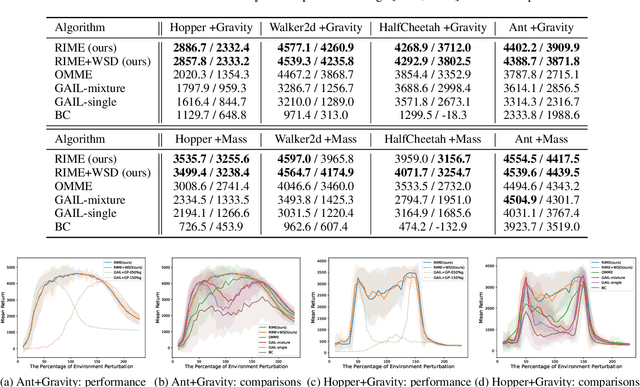
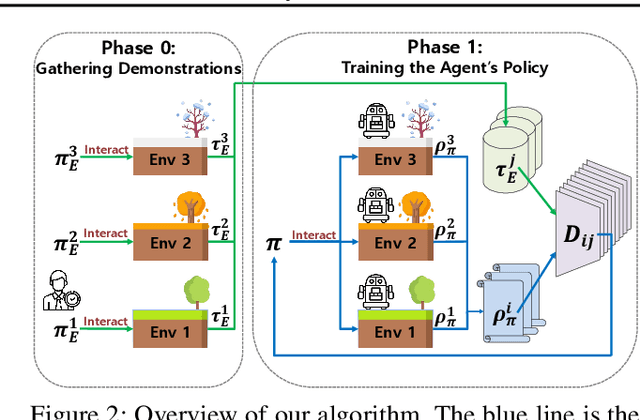
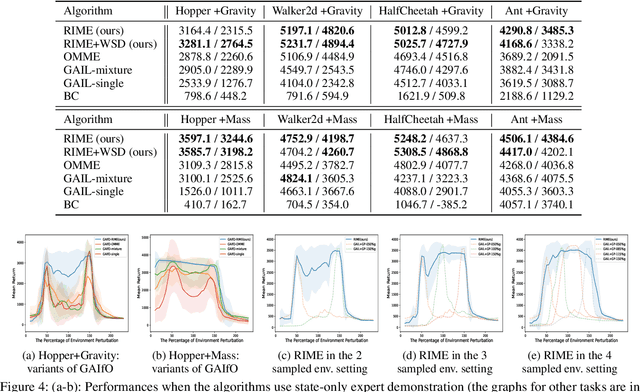
In this paper, we propose a robust imitation learning (IL) framework that improves the robustness of IL when environment dynamics are perturbed. The existing IL framework trained in a single environment can catastrophically fail with perturbations in environment dynamics because it does not capture the situation that underlying environment dynamics can be changed. Our framework effectively deals with environments with varying dynamics by imitating multiple experts in sampled environment dynamics to enhance the robustness in general variations in environment dynamics. In order to robustly imitate the multiple sample experts, we minimize the risk with respect to the Jensen-Shannon divergence between the agent's policy and each of the sample experts. Numerical results show that our algorithm significantly improves robustness against dynamics perturbations compared to conventional IL baselines.
Message-Dropout: An Efficient Training Method for Multi-Agent Deep Reinforcement Learning
Feb 18, 2019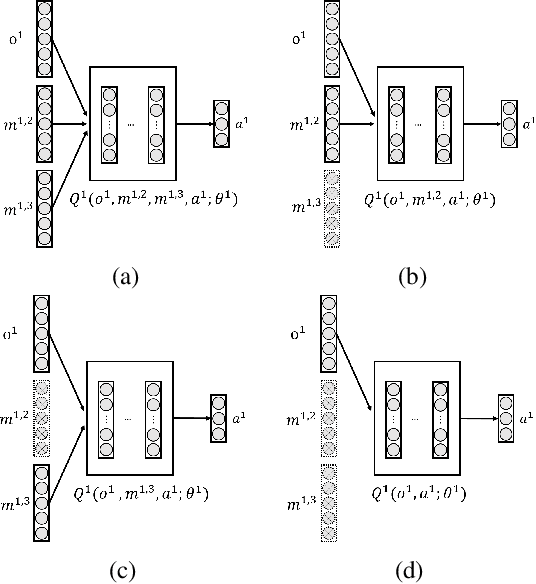
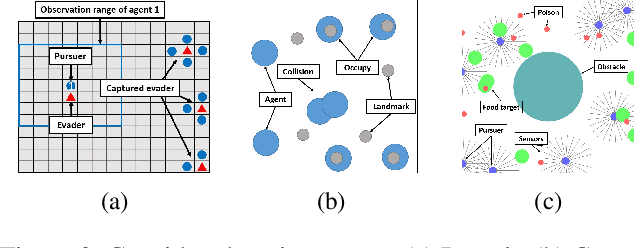

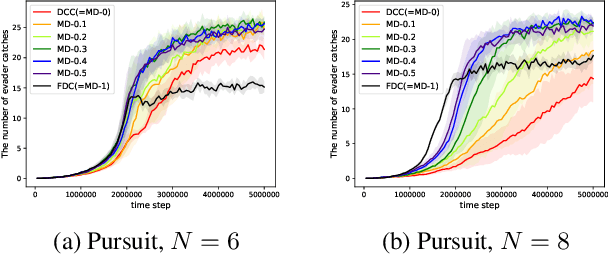
In this paper, we propose a new learning technique named message-dropout to improve the performance for multi-agent deep reinforcement learning under two application scenarios: 1) classical multi-agent reinforcement learning with direct message communication among agents and 2) centralized training with decentralized execution. In the first application scenario of multi-agent systems in which direct message communication among agents is allowed, the message-dropout technique drops out the received messages from other agents in a block-wise manner with a certain probability in the training phase and compensates for this effect by multiplying the weights of the dropped-out block units with a correction probability. The applied message-dropout technique effectively handles the increased input dimension in multi-agent reinforcement learning with communication and makes learning robust against communication errors in the execution phase. In the second application scenario of centralized training with decentralized execution, we particularly consider the application of the proposed message-dropout to Multi-Agent Deep Deterministic Policy Gradient (MADDPG), which uses a centralized critic to train a decentralized actor for each agent. We evaluate the proposed message-dropout technique for several games, and numerical results show that the proposed message-dropout technique with proper dropout rate improves the reinforcement learning performance significantly in terms of the training speed and the steady-state performance in the execution phase.