 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMessage-Dropout: An Efficient Training Method for Multi-Agent Deep Reinforcement Learning
Paper and Code
Feb 18, 2019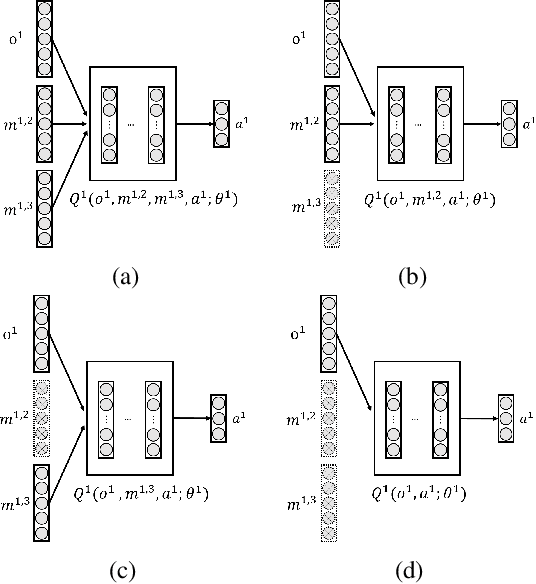
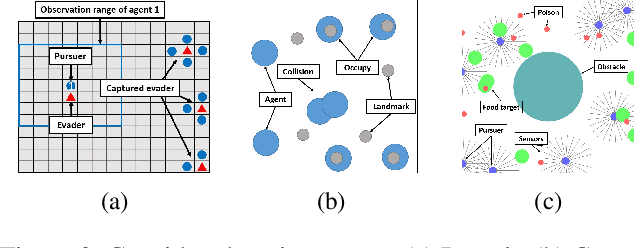

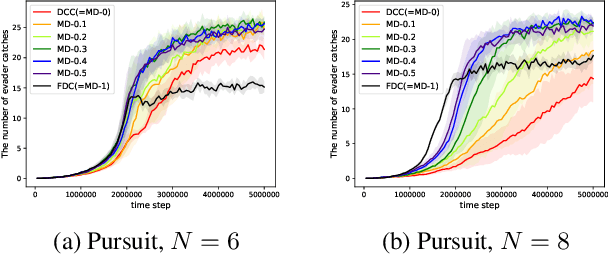
In this paper, we propose a new learning technique named message-dropout to improve the performance for multi-agent deep reinforcement learning under two application scenarios: 1) classical multi-agent reinforcement learning with direct message communication among agents and 2) centralized training with decentralized execution. In the first application scenario of multi-agent systems in which direct message communication among agents is allowed, the message-dropout technique drops out the received messages from other agents in a block-wise manner with a certain probability in the training phase and compensates for this effect by multiplying the weights of the dropped-out block units with a correction probability. The applied message-dropout technique effectively handles the increased input dimension in multi-agent reinforcement learning with communication and makes learning robust against communication errors in the execution phase. In the second application scenario of centralized training with decentralized execution, we particularly consider the application of the proposed message-dropout to Multi-Agent Deep Deterministic Policy Gradient (MADDPG), which uses a centralized critic to train a decentralized actor for each agent. We evaluate the proposed message-dropout technique for several games, and numerical results show that the proposed message-dropout technique with proper dropout rate improves the reinforcement learning performance significantly in terms of the training speed and the steady-state performance in the execution phase.