 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Aware Virtual Training: Enhancing Generalization in Meta-Reinforcement Learning for Out-of-Distribution Tasks
Paper and Code
Feb 05, 2025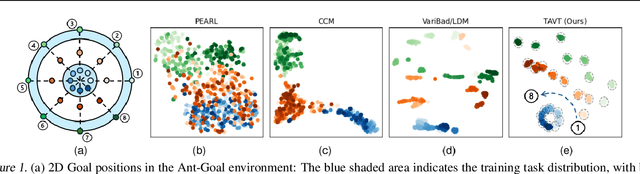
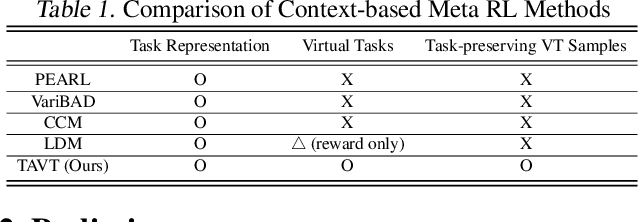
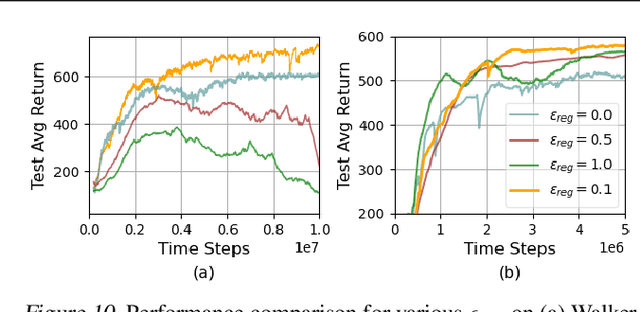
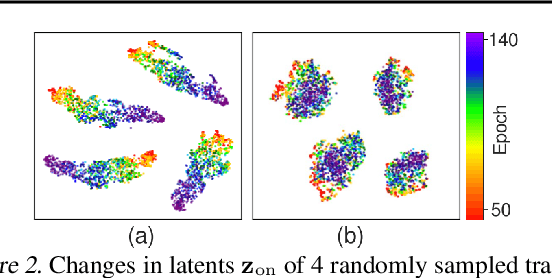
Meta reinforcement learning aims to develop policies that generalize to unseen tasks sampled from a task distribution. While context-based meta-RL methods improve task representation using task latents, they often struggle with out-of-distribution (OOD) tasks. To address this, we propose Task-Aware Virtual Training (TAVT), a novel algorithm that accurately captures task characteristics for both training and OOD scenarios using metric-based representation learning. Our method successfully preserves task characteristics in virtual tasks and employs a state regularization technique to mitigate overestimation errors in state-varying environments. Numerical results demonstrate that TAVT significantly enhances generalization to OOD tasks across various MuJoCo and MetaWorld environments.