 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCenter of Gravity-Guided Focusing Influence Mechanism for Multi-Agent Reinforcement Learning
Jun 24, 2025



Cooperative multi-agent reinforcement learning (MARL) under sparse rewards presents a fundamental challenge due to limited exploration and insufficient coordinated attention among agents. In this work, we propose the Focusing Influence Mechanism (FIM), a novel framework that enhances cooperation by directing agent influence toward task-critical elements, referred to as Center of Gravity (CoG) state dimensions, inspired by Clausewitz's military theory. FIM consists of three core components: (1) identifying CoG state dimensions based on their stability under agent behavior, (2) designing counterfactual intrinsic rewards to promote meaningful influence on these dimensions, and (3) encouraging persistent and synchronized focus through eligibility-trace-based credit accumulation. These mechanisms enable agents to induce more targeted and effective state transitions, facilitating robust cooperation even in extremely sparse reward settings. Empirical evaluations across diverse MARL benchmarks demonstrate that the proposed FIM significantly improves cooperative performance compared to baselines.
PRISM: A Robust Framework for Skill-based Meta-Reinforcement Learning with Noisy Demonstrations
Feb 06, 2025



Meta-reinforcement learning (Meta-RL) facilitates rapid adaptation to unseen tasks but faces challenges in long-horizon environments. Skill-based approaches tackle this by decomposing state-action sequences into reusable skills and employing hierarchical decision-making. However, these methods are highly susceptible to noisy offline demonstrations, resulting in unstable skill learning and degraded performance. To overcome this, we propose Prioritized Refinement for Skill-Based Meta-RL (PRISM), a robust framework that integrates exploration near noisy data to generate online trajectories and combines them with offline data. Through prioritization, PRISM extracts high-quality data to learn task-relevant skills effectively. By addressing the impact of noise, our method ensures stable skill learning and achieves superior performance in long-horizon tasks, even with noisy and sub-optimal data.
Task-Aware Virtual Training: Enhancing Generalization in Meta-Reinforcement Learning for Out-of-Distribution Tasks
Feb 05, 2025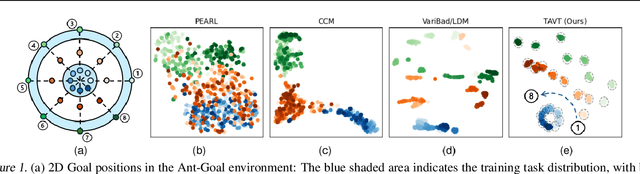
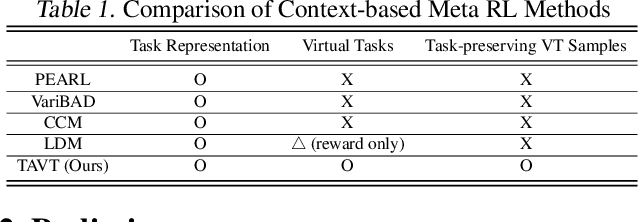
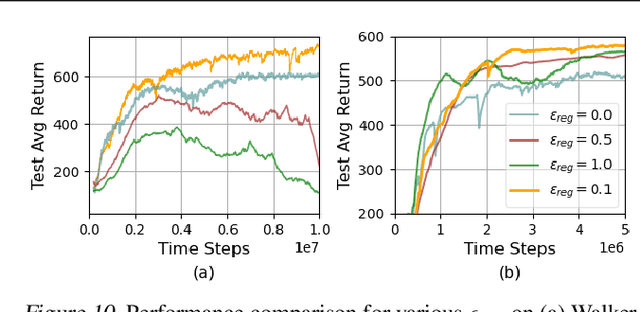
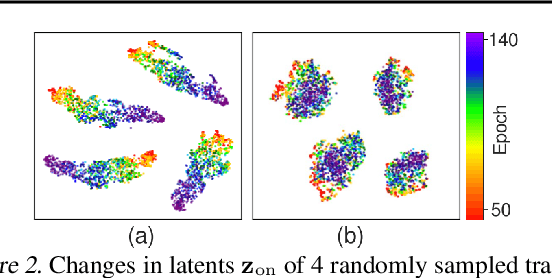
Meta reinforcement learning aims to develop policies that generalize to unseen tasks sampled from a task distribution. While context-based meta-RL methods improve task representation using task latents, they often struggle with out-of-distribution (OOD) tasks. To address this, we propose Task-Aware Virtual Training (TAVT), a novel algorithm that accurately captures task characteristics for both training and OOD scenarios using metric-based representation learning. Our method successfully preserves task characteristics in virtual tasks and employs a state regularization technique to mitigate overestimation errors in state-varying environments. Numerical results demonstrate that TAVT significantly enhances generalization to OOD tasks across various MuJoCo and MetaWorld environments.