 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Invariant Per-Frame Feature Extraction for Cross-Domain Imitation Learning with Visual Observations
Feb 05, 2025Imitation learning (IL) enables agents to mimic expert behavior without reward signals but faces challenges in cross-domain scenarios with high-dimensional, noisy, and incomplete visual observations. To address this, we propose Domain-Invariant Per-Frame Feature Extraction for Imitation Learning (DIFF-IL), a novel IL method that extracts domain-invariant features from individual frames and adapts them into sequences to isolate and replicate expert behaviors. We also introduce a frame-wise time labeling technique to segment expert behaviors by timesteps and assign rewards aligned with temporal contexts, enhancing task performance. Experiments across diverse visual environments demonstrate the effectiveness of DIFF-IL in addressing complex visual tasks.
Improving Perceptual Quality, Intelligibility, and Acoustics on VoIP Platforms
Mar 16, 2023

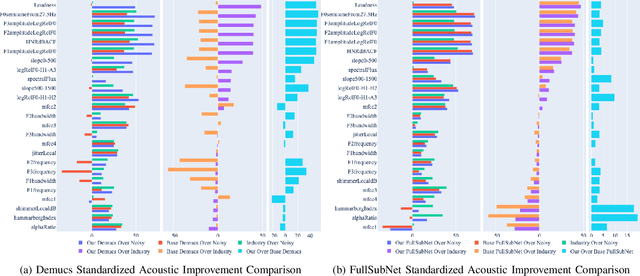

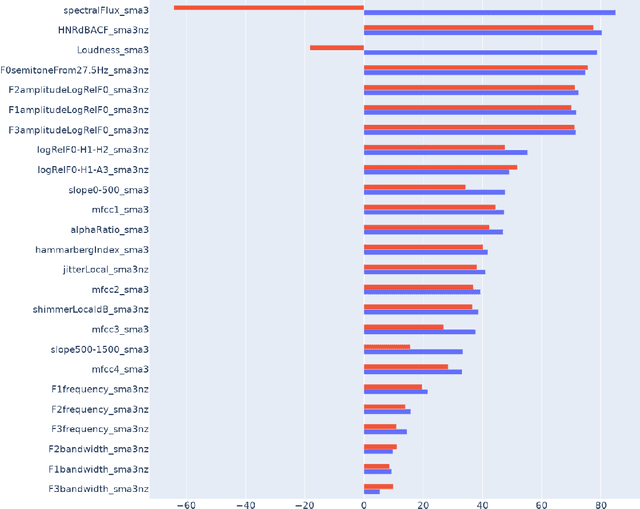
In this paper, we present a method for fine-tuning models trained on the Deep Noise Suppression (DNS) 2020 Challenge to improve their performance on Voice over Internet Protocol (VoIP) applications. Our approach involves adapting the DNS 2020 models to the specific acoustic characteristics of VoIP communications, which includes distortion and artifacts caused by compression, transmission, and platform-specific processing. To this end, we propose a multi-task learning framework for VoIP-DNS that jointly optimizes noise suppression and VoIP-specific acoustics for speech enhancement. We evaluate our approach on a diverse VoIP scenarios and show that it outperforms both industry performance and state-of-the-art methods for speech enhancement on VoIP applications. Our results demonstrate the potential of models trained on DNS-2020 to be improved and tailored to different VoIP platforms using VoIP-DNS, whose findings have important applications in areas such as speech recognition, voice assistants, and telecommunication.
Speech Enhancement for Virtual Meetings on Cellular Networks
Feb 16, 2023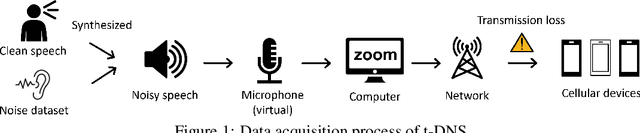
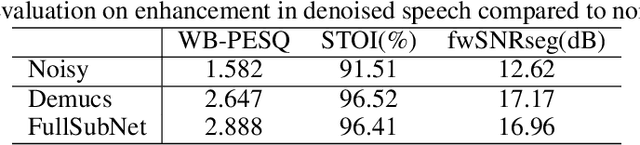
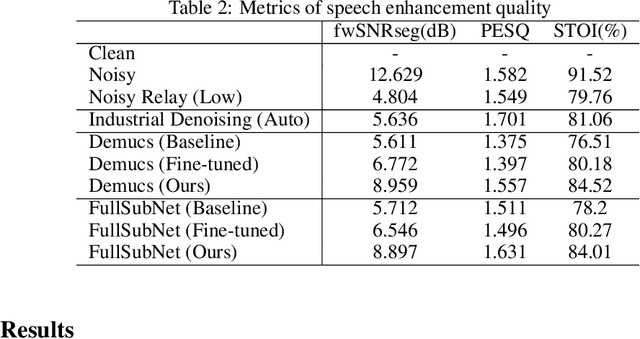
We study speech enhancement using deep learning (DL) for virtual meetings on cellular devices, where transmitted speech has background noise and transmission loss that affects speech quality. Since the Deep Noise Suppression (DNS) Challenge dataset does not contain practical disturbance, we collect a transmitted DNS (t-DNS) dataset using Zoom Meetings over T-Mobile network. We select two baseline models: Demucs and FullSubNet. The Demucs is an end-to-end model that takes time-domain inputs and outputs time-domain denoised speech, and the FullSubNet takes time-frequency-domain inputs and outputs the energy ratio of the target speech in the inputs. The goal of this project is to enhance the speech transmitted over the cellular networks using deep learning models.