 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePsychoacoustic Challenges Of Speech Enhancement On VoIP Platforms
Oct 11, 2023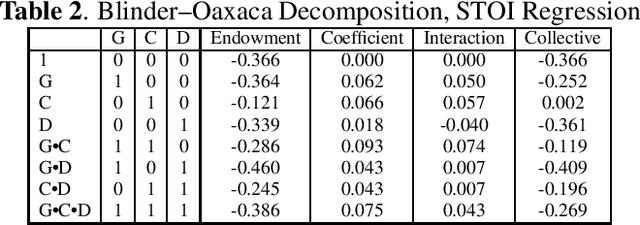
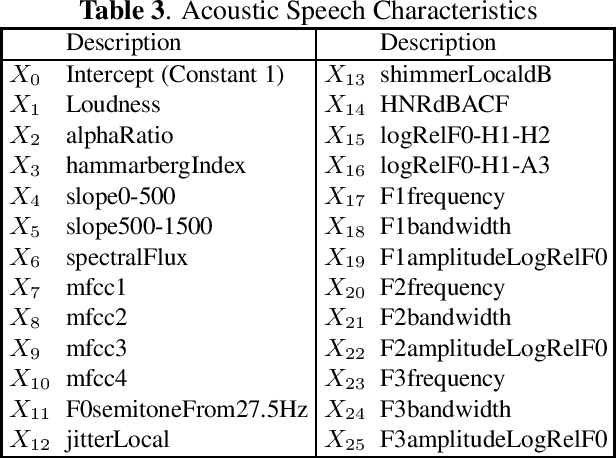

Within the ambit of VoIP (Voice over Internet Protocol) telecommunications, the complexities introduced by acoustic transformations merit rigorous analysis. This research, rooted in the exploration of proprietary sender-side denoising effects, meticulously evaluates platforms such as Google Meets and Zoom. The study draws upon the Deep Noise Suppression (DNS) 2020 dataset, ensuring a structured examination tailored to various denoising settings and receiver interfaces. A methodological novelty is introduced via the Oaxaca decomposition, traditionally an econometric tool, repurposed herein to analyze acoustic-phonetic perturbations within VoIP systems. To further ground the implications of these transformations, psychoacoustic metrics, specifically PESQ and STOI, were harnessed to furnish a comprehensive understanding of speech alterations. Cumulatively, the insights garnered underscore the intricate landscape of VoIP-influenced acoustic dynamics. In addition to the primary findings, a multitude of metrics are reported, extending the research purview. Moreover, out-of-domain benchmarking for both time and time-frequency domain speech enhancement models is included, thereby enhancing the depth and applicability of this inquiry.
Improving Perceptual Quality, Intelligibility, and Acoustics on VoIP Platforms
Mar 16, 2023


In this paper, we present a method for fine-tuning models trained on the Deep Noise Suppression (DNS) 2020 Challenge to improve their performance on Voice over Internet Protocol (VoIP) applications. Our approach involves adapting the DNS 2020 models to the specific acoustic characteristics of VoIP communications, which includes distortion and artifacts caused by compression, transmission, and platform-specific processing. To this end, we propose a multi-task learning framework for VoIP-DNS that jointly optimizes noise suppression and VoIP-specific acoustics for speech enhancement. We evaluate our approach on a diverse VoIP scenarios and show that it outperforms both industry performance and state-of-the-art methods for speech enhancement on VoIP applications. Our results demonstrate the potential of models trained on DNS-2020 to be improved and tailored to different VoIP platforms using VoIP-DNS, whose findings have important applications in areas such as speech recognition, voice assistants, and telecommunication.
Speech Enhancement for Virtual Meetings on Cellular Networks
Feb 16, 2023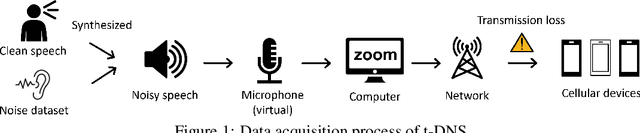
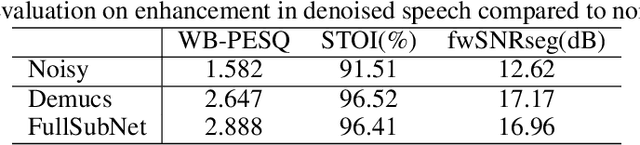
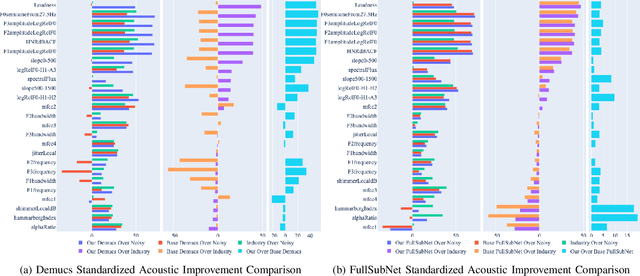
We study speech enhancement using deep learning (DL) for virtual meetings on cellular devices, where transmitted speech has background noise and transmission loss that affects speech quality. Since the Deep Noise Suppression (DNS) Challenge dataset does not contain practical disturbance, we collect a transmitted DNS (t-DNS) dataset using Zoom Meetings over T-Mobile network. We select two baseline models: Demucs and FullSubNet. The Demucs is an end-to-end model that takes time-domain inputs and outputs time-domain denoised speech, and the FullSubNet takes time-frequency-domain inputs and outputs the energy ratio of the target speech in the inputs. The goal of this project is to enhance the speech transmitted over the cellular networks using deep learning models.
Cellular Network Speech Enhancement: Removing Background and Transmission Noise
Jan 22, 2023
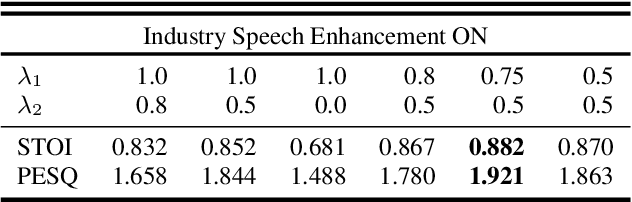

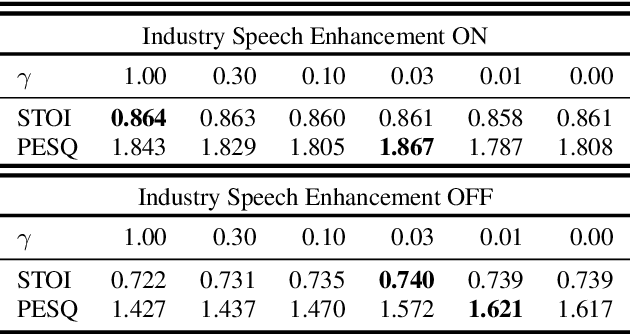
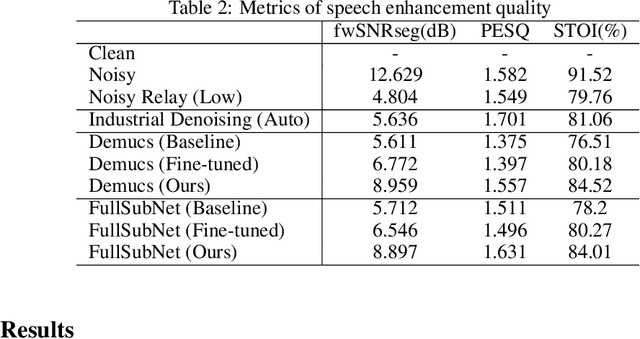
The primary objective of speech enhancement is to reduce background noise while preserving the target's speech. A common dilemma occurs when a speaker is confined to a noisy environment and receives a call with high background and transmission noise. To address this problem, the Deep Noise Suppression (DNS) Challenge focuses on removing the background noise with the next-generation deep learning models to enhance the target's speech; however, researchers fail to consider Voice Over IP (VoIP) applications their transmission noise. Focusing on Google Meet and its cellular application, our work achieves state-of-the-art performance on the Google Meet To Phone Track of the VoIP DNS Challenge. This paper demonstrates how to beat industrial performance and achieve 1.92 PESQ and 0.88 STOI, as well as superior acoustic fidelity, perceptual quality, and intelligibility in various metrics.