 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePsychoacoustic Challenges Of Speech Enhancement On VoIP Platforms
Oct 11, 2023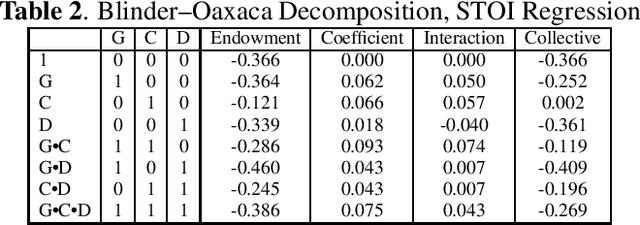

Within the ambit of VoIP (Voice over Internet Protocol) telecommunications, the complexities introduced by acoustic transformations merit rigorous analysis. This research, rooted in the exploration of proprietary sender-side denoising effects, meticulously evaluates platforms such as Google Meets and Zoom. The study draws upon the Deep Noise Suppression (DNS) 2020 dataset, ensuring a structured examination tailored to various denoising settings and receiver interfaces. A methodological novelty is introduced via the Oaxaca decomposition, traditionally an econometric tool, repurposed herein to analyze acoustic-phonetic perturbations within VoIP systems. To further ground the implications of these transformations, psychoacoustic metrics, specifically PESQ and STOI, were harnessed to furnish a comprehensive understanding of speech alterations. Cumulatively, the insights garnered underscore the intricate landscape of VoIP-influenced acoustic dynamics. In addition to the primary findings, a multitude of metrics are reported, extending the research purview. Moreover, out-of-domain benchmarking for both time and time-frequency domain speech enhancement models is included, thereby enhancing the depth and applicability of this inquiry.
Improving Perceptual Quality, Intelligibility, and Acoustics on VoIP Platforms
Mar 16, 2023


In this paper, we present a method for fine-tuning models trained on the Deep Noise Suppression (DNS) 2020 Challenge to improve their performance on Voice over Internet Protocol (VoIP) applications. Our approach involves adapting the DNS 2020 models to the specific acoustic characteristics of VoIP communications, which includes distortion and artifacts caused by compression, transmission, and platform-specific processing. To this end, we propose a multi-task learning framework for VoIP-DNS that jointly optimizes noise suppression and VoIP-specific acoustics for speech enhancement. We evaluate our approach on a diverse VoIP scenarios and show that it outperforms both industry performance and state-of-the-art methods for speech enhancement on VoIP applications. Our results demonstrate the potential of models trained on DNS-2020 to be improved and tailored to different VoIP platforms using VoIP-DNS, whose findings have important applications in areas such as speech recognition, voice assistants, and telecommunication.
Speech Enhancement for Virtual Meetings on Cellular Networks
Feb 16, 2023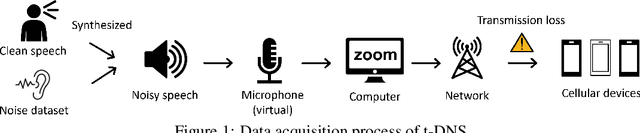
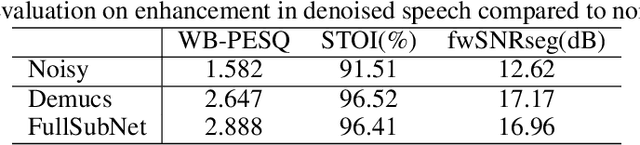
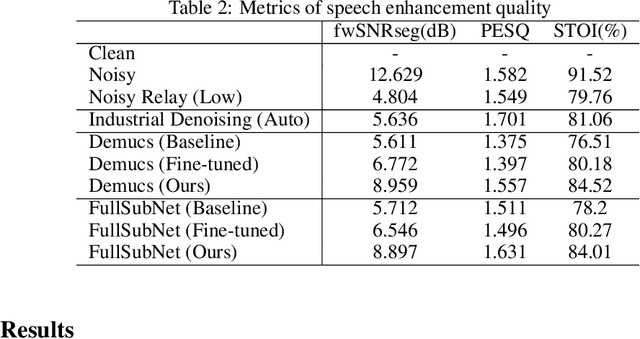
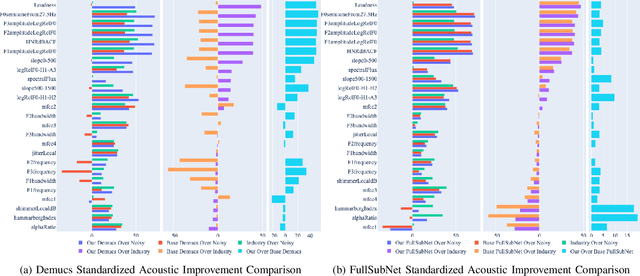
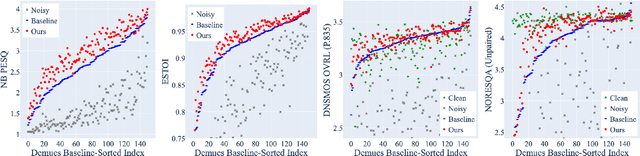
We study speech enhancement using deep learning (DL) for virtual meetings on cellular devices, where transmitted speech has background noise and transmission loss that affects speech quality. Since the Deep Noise Suppression (DNS) Challenge dataset does not contain practical disturbance, we collect a transmitted DNS (t-DNS) dataset using Zoom Meetings over T-Mobile network. We select two baseline models: Demucs and FullSubNet. The Demucs is an end-to-end model that takes time-domain inputs and outputs time-domain denoised speech, and the FullSubNet takes time-frequency-domain inputs and outputs the energy ratio of the target speech in the inputs. The goal of this project is to enhance the speech transmitted over the cellular networks using deep learning models.
PAAPLoss: A Phonetic-Aligned Acoustic Parameter Loss for Speech Enhancement
Feb 16, 2023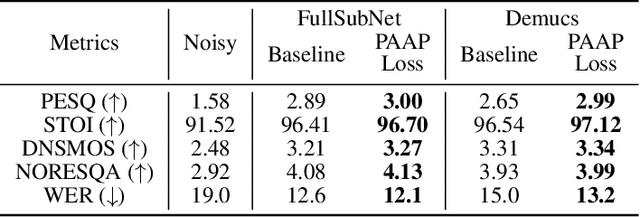
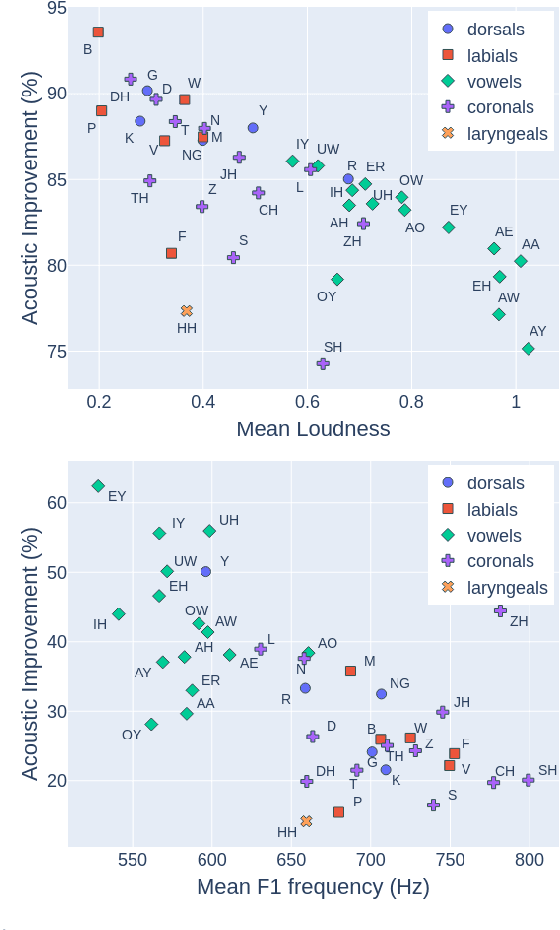
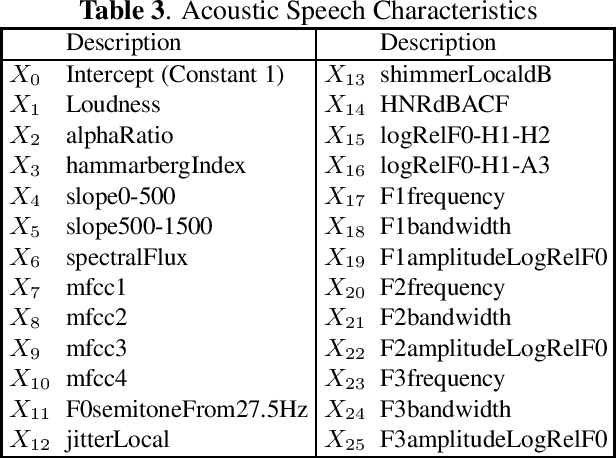
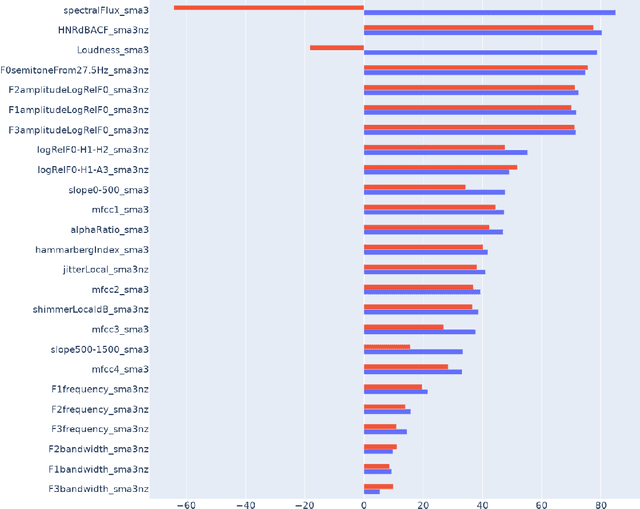
Despite rapid advancement in recent years, current speech enhancement models often produce speech that differs in perceptual quality from real clean speech. We propose a learning objective that formalizes differences in perceptual quality, by using domain knowledge of acoustic-phonetics. We identify temporal acoustic parameters -- such as spectral tilt, spectral flux, shimmer, etc. -- that are non-differentiable, and we develop a neural network estimator that can accurately predict their time-series values across an utterance. We also model phoneme-specific weights for each feature, as the acoustic parameters are known to show different behavior in different phonemes. We can add this criterion as an auxiliary loss to any model that produces speech, to optimize speech outputs to match the values of clean speech in these features. Experimentally we show that it improves speech enhancement workflows in both time-domain and time-frequency domain, as measured by standard evaluation metrics. We also provide an analysis of phoneme-dependent improvement on acoustic parameters, demonstrating the additional interpretability that our method provides. This analysis can suggest which features are currently the bottleneck for improvement.
TAPLoss: A Temporal Acoustic Parameter Loss for Speech Enhancement
Feb 16, 2023
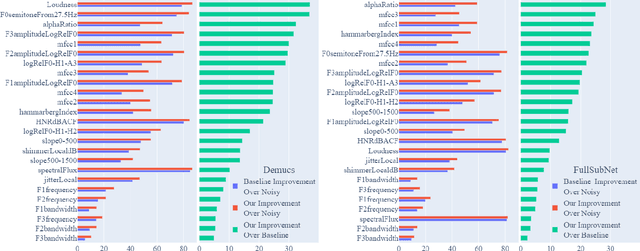

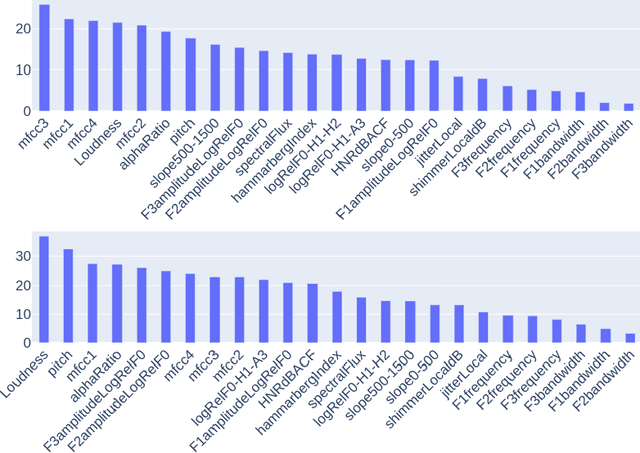
Speech enhancement models have greatly progressed in recent years, but still show limits in perceptual quality of their speech outputs. We propose an objective for perceptual quality based on temporal acoustic parameters. These are fundamental speech features that play an essential role in various applications, including speaker recognition and paralinguistic analysis. We provide a differentiable estimator for four categories of low-level acoustic descriptors involving: frequency-related parameters, energy or amplitude-related parameters, spectral balance parameters, and temporal features. Unlike prior work that looks at aggregated acoustic parameters or a few categories of acoustic parameters, our temporal acoustic parameter (TAP) loss enables auxiliary optimization and improvement of many fine-grain speech characteristics in enhancement workflows. We show that adding TAPLoss as an auxiliary objective in speech enhancement produces speech with improved perceptual quality and intelligibility. We use data from the Deep Noise Suppression 2020 Challenge to demonstrate that both time-domain models and time-frequency domain models can benefit from our method.
Cellular Network Speech Enhancement: Removing Background and Transmission Noise
Jan 22, 2023
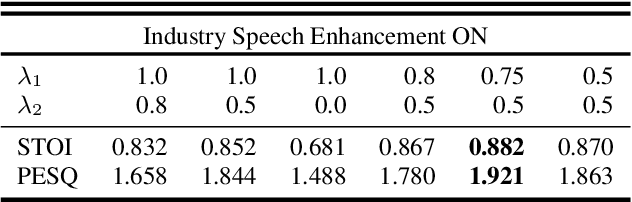

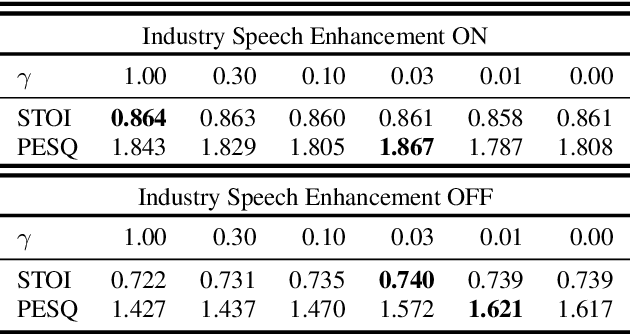
The primary objective of speech enhancement is to reduce background noise while preserving the target's speech. A common dilemma occurs when a speaker is confined to a noisy environment and receives a call with high background and transmission noise. To address this problem, the Deep Noise Suppression (DNS) Challenge focuses on removing the background noise with the next-generation deep learning models to enhance the target's speech; however, researchers fail to consider Voice Over IP (VoIP) applications their transmission noise. Focusing on Google Meet and its cellular application, our work achieves state-of-the-art performance on the Google Meet To Phone Track of the VoIP DNS Challenge. This paper demonstrates how to beat industrial performance and achieve 1.92 PESQ and 0.88 STOI, as well as superior acoustic fidelity, perceptual quality, and intelligibility in various metrics.
Improving Speech Enhancement through Fine-Grained Speech Characteristics
Jul 11, 2022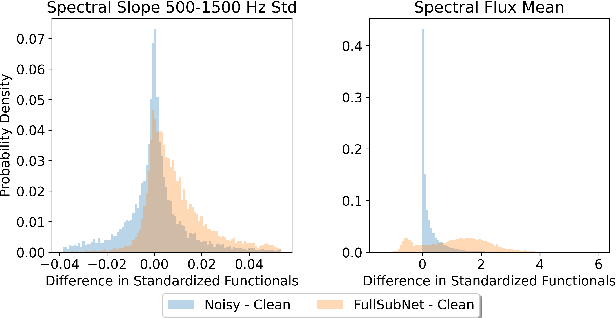
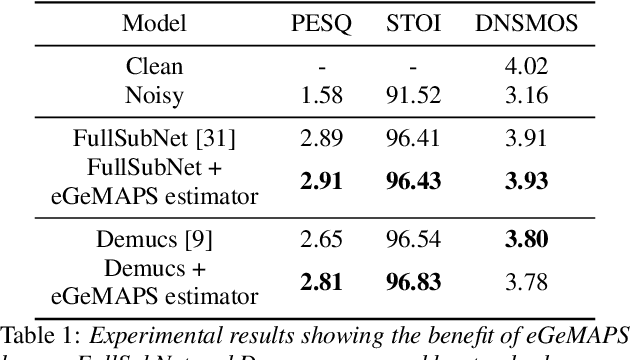
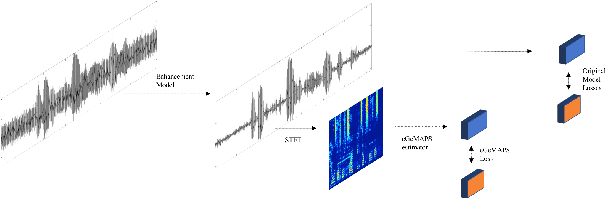
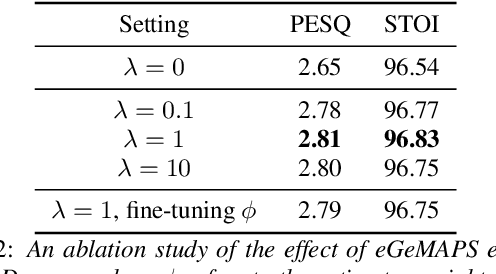
While deep learning based speech enhancement systems have made rapid progress in improving the quality of speech signals, they can still produce outputs that contain artifacts and can sound unnatural. We propose a novel approach to speech enhancement aimed at improving perceptual quality and naturalness of enhanced signals by optimizing for key characteristics of speech. We first identify key acoustic parameters that have been found to correlate well with voice quality (e.g. jitter, shimmer, and spectral flux) and then propose objective functions which are aimed at reducing the difference between clean speech and enhanced speech with respect to these features. The full set of acoustic features is the extended Geneva Acoustic Parameter Set (eGeMAPS), which includes 25 different attributes associated with perception of speech. Given the non-differentiable nature of these feature computation, we first build differentiable estimators of the eGeMAPS and then use them to fine-tune existing speech enhancement systems. Our approach is generic and can be applied to any existing deep learning based enhancement systems to further improve the enhanced speech signals. Experimental results conducted on the Deep Noise Suppression (DNS) Challenge dataset shows that our approach can improve the state-of-the-art deep learning based enhancement systems.
Using Deep Learning Sequence Models to Identify SARS-CoV-2 Divergence
Nov 12, 2021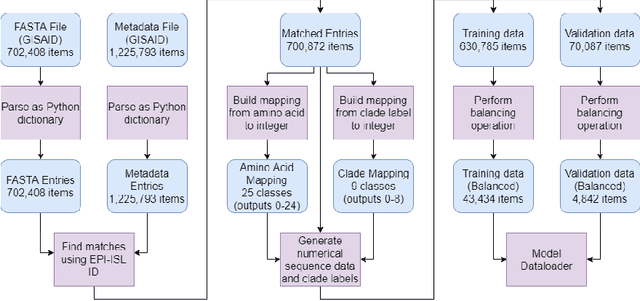
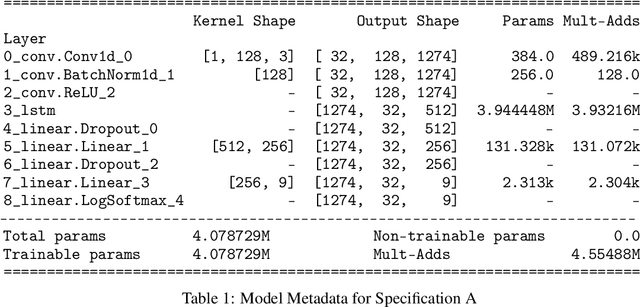
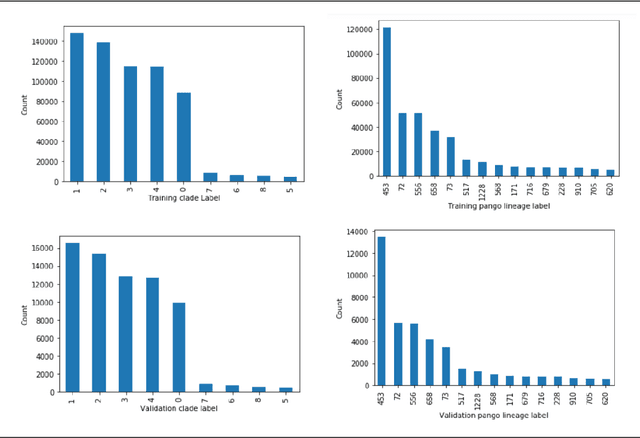
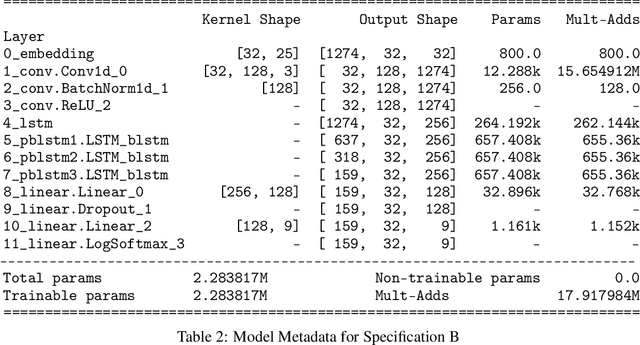
SARS-CoV-2 is an upper respiratory system RNA virus that has caused over 3 million deaths and infecting over 150 million worldwide as of May 2021. With thousands of strains sequenced to date, SARS-CoV-2 mutations pose significant challenges to scientists on keeping pace with vaccine development and public health measures. Therefore, an efficient method of identifying the divergence of lab samples from patients would greatly aid the documentation of SARS-CoV-2 genomics. In this study, we propose a neural network model that leverages recurrent and convolutional units to directly take in amino acid sequences of spike proteins and classify corresponding clades. We also compared our model's performance with Bidirectional Encoder Representations from Transformers (BERT) pre-trained on protein database. Our approach has the potential of providing a more computationally efficient alternative to current homology based intra-species differentiation.