 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving One-Shot Transmission in NR Sidelink Resource Allocation for V2X Communication
Dec 26, 2023The Society of Automotive Engineers (SAE) has specified a wireless channel congestion control algorithm for cellular vehicle-to-everything (C-V2X) communication in J3161/1. A notable aspect of J3161/1 standard is that it addresses persistent packet collisions between neighboring vehicles. Although the chances are slim, the persistent collisions can cause so called the wireless blind spot once the event takes place. Then the involved vehicles cannot inform their presence to neighboring vehicles, an extremely dangerous condition for driving safety. J3161's solution to the problem is stochastic one-shot transmission, where the transmission occasionally occurs in a resource that is not originally reserved. Through the one-shot transmission, the worst-case packet inter-reception time (PIR) is bounded and the wireless blind spot problem can be effectively mitigated. Interestingly, the standard one-shot transmission scheme does not resolve the persistent collision relation itself. This paper shows that by breaking out of the relation as soon as the persistent collision condition is identified, vehicles can improve the worst-case PIR by approximately 500 ms, the number of packet collisions per persistent collision event by 10%, and the number of total collisions by 15% to 57% over the standard one-shot transmission.
Improving Perceptual Quality, Intelligibility, and Acoustics on VoIP Platforms
Mar 16, 2023In this paper, we present a method for fine-tuning models trained on the Deep Noise Suppression (DNS) 2020 Challenge to improve their performance on Voice over Internet Protocol (VoIP) applications. Our approach involves adapting the DNS 2020 models to the specific acoustic characteristics of VoIP communications, which includes distortion and artifacts caused by compression, transmission, and platform-specific processing. To this end, we propose a multi-task learning framework for VoIP-DNS that jointly optimizes noise suppression and VoIP-specific acoustics for speech enhancement. We evaluate our approach on a diverse VoIP scenarios and show that it outperforms both industry performance and state-of-the-art methods for speech enhancement on VoIP applications. Our results demonstrate the potential of models trained on DNS-2020 to be improved and tailored to different VoIP platforms using VoIP-DNS, whose findings have important applications in areas such as speech recognition, voice assistants, and telecommunication.
Speech Enhancement for Virtual Meetings on Cellular Networks
Feb 16, 2023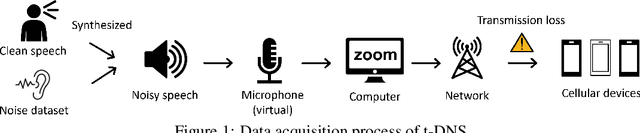
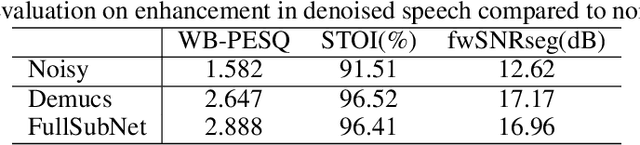
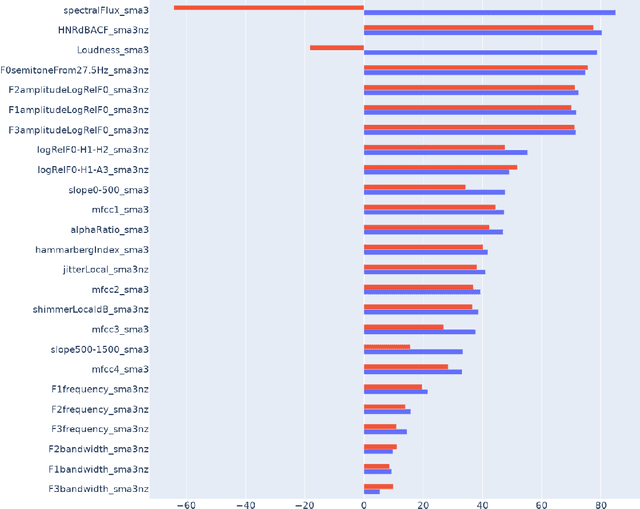
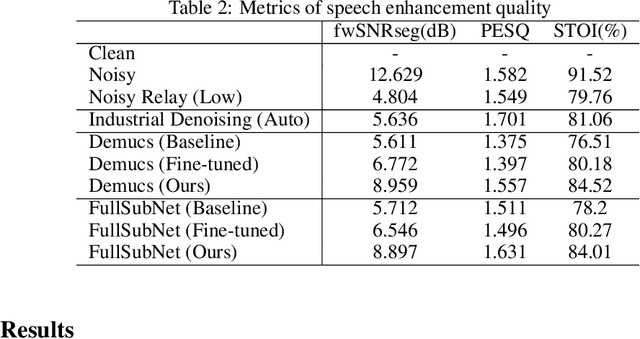
We study speech enhancement using deep learning (DL) for virtual meetings on cellular devices, where transmitted speech has background noise and transmission loss that affects speech quality. Since the Deep Noise Suppression (DNS) Challenge dataset does not contain practical disturbance, we collect a transmitted DNS (t-DNS) dataset using Zoom Meetings over T-Mobile network. We select two baseline models: Demucs and FullSubNet. The Demucs is an end-to-end model that takes time-domain inputs and outputs time-domain denoised speech, and the FullSubNet takes time-frequency-domain inputs and outputs the energy ratio of the target speech in the inputs. The goal of this project is to enhance the speech transmitted over the cellular networks using deep learning models.