 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Perceptual Quality, Intelligibility, and Acoustics on VoIP Platforms
Mar 16, 2023In this paper, we present a method for fine-tuning models trained on the Deep Noise Suppression (DNS) 2020 Challenge to improve their performance on Voice over Internet Protocol (VoIP) applications. Our approach involves adapting the DNS 2020 models to the specific acoustic characteristics of VoIP communications, which includes distortion and artifacts caused by compression, transmission, and platform-specific processing. To this end, we propose a multi-task learning framework for VoIP-DNS that jointly optimizes noise suppression and VoIP-specific acoustics for speech enhancement. We evaluate our approach on a diverse VoIP scenarios and show that it outperforms both industry performance and state-of-the-art methods for speech enhancement on VoIP applications. Our results demonstrate the potential of models trained on DNS-2020 to be improved and tailored to different VoIP platforms using VoIP-DNS, whose findings have important applications in areas such as speech recognition, voice assistants, and telecommunication.
Cellular Network Speech Enhancement: Removing Background and Transmission Noise
Jan 22, 2023
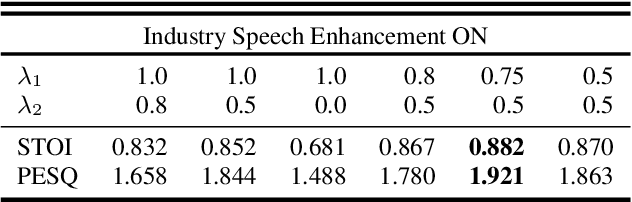

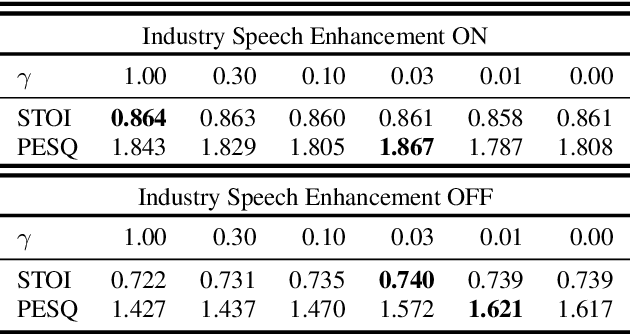
The primary objective of speech enhancement is to reduce background noise while preserving the target's speech. A common dilemma occurs when a speaker is confined to a noisy environment and receives a call with high background and transmission noise. To address this problem, the Deep Noise Suppression (DNS) Challenge focuses on removing the background noise with the next-generation deep learning models to enhance the target's speech; however, researchers fail to consider Voice Over IP (VoIP) applications their transmission noise. Focusing on Google Meet and its cellular application, our work achieves state-of-the-art performance on the Google Meet To Phone Track of the VoIP DNS Challenge. This paper demonstrates how to beat industrial performance and achieve 1.92 PESQ and 0.88 STOI, as well as superior acoustic fidelity, perceptual quality, and intelligibility in various metrics.