 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAPLoss: A Temporal Acoustic Parameter Loss for Speech Enhancement
Paper and Code

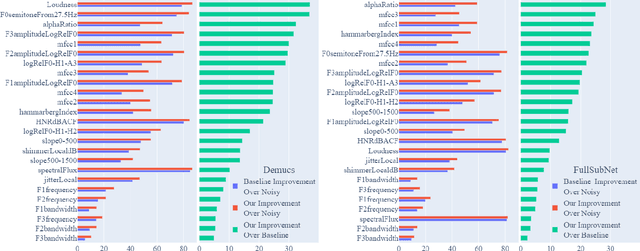

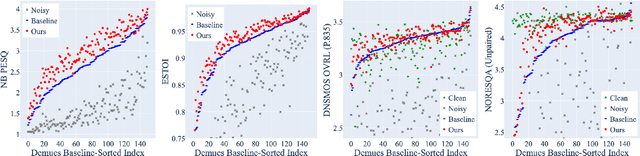
Speech enhancement models have greatly progressed in recent years, but still show limits in perceptual quality of their speech outputs. We propose an objective for perceptual quality based on temporal acoustic parameters. These are fundamental speech features that play an essential role in various applications, including speaker recognition and paralinguistic analysis. We provide a differentiable estimator for four categories of low-level acoustic descriptors involving: frequency-related parameters, energy or amplitude-related parameters, spectral balance parameters, and temporal features. Unlike prior work that looks at aggregated acoustic parameters or a few categories of acoustic parameters, our temporal acoustic parameter (TAP) loss enables auxiliary optimization and improvement of many fine-grain speech characteristics in enhancement workflows. We show that adding TAPLoss as an auxiliary objective in speech enhancement produces speech with improved perceptual quality and intelligibility. We use data from the Deep Noise Suppression 2020 Challenge to demonstrate that both time-domain models and time-frequency domain models can benefit from our method.