 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAPLoss: A Temporal Acoustic Parameter Loss for Speech Enhancement
Feb 16, 2023

Speech enhancement models have greatly progressed in recent years, but still show limits in perceptual quality of their speech outputs. We propose an objective for perceptual quality based on temporal acoustic parameters. These are fundamental speech features that play an essential role in various applications, including speaker recognition and paralinguistic analysis. We provide a differentiable estimator for four categories of low-level acoustic descriptors involving: frequency-related parameters, energy or amplitude-related parameters, spectral balance parameters, and temporal features. Unlike prior work that looks at aggregated acoustic parameters or a few categories of acoustic parameters, our temporal acoustic parameter (TAP) loss enables auxiliary optimization and improvement of many fine-grain speech characteristics in enhancement workflows. We show that adding TAPLoss as an auxiliary objective in speech enhancement produces speech with improved perceptual quality and intelligibility. We use data from the Deep Noise Suppression 2020 Challenge to demonstrate that both time-domain models and time-frequency domain models can benefit from our method.
PAAPLoss: A Phonetic-Aligned Acoustic Parameter Loss for Speech Enhancement
Feb 16, 2023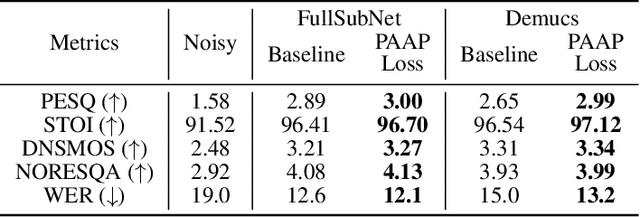
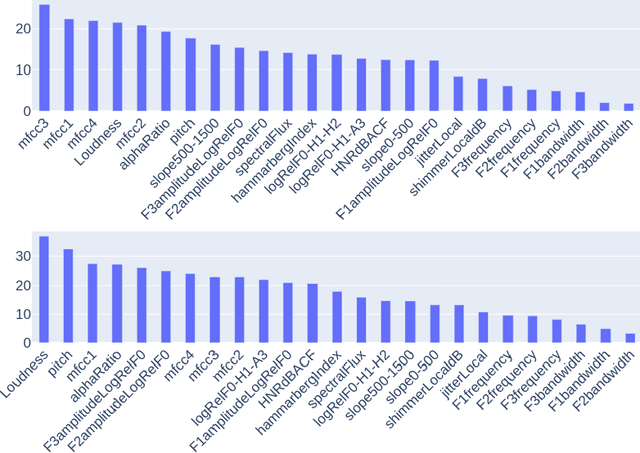
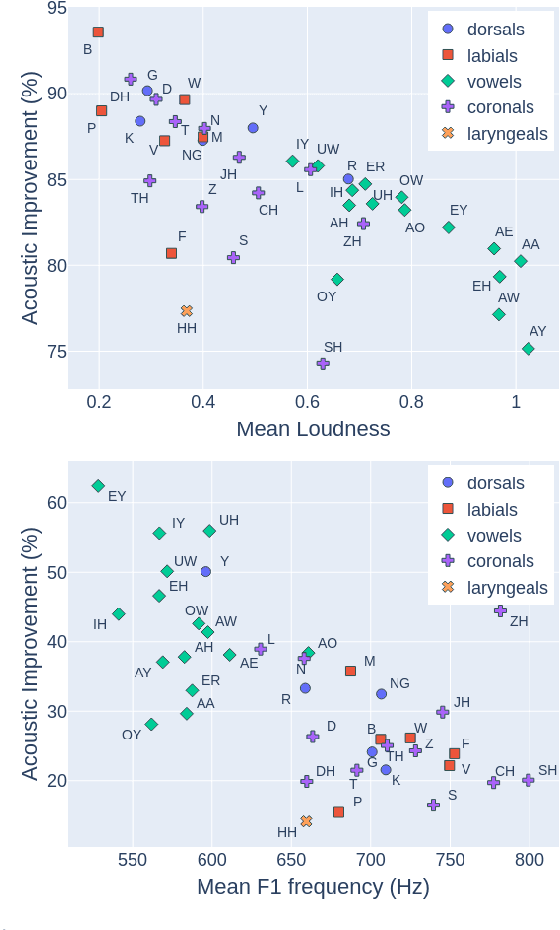
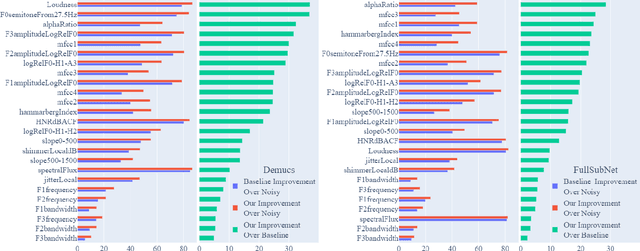
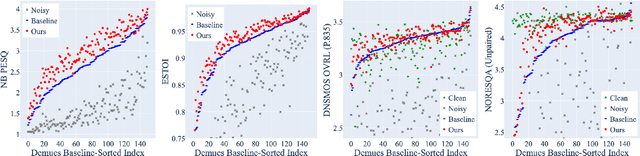
Despite rapid advancement in recent years, current speech enhancement models often produce speech that differs in perceptual quality from real clean speech. We propose a learning objective that formalizes differences in perceptual quality, by using domain knowledge of acoustic-phonetics. We identify temporal acoustic parameters -- such as spectral tilt, spectral flux, shimmer, etc. -- that are non-differentiable, and we develop a neural network estimator that can accurately predict their time-series values across an utterance. We also model phoneme-specific weights for each feature, as the acoustic parameters are known to show different behavior in different phonemes. We can add this criterion as an auxiliary loss to any model that produces speech, to optimize speech outputs to match the values of clean speech in these features. Experimentally we show that it improves speech enhancement workflows in both time-domain and time-frequency domain, as measured by standard evaluation metrics. We also provide an analysis of phoneme-dependent improvement on acoustic parameters, demonstrating the additional interpretability that our method provides. This analysis can suggest which features are currently the bottleneck for improvement.
Improving Speech Enhancement through Fine-Grained Speech Characteristics
Jul 11, 2022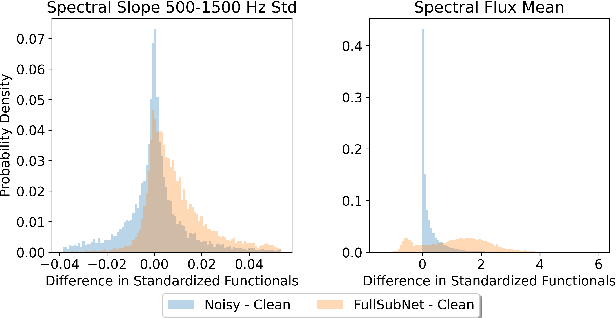
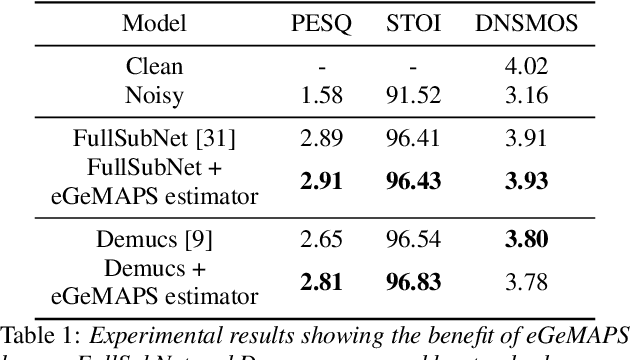
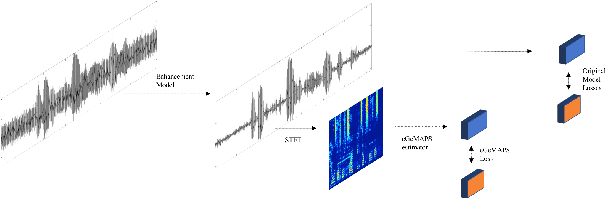
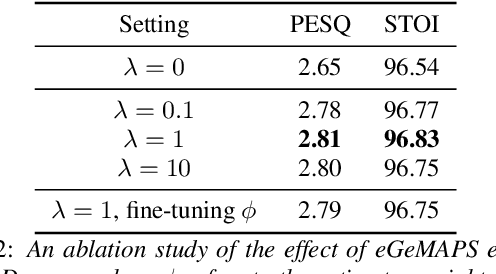
While deep learning based speech enhancement systems have made rapid progress in improving the quality of speech signals, they can still produce outputs that contain artifacts and can sound unnatural. We propose a novel approach to speech enhancement aimed at improving perceptual quality and naturalness of enhanced signals by optimizing for key characteristics of speech. We first identify key acoustic parameters that have been found to correlate well with voice quality (e.g. jitter, shimmer, and spectral flux) and then propose objective functions which are aimed at reducing the difference between clean speech and enhanced speech with respect to these features. The full set of acoustic features is the extended Geneva Acoustic Parameter Set (eGeMAPS), which includes 25 different attributes associated with perception of speech. Given the non-differentiable nature of these feature computation, we first build differentiable estimators of the eGeMAPS and then use them to fine-tune existing speech enhancement systems. Our approach is generic and can be applied to any existing deep learning based enhancement systems to further improve the enhanced speech signals. Experimental results conducted on the Deep Noise Suppression (DNS) Challenge dataset shows that our approach can improve the state-of-the-art deep learning based enhancement systems.