 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Domain Imitation Learning with a Dual Structure
Paper and Code
Jun 04, 2020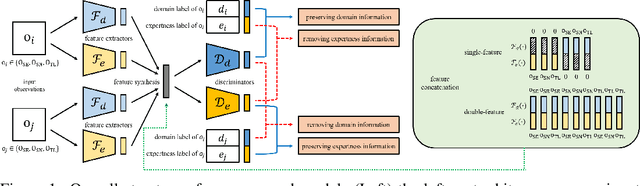
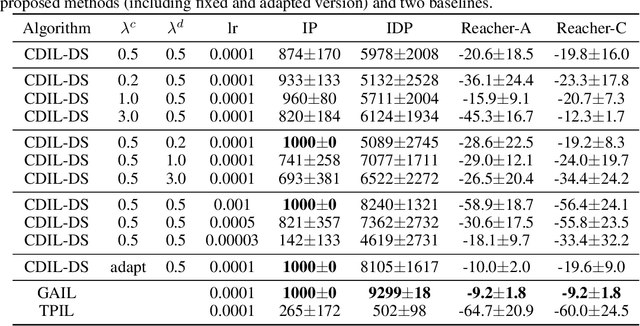
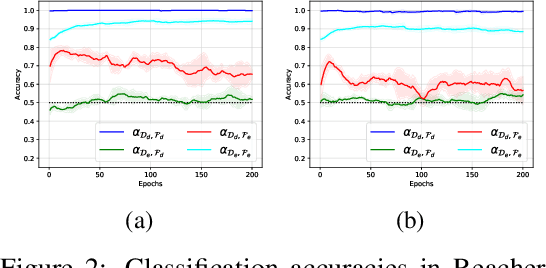
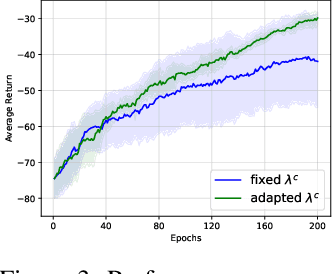
In this paper, we consider cross-domain imitation learning (CDIL) in which an agent in a target domain learns a policy to perform well in the target domain by observing expert demonstrations in a source domain without accessing any reward function. In order to overcome the domain difference for imitation learning, we propose a dual-structured learning method. The proposed learning method extracts two feature vectors from each input observation such that one vector contains domain information and the other vector contains policy expertness information, and then enhances feature vectors by synthesizing new feature vectors containing both target-domain and policy expertness information. The proposed CDIL method is tested on several MuJoCo tasks where the domain difference is determined by image angles or colors. Numerical results show that the proposed method shows superior performance in CDIL to other existing algorithms and achieves almost the same performance as imitation learning without domain difference.