 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStarryGazer: Leveraging Monocular Depth Estimation Models for Domain-Agnostic Single Depth Image Completion
Dec 15, 2025The problem of depth completion involves predicting a dense depth image from a single sparse depth map and an RGB image. Unsupervised depth completion methods have been proposed for various datasets where ground truth depth data is unavailable and supervised methods cannot be applied. However, these models require auxiliary data to estimate depth values, which is far from real scenarios. Monocular depth estimation (MDE) models can produce a plausible relative depth map from a single image, but there is no work to properly combine the sparse depth map with MDE for depth completion; a simple affine transformation to the depth map will yield a high error since MDE are inaccurate at estimating depth difference between objects. We introduce StarryGazer, a domain-agnostic framework that predicts dense depth images from a single sparse depth image and an RGB image without relying on ground-truth depth by leveraging the power of large MDE models. First, we employ a pre-trained MDE model to produce relative depth images. These images are segmented and randomly rescaled to form synthetic pairs for dense pseudo-ground truth and corresponding sparse depths. A refinement network is trained with the synthetic pairs, incorporating the relative depth maps and RGB images to improve the model's accuracy and robustness. StarryGazer shows superior results over existing unsupervised methods and transformed MDE results on various datasets, demonstrating that our framework exploits the power of MDE models while appropriately fixing errors using sparse depth information.
OmniSplat: Taming Feed-Forward 3D Gaussian Splatting for Omnidirectional Images with Editable Capabilities
Dec 21, 2024



Feed-forward 3D Gaussian Splatting (3DGS) models have gained significant popularity due to their ability to generate scenes immediately without needing per-scene optimization. Although omnidirectional images are getting more popular since they reduce the computation for image stitching to composite a holistic scene, existing feed-forward models are only designed for perspective images. The unique optical properties of omnidirectional images make it difficult for feature encoders to correctly understand the context of the image and make the Gaussian non-uniform in space, which hinders the image quality synthesized from novel views. We propose OmniSplat, a pioneering work for fast feed-forward 3DGS generation from a few omnidirectional images. We introduce Yin-Yang grid and decompose images based on it to reduce the domain gap between omnidirectional and perspective images. The Yin-Yang grid can use the existing CNN structure as it is, but its quasi-uniform characteristic allows the decomposed image to be similar to a perspective image, so it can exploit the strong prior knowledge of the learned feed-forward network. OmniSplat demonstrates higher reconstruction accuracy than existing feed-forward networks trained on perspective images. Furthermore, we enhance the segmentation consistency between omnidirectional images by leveraging attention from the encoder of OmniSplat, providing fast and clean 3DGS editing results.
ODGS: 3D Scene Reconstruction from Omnidirectional Images with 3D Gaussian Splattings
Oct 28, 2024Omnidirectional (or 360-degree) images are increasingly being used for 3D applications since they allow the rendering of an entire scene with a single image. Existing works based on neural radiance fields demonstrate successful 3D reconstruction quality on egocentric videos, yet they suffer from long training and rendering times. Recently, 3D Gaussian splatting has gained attention for its fast optimization and real-time rendering. However, directly using a perspective rasterizer to omnidirectional images results in severe distortion due to the different optical properties between two image domains. In this work, we present ODGS, a novel rasterization pipeline for omnidirectional images, with geometric interpretation. For each Gaussian, we define a tangent plane that touches the unit sphere and is perpendicular to the ray headed toward the Gaussian center. We then leverage a perspective camera rasterizer to project the Gaussian onto the corresponding tangent plane. The projected Gaussians are transformed and combined into the omnidirectional image, finalizing the omnidirectional rasterization process. This interpretation reveals the implicit assumptions within the proposed pipeline, which we verify through mathematical proofs. The entire rasterization process is parallelized using CUDA, achieving optimization and rendering speeds 100 times faster than NeRF-based methods. Our comprehensive experiments highlight the superiority of ODGS by delivering the best reconstruction and perceptual quality across various datasets. Additionally, results on roaming datasets demonstrate that ODGS restores fine details effectively, even when reconstructing large 3D scenes. The source code is available on our project page (https://github.com/esw0116/ODGS).
Value-Aided Conditional Supervised Learning for Offline RL
Feb 03, 2024Offline reinforcement learning (RL) has seen notable advancements through return-conditioned supervised learning (RCSL) and value-based methods, yet each approach comes with its own set of practical challenges. Addressing these, we propose Value-Aided Conditional Supervised Learning (VCS), a method that effectively synergizes the stability of RCSL with the stitching ability of value-based methods. Based on the Neural Tangent Kernel analysis to discern instances where value function may not lead to stable stitching, VCS injects the value aid into the RCSL's loss function dynamically according to the trajectory return. Our empirical studies reveal that VCS not only significantly outperforms both RCSL and value-based methods but also consistently achieves, or often surpasses, the highest trajectory returns across diverse offline RL benchmarks. This breakthrough in VCS paves new paths in offline RL, pushing the limits of what can be achieved and fostering further innovations.
LucidDreamer: Domain-free Generation of 3D Gaussian Splatting Scenes
Nov 23, 2023



With the widespread usage of VR devices and contents, demands for 3D scene generation techniques become more popular. Existing 3D scene generation models, however, limit the target scene to specific domain, primarily due to their training strategies using 3D scan dataset that is far from the real-world. To address such limitation, we propose LucidDreamer, a domain-free scene generation pipeline by fully leveraging the power of existing large-scale diffusion-based generative model. Our LucidDreamer has two alternate steps: Dreaming and Alignment. First, to generate multi-view consistent images from inputs, we set the point cloud as a geometrical guideline for each image generation. Specifically, we project a portion of point cloud to the desired view and provide the projection as a guidance for inpainting using the generative model. The inpainted images are lifted to 3D space with estimated depth maps, composing a new points. Second, to aggregate the new points into the 3D scene, we propose an aligning algorithm which harmoniously integrates the portions of newly generated 3D scenes. The finally obtained 3D scene serves as initial points for optimizing Gaussian splats. LucidDreamer produces Gaussian splats that are highly-detailed compared to the previous 3D scene generation methods, with no constraint on domain of the target scene. Project page: https://luciddreamer-cvlab.github.io/
Decision ConvFormer: Local Filtering in MetaFormer is Sufficient for Decision Making
Oct 06, 2023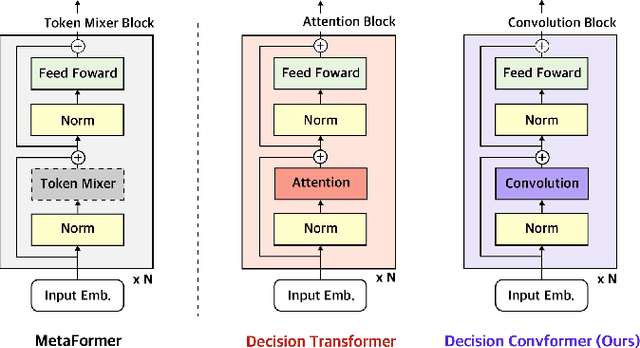
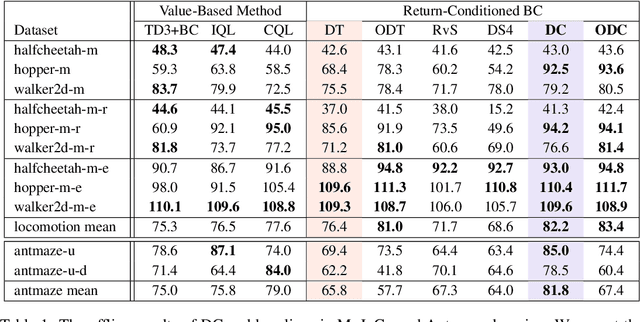
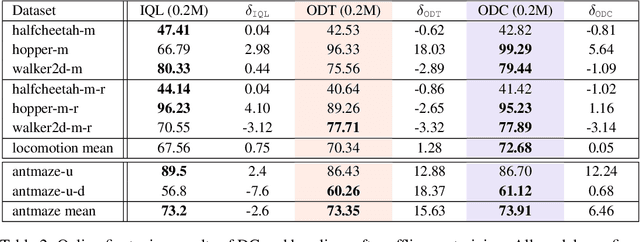
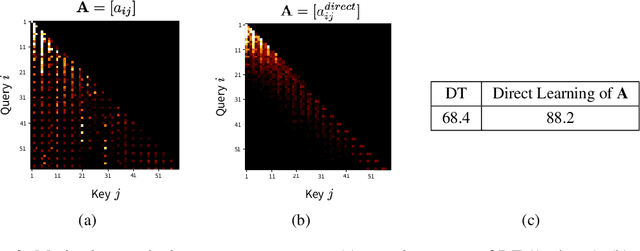
The recent success of Transformer in natural language processing has sparked its use in various domains. In offline reinforcement learning (RL), Decision Transformer (DT) is emerging as a promising model based on Transformer. However, we discovered that the attention module of DT is not appropriate to capture the inherent local dependence pattern in trajectories of RL modeled as a Markov decision process. To overcome the limitations of DT, we propose a novel action sequence predictor, named Decision ConvFormer (DC), based on the architecture of MetaFormer, which is a general structure to process multiple entities in parallel and understand the interrelationship among the multiple entities. DC employs local convolution filtering as the token mixer and can effectively capture the inherent local associations of the RL dataset. In extensive experiments, DC achieved state-of-the-art performance across various standard RL benchmarks while requiring fewer resources. Furthermore, we show that DC better understands the underlying meaning in data and exhibits enhanced generalization capability.
Deep learning-based statistical noise reduction for multidimensional spectral data
Jul 02, 2021



In spectroscopic experiments, data acquisition in multi-dimensional phase space may require long acquisition time, owing to the large phase space volume to be covered. In such case, the limited time available for data acquisition can be a serious constraint for experiments in which multidimensional spectral data are acquired. Here, taking angle-resolved photoemission spectroscopy (ARPES) as an example, we demonstrate a denoising method that utilizes deep learning as an intelligent way to overcome the constraint. With readily available ARPES data and random generation of training data set, we successfully trained the denoising neural network without overfitting. The denoising neural network can remove the noise in the data while preserving its intrinsic information. We show that the denoising neural network allows us to perform similar level of second-derivative and line shape analysis on data taken with two orders of magnitude less acquisition time. The importance of our method lies in its applicability to any multidimensional spectral data that are susceptible to statistical noise.
* 8 pages, 8 figures
Evaluating the Robustness of Trigger Set-Based Watermarks Embedded in Deep Neural Networks
Jun 18, 2021

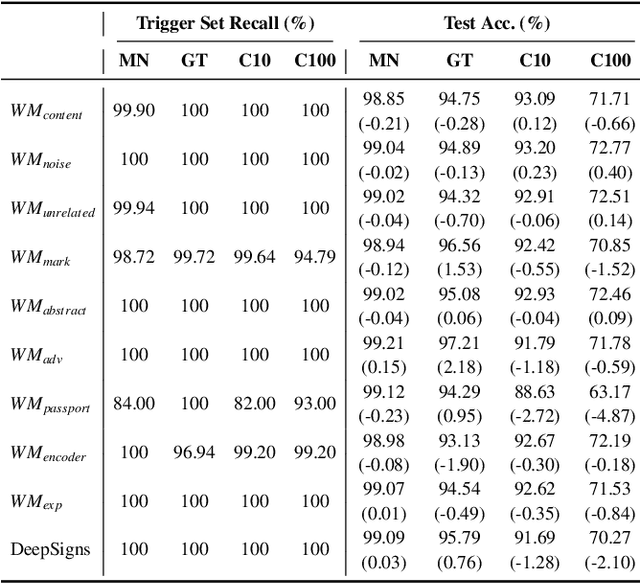
Trigger set-based watermarking schemes have gained emerging attention as they provide a means to prove ownership for deep neural network model owners. In this paper, we argue that state-of-the-art trigger set-based watermarking algorithms do not achieve their designed goal of proving ownership. We posit that this impaired capability stems from two common experimental flaws that the existing research practice has committed when evaluating the robustness of watermarking algorithms: (1) incomplete adversarial evaluation and (2) overlooked adaptive attacks. We conduct a comprehensive adversarial evaluation of 10 representative watermarking schemes against six of the existing attacks and demonstrate that each of these watermarking schemes lacks robustness against at least two attacks. We also propose novel adaptive attacks that harness the adversary's knowledge of the underlying watermarking algorithm of a target model. We demonstrate that the proposed attacks effectively break all of the 10 watermarking schemes, consequently allowing adversaries to obscure the ownership of any watermarked model. We encourage follow-up studies to consider our guidelines when evaluating the robustness of their watermarking schemes via conducting comprehensive adversarial evaluation that include our adaptive attacks to demonstrate a meaningful upper bound of watermark robustness.
Improving Generalization in Meta-RL with Imaginary Tasks from Latent Dynamics Mixture
May 28, 2021

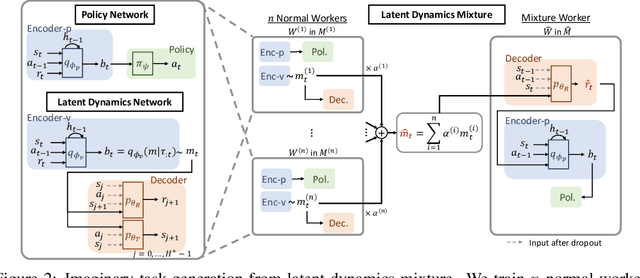

The generalization ability of most meta-reinforcement learning (meta-RL) methods is largely limited to test tasks that are sampled from the same distribution used to sample training tasks. To overcome the limitation, we propose Latent Dynamics Mixture (LDM) that trains a reinforcement learning agent with imaginary tasks generated from mixtures of learned latent dynamics. By training a policy on mixture tasks along with original training tasks, LDM allows the agent to prepare for unseen test tasks during training and prevents the agent from overfitting the training tasks. LDM significantly outperforms standard meta-RL methods in test returns on the gridworld navigation and MuJoCo tasks where we strictly separate the training task distribution and the test task distribution.
NTIRE 2021 Challenge on Video Super-Resolution
May 10, 2021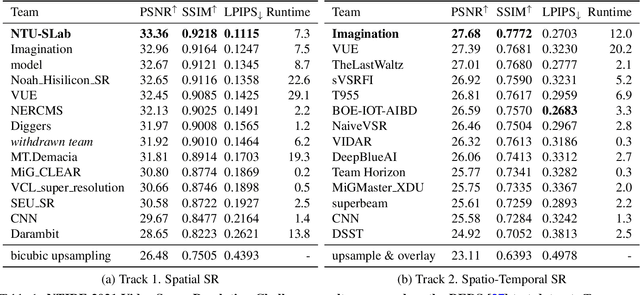


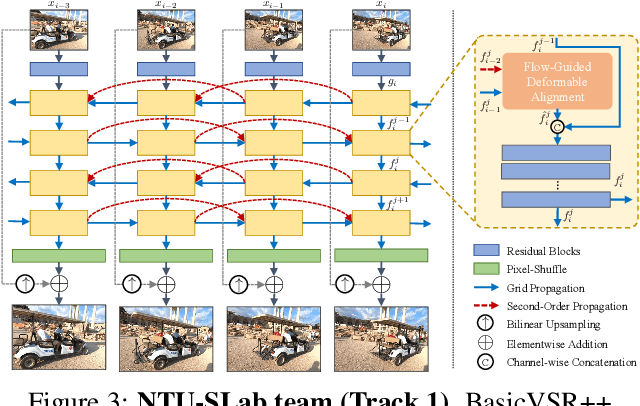
Super-Resolution (SR) is a fundamental computer vision task that aims to obtain a high-resolution clean image from the given low-resolution counterpart. This paper reviews the NTIRE 2021 Challenge on Video Super-Resolution. We present evaluation results from two competition tracks as well as the proposed solutions. Track 1 aims to develop conventional video SR methods focusing on the restoration quality. Track 2 assumes a more challenging environment with lower frame rates, casting spatio-temporal SR problem. In each competition, 247 and 223 participants have registered, respectively. During the final testing phase, 14 teams competed in each track to achieve state-of-the-art performance on video SR tasks.