 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
Grokfast: Accelerated Grokking by Amplifying Slow Gradients
May 30, 2024



One puzzling artifact in machine learning dubbed grokking is where delayed generalization is achieved tenfolds of iterations after near perfect overfitting to the training data. Focusing on the long delay itself on behalf of machine learning practitioners, our goal is to accelerate generalization of a model under grokking phenomenon. By regarding a series of gradients of a parameter over training iterations as a random signal over time, we can spectrally decompose the parameter trajectories under gradient descent into two components: the fast-varying, overfitting-yielding component and the slow-varying, generalization-inducing component. This analysis allows us to accelerate the grokking phenomenon more than $\times 50$ with only a few lines of code that amplifies the slow-varying components of gradients. The experiments show that our algorithm applies to diverse tasks involving images, languages, and graphs, enabling practical availability of this peculiar artifact of sudden generalization. Our code is available at \url{https://github.com/ironjr/grokfast}.
StreamMultiDiffusion: Real-Time Interactive Generation with Region-Based Semantic Control
Apr 01, 2024



The enormous success of diffusion models in text-to-image synthesis has made them promising candidates for the next generation of end-user applications for image generation and editing. Previous works have focused on improving the usability of diffusion models by reducing the inference time or increasing user interactivity by allowing new, fine-grained controls such as region-based text prompts. However, we empirically find that integrating both branches of works is nontrivial, limiting the potential of diffusion models. To solve this incompatibility, we present StreamMultiDiffusion, the first real-time region-based text-to-image generation framework. By stabilizing fast inference techniques and restructuring the model into a newly proposed multi-prompt stream batch architecture, we achieve $\times 10$ faster panorama generation than existing solutions, and the generation speed of 1.57 FPS in region-based text-to-image synthesis on a single RTX 2080 Ti GPU. Our solution opens up a new paradigm for interactive image generation named semantic palette, where high-quality images are generated in real-time from given multiple hand-drawn regions, encoding prescribed semantic meanings (e.g., eagle, girl). Our code and demo application are available at https://github.com/ironjr/StreamMultiDiffusion.
Rethinking RGB Color Representation for Image Restoration Models
Feb 05, 2024



Image restoration models are typically trained with a pixel-wise distance loss defined over the RGB color representation space, which is well known to be a source of blurry and unrealistic textures in the restored images. The reason, we believe, is that the three-channel RGB space is insufficient for supervising the restoration models. To this end, we augment the representation to hold structural information of local neighborhoods at each pixel while keeping the color information and pixel-grainedness unharmed. The result is a new representation space, dubbed augmented RGB ($a$RGB) space. Substituting the underlying representation space for the per-pixel losses facilitates the training of image restoration models, thereby improving the performance without affecting the evaluation phase. Notably, when combined with auxiliary objectives such as adversarial or perceptual losses, our $a$RGB space consistently improves overall metrics by reconstructing both color and local structures, overcoming the conventional perception-distortion trade-off.
LucidDreamer: Domain-free Generation of 3D Gaussian Splatting Scenes
Nov 23, 2023



With the widespread usage of VR devices and contents, demands for 3D scene generation techniques become more popular. Existing 3D scene generation models, however, limit the target scene to specific domain, primarily due to their training strategies using 3D scan dataset that is far from the real-world. To address such limitation, we propose LucidDreamer, a domain-free scene generation pipeline by fully leveraging the power of existing large-scale diffusion-based generative model. Our LucidDreamer has two alternate steps: Dreaming and Alignment. First, to generate multi-view consistent images from inputs, we set the point cloud as a geometrical guideline for each image generation. Specifically, we project a portion of point cloud to the desired view and provide the projection as a guidance for inpainting using the generative model. The inpainted images are lifted to 3D space with estimated depth maps, composing a new points. Second, to aggregate the new points into the 3D scene, we propose an aligning algorithm which harmoniously integrates the portions of newly generated 3D scenes. The finally obtained 3D scene serves as initial points for optimizing Gaussian splats. LucidDreamer produces Gaussian splats that are highly-detailed compared to the previous 3D scene generation methods, with no constraint on domain of the target scene. Project page: https://luciddreamer-cvlab.github.io/
Clean Images are Hard to Reblur: A New Clue for Deblurring
Apr 26, 2021
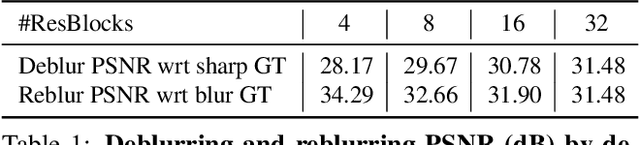

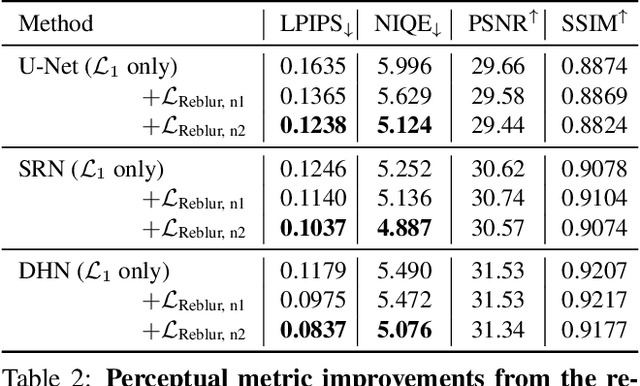
The goal of dynamic scene deblurring is to remove the motion blur present in a given image. Most learning-based approaches implement their solutions by minimizing the L1 or L2 distance between the output and reference sharp image. Recent attempts improve the perceptual quality of the deblurred image by using features learned from visual recognition tasks. However, those features are originally designed to capture the high-level contexts rather than the low-level structures of the given image, such as blurriness. We propose a novel low-level perceptual loss to make image sharper. To better focus on image blurriness, we train a reblurring module amplifying the unremoved motion blur. Motivated that a well-deblurred clean image should contain zero-magnitude motion blur that is hard to be amplified, we design two types of reblurring loss functions. The supervised reblurring loss at training stage compares the amplified blur between the deblurred image and the reference sharp image. The self-supervised reblurring loss at inference stage inspects if the deblurred image still contains noticeable blur to be amplified. Our experimental results demonstrate the proposed reblurring losses improve the perceptual quality of the deblurred images in terms of NIQE and LPIPS scores as well as visual sharpness.
AIM 2020 Challenge on Video Temporal Super-Resolution
Sep 28, 2020
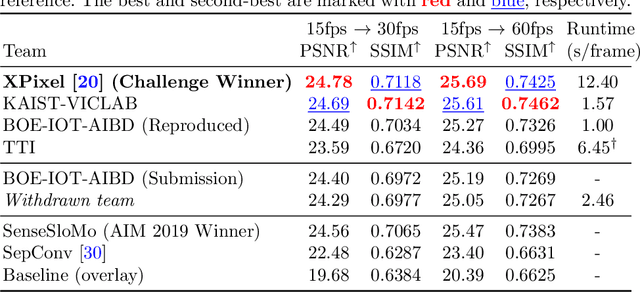

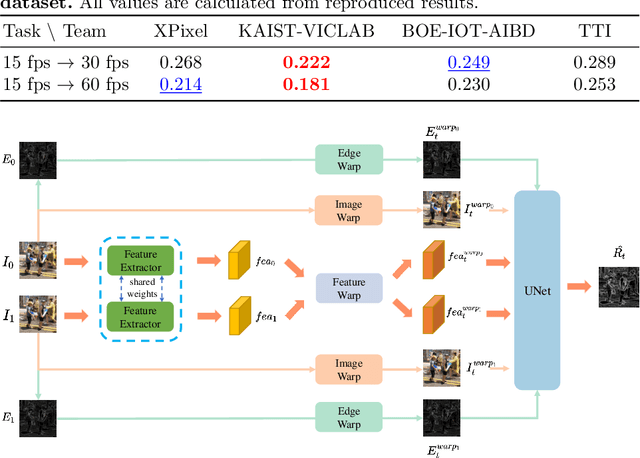
Videos in the real-world contain various dynamics and motions that may look unnaturally discontinuous in time when the recordedframe rate is low. This paper reports the second AIM challenge on Video Temporal Super-Resolution (VTSR), a.k.a. frame interpolation, with a focus on the proposed solutions, results, and analysis. From low-frame-rate (15 fps) videos, the challenge participants are required to submit higher-frame-rate (30 and 60 fps) sequences by estimating temporally intermediate frames. To simulate realistic and challenging dynamics in the real-world, we employ the REDS_VTSR dataset derived from diverse videos captured in a hand-held camera for training and evaluation purposes. There have been 68 registered participants in the competition, and 5 teams (one withdrawn) have competed in the final testing phase. The winning team proposes the enhanced quadratic video interpolation method and achieves state-of-the-art on the VTSR task.