 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamDojo: A Generalist Robot World Model from Large-Scale Human Videos
Feb 06, 2026Being able to simulate the outcomes of actions in varied environments will revolutionize the development of generalist agents at scale. However, modeling these world dynamics, especially for dexterous robotics tasks, poses significant challenges due to limited data coverage and scarce action labels. As an endeavor towards this end, we introduce DreamDojo, a foundation world model that learns diverse interactions and dexterous controls from 44k hours of egocentric human videos. Our data mixture represents the largest video dataset to date for world model pretraining, spanning a wide range of daily scenarios with diverse objects and skills. To address the scarcity of action labels, we introduce continuous latent actions as unified proxy actions, enhancing interaction knowledge transfer from unlabeled videos. After post-training on small-scale target robot data, DreamDojo demonstrates a strong understanding of physics and precise action controllability. We also devise a distillation pipeline that accelerates DreamDojo to a real-time speed of 10.81 FPS and further improves context consistency. Our work enables several important applications based on generative world models, including live teleoperation, policy evaluation, and model-based planning. Systematic evaluation on multiple challenging out-of-distribution (OOD) benchmarks verifies the significance of our method for simulating open-world, contact-rich tasks, paving the way for general-purpose robot world models.
Cosmos World Foundation Model Platform for Physical AI
Jan 07, 2025



Physical AI needs to be trained digitally first. It needs a digital twin of itself, the policy model, and a digital twin of the world, the world model. In this paper, we present the Cosmos World Foundation Model Platform to help developers build customized world models for their Physical AI setups. We position a world foundation model as a general-purpose world model that can be fine-tuned into customized world models for downstream applications. Our platform covers a video curation pipeline, pre-trained world foundation models, examples of post-training of pre-trained world foundation models, and video tokenizers. To help Physical AI builders solve the most critical problems of our society, we make our platform open-source and our models open-weight with permissive licenses available via https://github.com/NVIDIA/Cosmos.
Edify Image: High-Quality Image Generation with Pixel Space Laplacian Diffusion Models
Nov 11, 2024We introduce Edify Image, a family of diffusion models capable of generating photorealistic image content with pixel-perfect accuracy. Edify Image utilizes cascaded pixel-space diffusion models trained using a novel Laplacian diffusion process, in which image signals at different frequency bands are attenuated at varying rates. Edify Image supports a wide range of applications, including text-to-image synthesis, 4K upsampling, ControlNets, 360 HDR panorama generation, and finetuning for image customization.
Preserve Your Own Correlation: A Noise Prior for Video Diffusion Models
May 17, 2023Despite tremendous progress in generating high-quality images using diffusion models, synthesizing a sequence of animated frames that are both photorealistic and temporally coherent is still in its infancy. While off-the-shelf billion-scale datasets for image generation are available, collecting similar video data of the same scale is still challenging. Also, training a video diffusion model is computationally much more expensive than its image counterpart. In this work, we explore finetuning a pretrained image diffusion model with video data as a practical solution for the video synthesis task. We find that naively extending the image noise prior to video noise prior in video diffusion leads to sub-optimal performance. Our carefully designed video noise prior leads to substantially better performance. Extensive experimental validation shows that our model, Preserve Your Own Correlation (PYoCo), attains SOTA zero-shot text-to-video results on the UCF-101 and MSR-VTT benchmarks. It also achieves SOTA video generation quality on the small-scale UCF-101 benchmark with a $10\times$ smaller model using significantly less computation than the prior art.
eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
Nov 17, 2022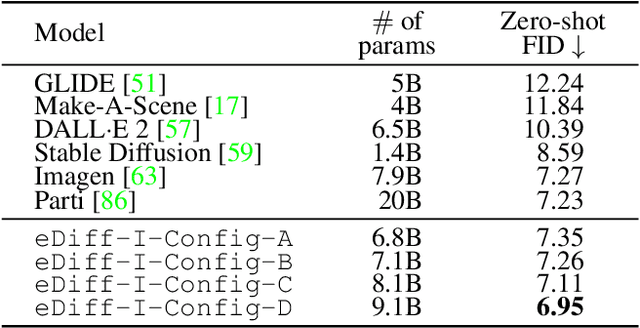



Large-scale diffusion-based generative models have led to breakthroughs in text-conditioned high-resolution image synthesis. Starting from random noise, such text-to-image diffusion models gradually synthesize images in an iterative fashion while conditioning on text prompts. We find that their synthesis behavior qualitatively changes throughout this process: Early in sampling, generation strongly relies on the text prompt to generate text-aligned content, while later, the text conditioning is almost entirely ignored. This suggests that sharing model parameters throughout the entire generation process may not be ideal. Therefore, in contrast to existing works, we propose to train an ensemble of text-to-image diffusion models specialized for different synthesis stages. To maintain training efficiency, we initially train a single model, which is then split into specialized models that are trained for the specific stages of the iterative generation process. Our ensemble of diffusion models, called eDiff-I, results in improved text alignment while maintaining the same inference computation cost and preserving high visual quality, outperforming previous large-scale text-to-image diffusion models on the standard benchmark. In addition, we train our model to exploit a variety of embeddings for conditioning, including the T5 text, CLIP text, and CLIP image embeddings. We show that these different embeddings lead to different behaviors. Notably, the CLIP image embedding allows an intuitive way of transferring the style of a reference image to the target text-to-image output. Lastly, we show a technique that enables eDiff-I's "paint-with-words" capability. A user can select the word in the input text and paint it in a canvas to control the output, which is very handy for crafting the desired image in mind. The project page is available at https://deepimagination.cc/eDiff-I/
CADyQ: Content-Aware Dynamic Quantization for Image Super-Resolution
Jul 21, 2022
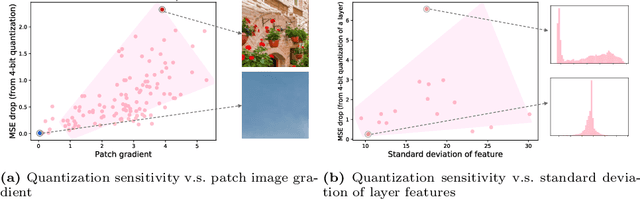
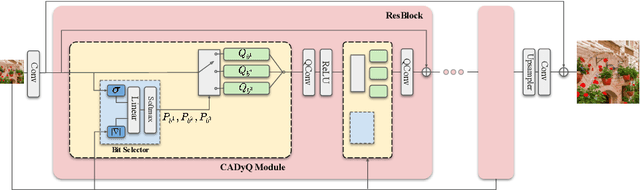
Despite breakthrough advances in image super-resolution (SR) with convolutional neural networks (CNNs), SR has yet to enjoy ubiquitous applications due to the high computational complexity of SR networks. Quantization is one of the promising approaches to solve this problem. However, existing methods fail to quantize SR models with a bit-width lower than 8 bits, suffering from severe accuracy loss due to fixed bit-width quantization applied everywhere. In this work, to achieve high average bit-reduction with less accuracy loss, we propose a novel Content-Aware Dynamic Quantization (CADyQ) method for SR networks that allocates optimal bits to local regions and layers adaptively based on the local contents of an input image. To this end, a trainable bit selector module is introduced to determine the proper bit-width and quantization level for each layer and a given local image patch. This module is governed by the quantization sensitivity that is estimated by using both the average magnitude of image gradient of the patch and the standard deviation of the input feature of the layer. The proposed quantization pipeline has been tested on various SR networks and evaluated on several standard benchmarks extensively. Significant reduction in computational complexity and the elevated restoration accuracy clearly demonstrate the effectiveness of the proposed CADyQ framework for SR. Codes are available at https://github.com/Cheeun/CADyQ.
Attentive Fine-Grained Structured Sparsity for Image Restoration
Apr 26, 2022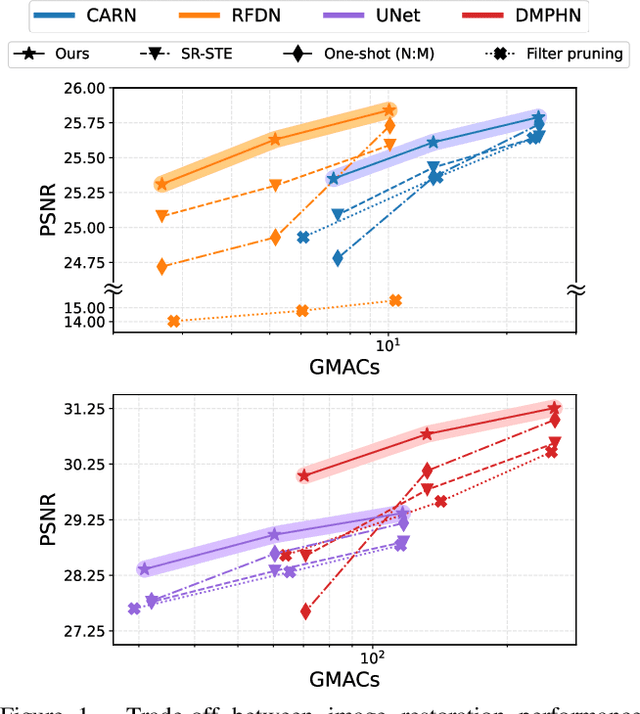
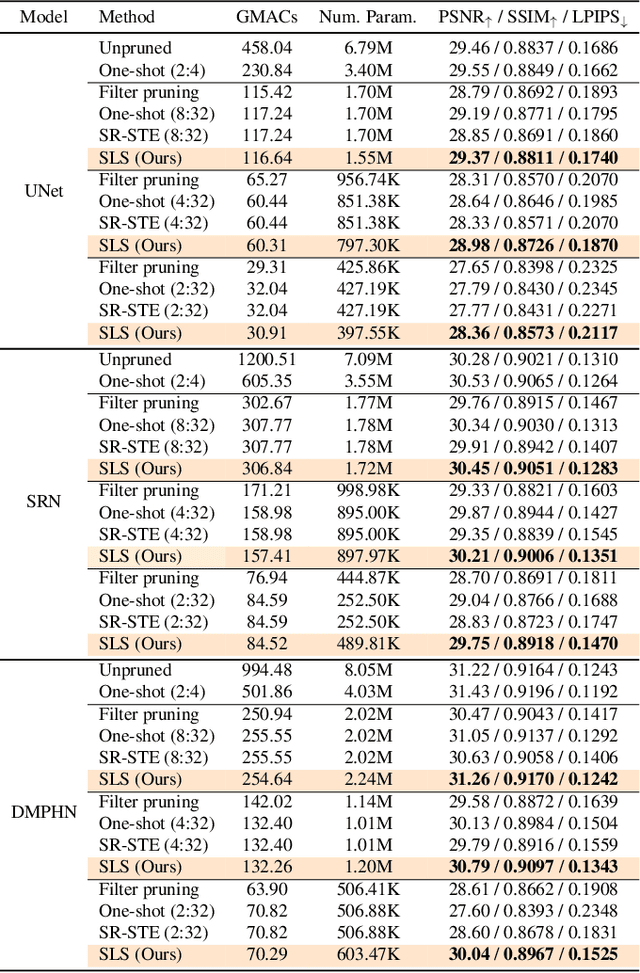
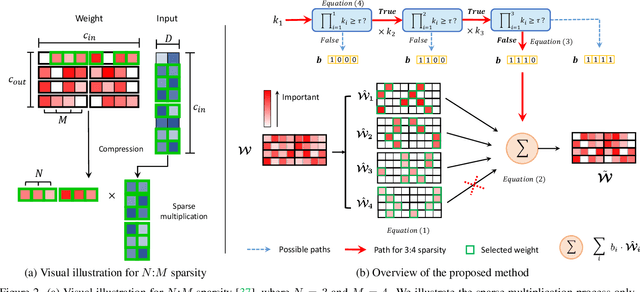
Image restoration tasks have witnessed great performance improvement in recent years by developing large deep models. Despite the outstanding performance, the heavy computation demanded by the deep models has restricted the application of image restoration. To lift the restriction, it is required to reduce the size of the networks while maintaining accuracy. Recently, N:M structured pruning has appeared as one of the effective and practical pruning approaches for making the model efficient with the accuracy constraint. However, it fails to account for different computational complexities and performance requirements for different layers of an image restoration network. To further optimize the trade-off between the efficiency and the restoration accuracy, we propose a novel pruning method that determines the pruning ratio for N:M structured sparsity at each layer. Extensive experimental results on super-resolution and deblurring tasks demonstrate the efficacy of our method which outperforms previous pruning methods significantly. PyTorch implementation for the proposed methods will be publicly available at https://github.com/JungHunOh/SLS_CVPR2022.
Pay Attention to Hidden States for Video Deblurring: Ping-Pong Recurrent Neural Networks and Selective Non-Local Attention
Apr 07, 2022
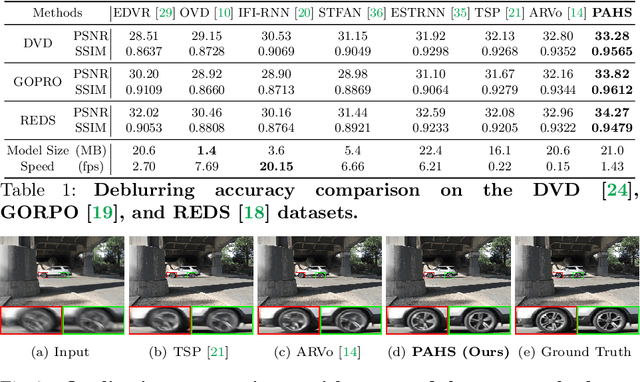
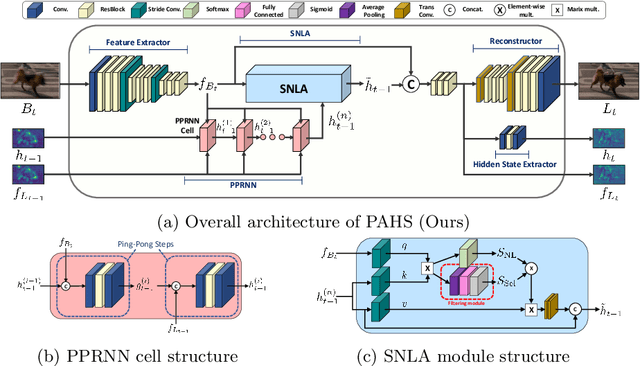

Video deblurring models exploit information in the neighboring frames to remove blur caused by the motion of the camera and the objects. Recurrent Neural Networks~(RNNs) are often adopted to model the temporal dependency between frames via hidden states. When motion blur is strong, however, hidden states are hard to deliver proper information due to the displacement between different frames. While there have been attempts to update the hidden states, it is difficult to handle misaligned features beyond the receptive field of simple modules. Thus, we propose 2 modules to supplement the RNN architecture for video deblurring. First, we design Ping-Pong RNN~(PPRNN) that acts on updating the hidden states by referring to the features from the current and the previous time steps alternately. PPRNN gathers relevant information from the both features in an iterative and balanced manner by utilizing its recurrent architecture. Second, we use a Selective Non-Local Attention~(SNLA) module to additionally refine the hidden state by aligning it with the positional information from the input frame feature. The attention score is scaled by the relevance to the input feature to focus on the necessary information. By paying attention to hidden states with both modules, which have strong synergy, our PAHS framework improves the representation powers of RNN structures and achieves state-of-the-art deblurring performance on standard benchmarks and real-world videos.
Recurrence-in-Recurrence Networks for Video Deblurring
Mar 12, 2022
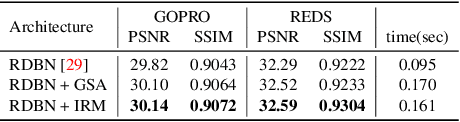
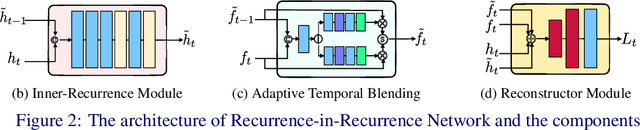
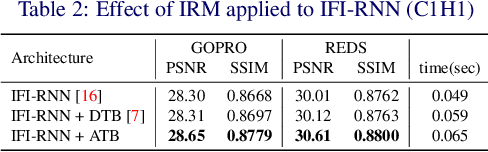
State-of-the-art video deblurring methods often adopt recurrent neural networks to model the temporal dependency between the frames. While the hidden states play key role in delivering information to the next frame, abrupt motion blur tend to weaken the relevance in the neighbor frames. In this paper, we propose recurrence-in-recurrence network architecture to cope with the limitations of short-ranged memory. We employ additional recurrent units inside the RNN cell. First, we employ inner-recurrence module (IRM) to manage the long-ranged dependency in a sequence. IRM learns to keep track of the cell memory and provides complementary information to find the deblurred frames. Second, we adopt an attention-based temporal blending strategy to extract the necessary part of the information in the local neighborhood. The adpative temporal blending (ATB) can either attenuate or amplify the features by the spatial attention. Our extensive experimental results and analysis validate the effectiveness of IRM and ATB on various RNN architectures.
* accepted paper in BMVC 2021
NTIRE 2021 Challenge on Video Super-Resolution
May 10, 2021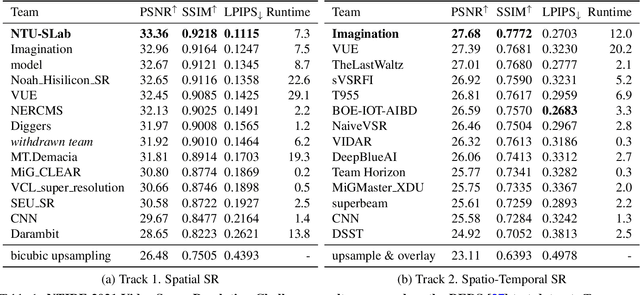


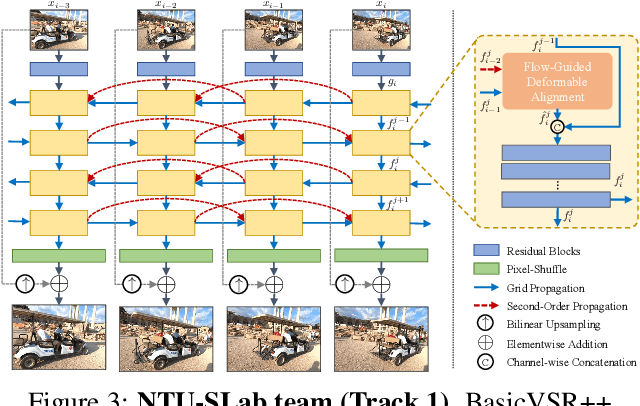
Super-Resolution (SR) is a fundamental computer vision task that aims to obtain a high-resolution clean image from the given low-resolution counterpart. This paper reviews the NTIRE 2021 Challenge on Video Super-Resolution. We present evaluation results from two competition tracks as well as the proposed solutions. Track 1 aims to develop conventional video SR methods focusing on the restoration quality. Track 2 assumes a more challenging environment with lower frame rates, casting spatio-temporal SR problem. In each competition, 247 and 223 participants have registered, respectively. During the final testing phase, 14 teams competed in each track to achieve state-of-the-art performance on video SR tasks.