 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSneakPeek: Future-Guided Instructional Streaming Video Generation
Dec 15, 2025Instructional video generation is an emerging task that aims to synthesize coherent demonstrations of procedural activities from textual descriptions. Such capability has broad implications for content creation, education, and human-AI interaction, yet existing video diffusion models struggle to maintain temporal consistency and controllability across long sequences of multiple action steps. We introduce a pipeline for future-driven streaming instructional video generation, dubbed SneakPeek, a diffusion-based autoregressive framework designed to generate precise, stepwise instructional videos conditioned on an initial image and structured textual prompts. Our approach introduces three key innovations to enhance consistency and controllability: (1) predictive causal adaptation, where a causal model learns to perform next-frame prediction and anticipate future keyframes; (2) future-guided self-forcing with a dual-region KV caching scheme to address the exposure bias issue at inference time; (3) multi-prompt conditioning, which provides fine-grained and procedural control over multi-step instructions. Together, these components mitigate temporal drift, preserve motion consistency, and enable interactive video generation where future prompt updates dynamically influence ongoing streaming video generation. Experimental results demonstrate that our method produces temporally coherent and semantically faithful instructional videos that accurately follow complex, multi-step task descriptions.
AdaBM: On-the-Fly Adaptive Bit Mapping for Image Super-Resolution
Apr 04, 2024Although image super-resolution (SR) problem has experienced unprecedented restoration accuracy with deep neural networks, it has yet limited versatile applications due to the substantial computational costs. Since different input images for SR face different restoration difficulties, adapting computational costs based on the input image, referred to as adaptive inference, has emerged as a promising solution to compress SR networks. Specifically, adapting the quantization bit-widths has successfully reduced the inference and memory cost without sacrificing the accuracy. However, despite the benefits of the resultant adaptive network, existing works rely on time-intensive quantization-aware training with full access to the original training pairs to learn the appropriate bit allocation policies, which limits its ubiquitous usage. To this end, we introduce the first on-the-fly adaptive quantization framework that accelerates the processing time from hours to seconds. We formulate the bit allocation problem with only two bit mapping modules: one to map the input image to the image-wise bit adaptation factor and one to obtain the layer-wise adaptation factors. These bit mappings are calibrated and fine-tuned using only a small number of calibration images. We achieve competitive performance with the previous adaptive quantization methods, while the processing time is accelerated by x2000. Codes are available at https://github.com/Cheeun/AdaBM.
Overcoming Distribution Mismatch in Quantizing Image Super-Resolution Networks
Jul 25, 2023Quantization is a promising approach to reduce the high computational complexity of image super-resolution (SR) networks. However, compared to high-level tasks like image classification, low-bit quantization leads to severe accuracy loss in SR networks. This is because feature distributions of SR networks are significantly divergent for each channel or input image, and is thus difficult to determine a quantization range. Existing SR quantization works approach this distribution mismatch problem by dynamically adapting quantization ranges to the variant distributions during test time. However, such dynamic adaptation incurs additional computational costs that limit the benefits of quantization. Instead, we propose a new quantization-aware training framework that effectively Overcomes the Distribution Mismatch problem in SR networks without the need for dynamic adaptation. Intuitively, the mismatch can be reduced by directly regularizing the variance in features during training. However, we observe that variance regularization can collide with the reconstruction loss during training and adversely impact SR accuracy. Thus, we avoid the conflict between two losses by regularizing the variance only when the gradients of variance regularization are cooperative with that of reconstruction. Additionally, to further reduce the distribution mismatch, we introduce distribution offsets to layers with a significant mismatch, which either scales or shifts channel-wise features. Our proposed algorithm, called ODM, effectively reduces the mismatch in distributions with minimal computational overhead. Experimental results show that ODM effectively outperforms existing SR quantization approaches with similar or fewer computations, demonstrating the importance of reducing the distribution mismatch problem. Our code is available at https://github.com/Cheeun/ODM.
CADyQ: Content-Aware Dynamic Quantization for Image Super-Resolution
Jul 21, 2022
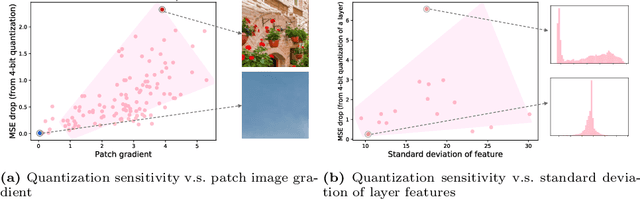
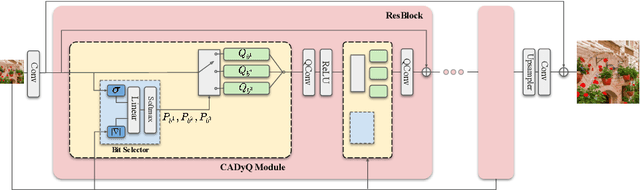
Despite breakthrough advances in image super-resolution (SR) with convolutional neural networks (CNNs), SR has yet to enjoy ubiquitous applications due to the high computational complexity of SR networks. Quantization is one of the promising approaches to solve this problem. However, existing methods fail to quantize SR models with a bit-width lower than 8 bits, suffering from severe accuracy loss due to fixed bit-width quantization applied everywhere. In this work, to achieve high average bit-reduction with less accuracy loss, we propose a novel Content-Aware Dynamic Quantization (CADyQ) method for SR networks that allocates optimal bits to local regions and layers adaptively based on the local contents of an input image. To this end, a trainable bit selector module is introduced to determine the proper bit-width and quantization level for each layer and a given local image patch. This module is governed by the quantization sensitivity that is estimated by using both the average magnitude of image gradient of the patch and the standard deviation of the input feature of the layer. The proposed quantization pipeline has been tested on various SR networks and evaluated on several standard benchmarks extensively. Significant reduction in computational complexity and the elevated restoration accuracy clearly demonstrate the effectiveness of the proposed CADyQ framework for SR. Codes are available at https://github.com/Cheeun/CADyQ.
Attentive Fine-Grained Structured Sparsity for Image Restoration
Apr 26, 2022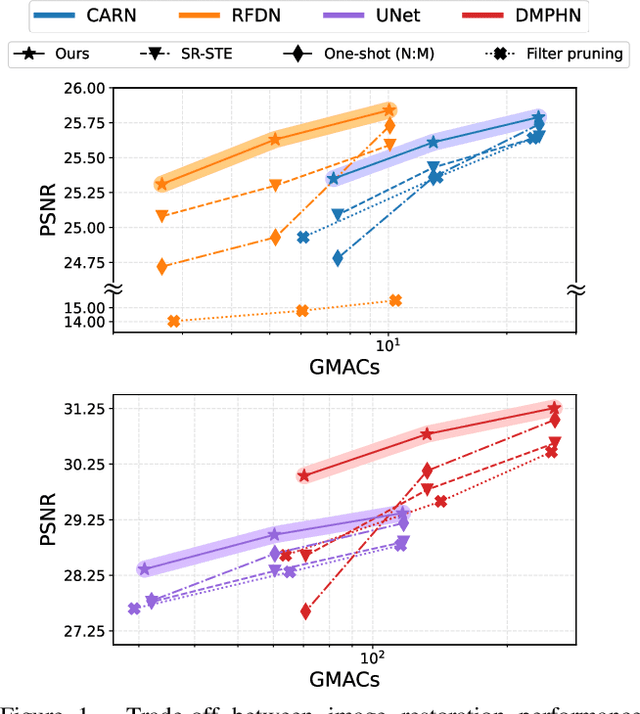
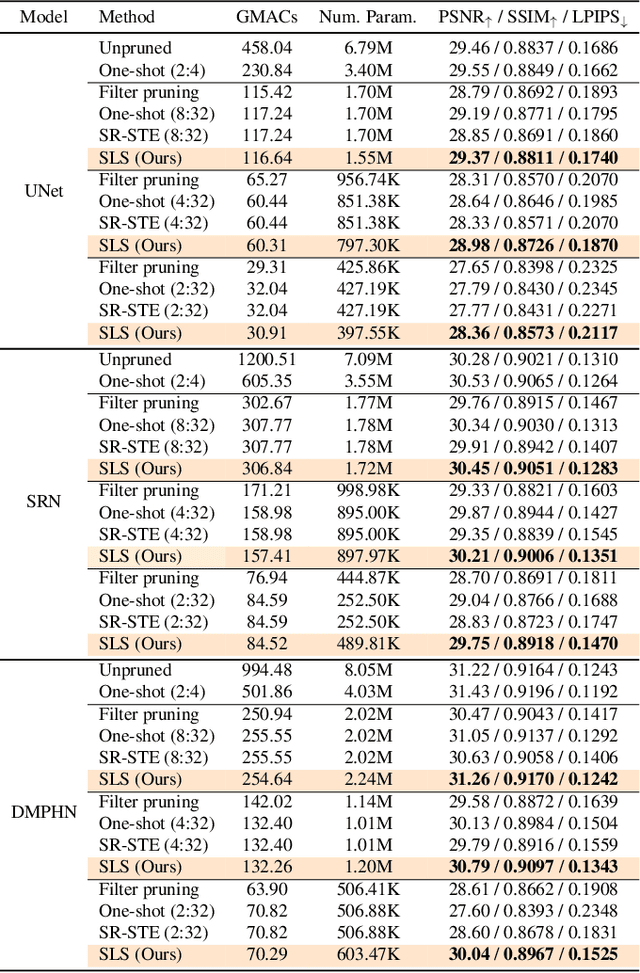
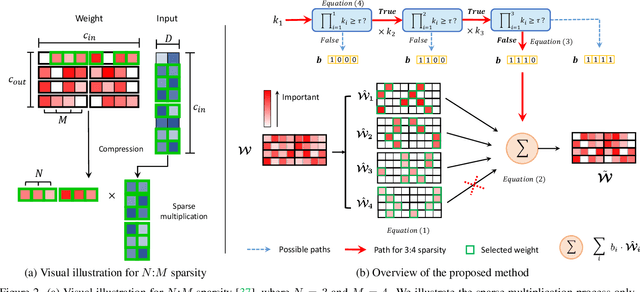
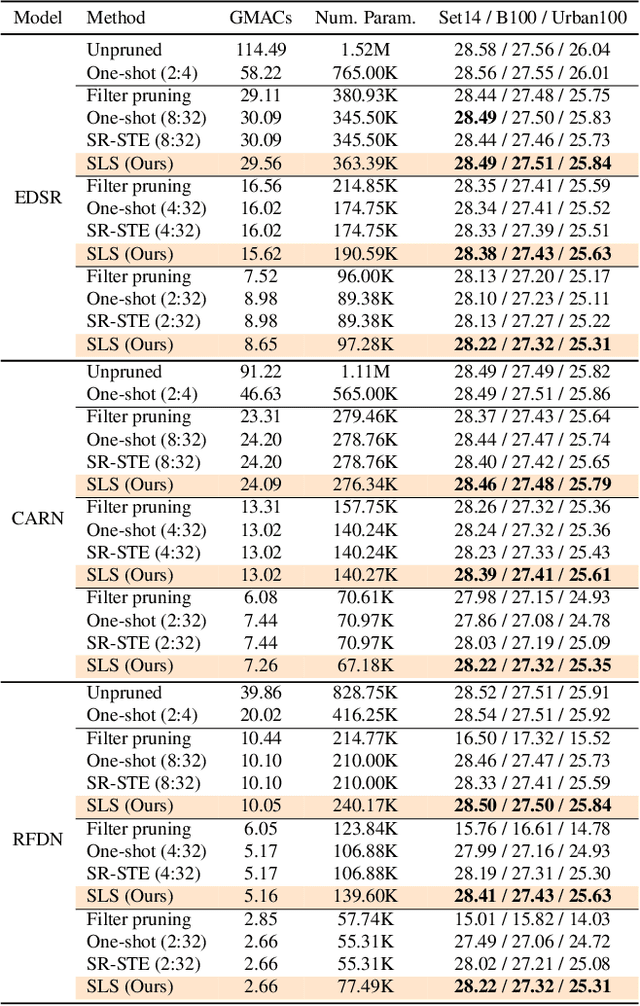
Image restoration tasks have witnessed great performance improvement in recent years by developing large deep models. Despite the outstanding performance, the heavy computation demanded by the deep models has restricted the application of image restoration. To lift the restriction, it is required to reduce the size of the networks while maintaining accuracy. Recently, N:M structured pruning has appeared as one of the effective and practical pruning approaches for making the model efficient with the accuracy constraint. However, it fails to account for different computational complexities and performance requirements for different layers of an image restoration network. To further optimize the trade-off between the efficiency and the restoration accuracy, we propose a novel pruning method that determines the pruning ratio for N:M structured sparsity at each layer. Extensive experimental results on super-resolution and deblurring tasks demonstrate the efficacy of our method which outperforms previous pruning methods significantly. PyTorch implementation for the proposed methods will be publicly available at https://github.com/JungHunOh/SLS_CVPR2022.
Batch Normalization Tells You Which Filter is Important
Dec 02, 2021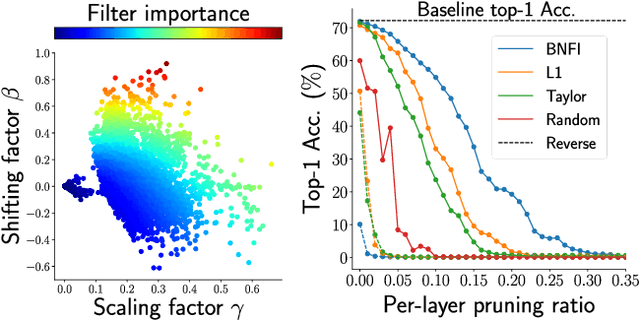
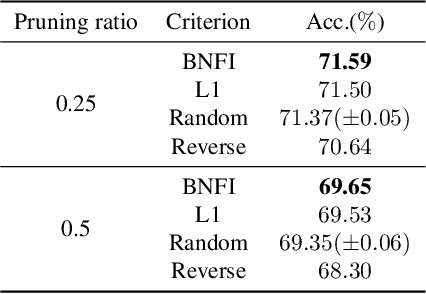
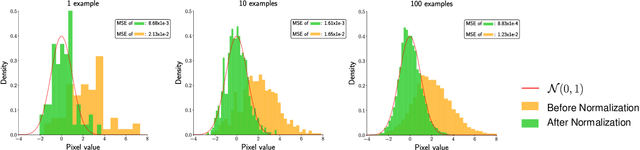
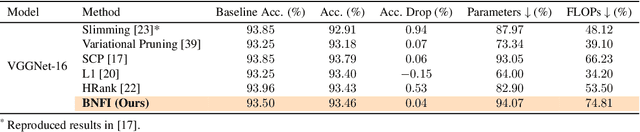
The goal of filter pruning is to search for unimportant filters to remove in order to make convolutional neural networks (CNNs) efficient without sacrificing the performance in the process. The challenge lies in finding information that can help determine how important or relevant each filter is with respect to the final output of neural networks. In this work, we share our observation that the batch normalization (BN) parameters of pre-trained CNNs can be used to estimate the feature distribution of activation outputs, without processing of training data. Upon observation, we propose a simple yet effective filter pruning method by evaluating the importance of each filter based on the BN parameters of pre-trained CNNs. The experimental results on CIFAR-10 and ImageNet demonstrate that the proposed method can achieve outstanding performance with and without fine-tuning in terms of the trade-off between the accuracy drop and the reduction in computational complexity and number of parameters of pruned networks.
DAQ: Distribution-Aware Quantization for Deep Image Super-Resolution Networks
Dec 21, 2020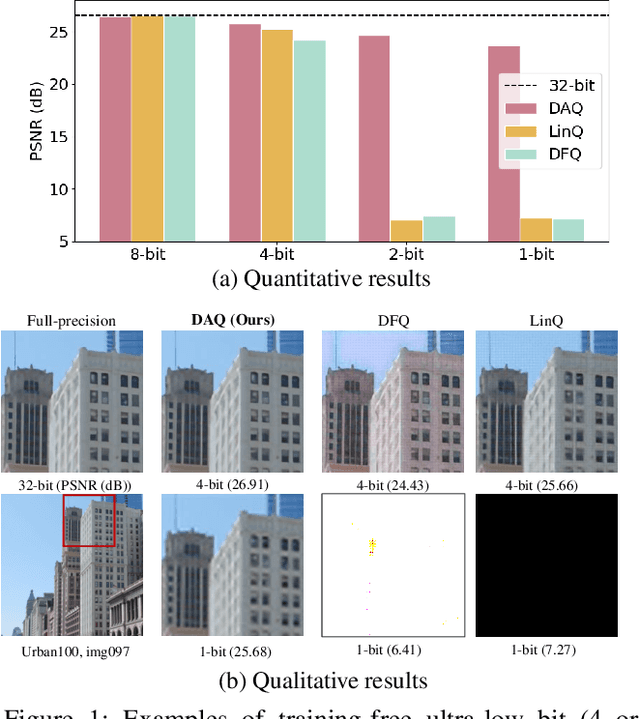

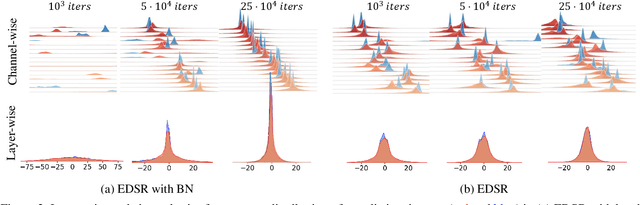
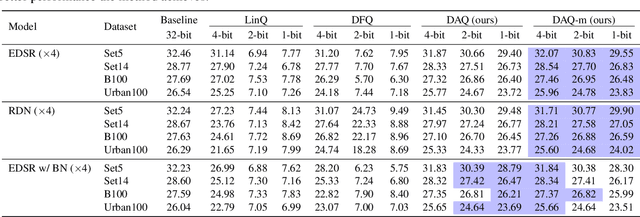
Quantizing deep convolutional neural networks for image super-resolution substantially reduces their computational costs. However, existing works either suffer from a severe performance drop in ultra-low precision of 4 or lower bit-widths, or require a heavy fine-tuning process to recover the performance. To our knowledge, this vulnerability to low precisions relies on two statistical observations of feature map values. First, distribution of feature map values varies significantly per channel and per input image. Second, feature maps have outliers that can dominate the quantization error. Based on these observations, we propose a novel distribution-aware quantization scheme (DAQ) which facilitates accurate training-free quantization in ultra-low precision. A simple function of DAQ determines dynamic range of feature maps and weights with low computational burden. Furthermore, our method enables mixed-precision quantization by calculating the relative sensitivity of each channel, without any training process involved. Nonetheless, quantization-aware training is also applicable for auxiliary performance gain. Our new method outperforms recent training-free and even training-based quantization methods to the state-of-the-art image super-resolution networks in ultra-low precision.