 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding a Diffusion Model with a Bad Version of Itself
Jun 04, 2024

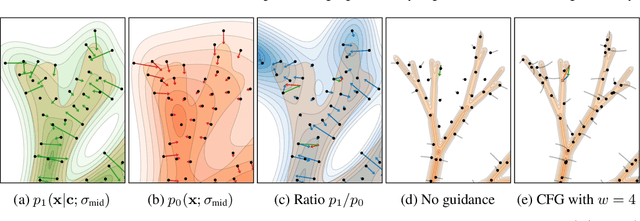
The primary axes of interest in image-generating diffusion models are image quality, the amount of variation in the results, and how well the results align with a given condition, e.g., a class label or a text prompt. The popular classifier-free guidance approach uses an unconditional model to guide a conditional model, leading to simultaneously better prompt alignment and higher-quality images at the cost of reduced variation. These effects seem inherently entangled, and thus hard to control. We make the surprising observation that it is possible to obtain disentangled control over image quality without compromising the amount of variation by guiding generation using a smaller, less-trained version of the model itself rather than an unconditional model. This leads to significant improvements in ImageNet generation, setting record FIDs of 1.01 for 64x64 and 1.25 for 512x512, using publicly available networks. Furthermore, the method is also applicable to unconditional diffusion models, drastically improving their quality.
Applying Guidance in a Limited Interval Improves Sample and Distribution Quality in Diffusion Models
Apr 11, 2024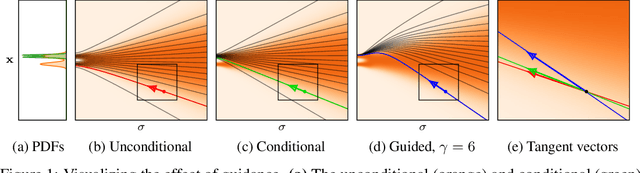



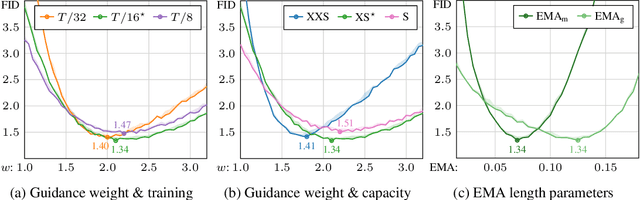
Guidance is a crucial technique for extracting the best performance out of image-generating diffusion models. Traditionally, a constant guidance weight has been applied throughout the sampling chain of an image. We show that guidance is clearly harmful toward the beginning of the chain (high noise levels), largely unnecessary toward the end (low noise levels), and only beneficial in the middle. We thus restrict it to a specific range of noise levels, improving both the inference speed and result quality. This limited guidance interval improves the record FID in ImageNet-512 significantly, from 1.81 to 1.40. We show that it is quantitatively and qualitatively beneficial across different sampler parameters, network architectures, and datasets, including the large-scale setting of Stable Diffusion XL. We thus suggest exposing the guidance interval as a hyperparameter in all diffusion models that use guidance.
Analyzing and Improving the Training Dynamics of Diffusion Models
Dec 05, 2023Diffusion models currently dominate the field of data-driven image synthesis with their unparalleled scaling to large datasets. In this paper, we identify and rectify several causes for uneven and ineffective training in the popular ADM diffusion model architecture, without altering its high-level structure. Observing uncontrolled magnitude changes and imbalances in both the network activations and weights over the course of training, we redesign the network layers to preserve activation, weight, and update magnitudes on expectation. We find that systematic application of this philosophy eliminates the observed drifts and imbalances, resulting in considerably better networks at equal computational complexity. Our modifications improve the previous record FID of 2.41 in ImageNet-512 synthesis to 1.81, achieved using fast deterministic sampling. As an independent contribution, we present a method for setting the exponential moving average (EMA) parameters post-hoc, i.e., after completing the training run. This allows precise tuning of EMA length without the cost of performing several training runs, and reveals its surprising interactions with network architecture, training time, and guidance.
StyleGAN-T: Unlocking the Power of GANs for Fast Large-Scale Text-to-Image Synthesis
Jan 23, 2023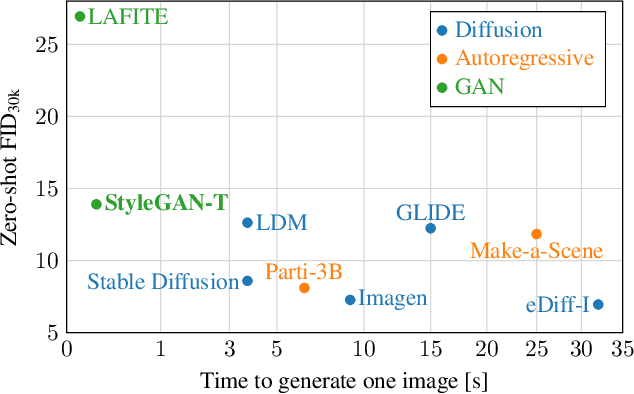
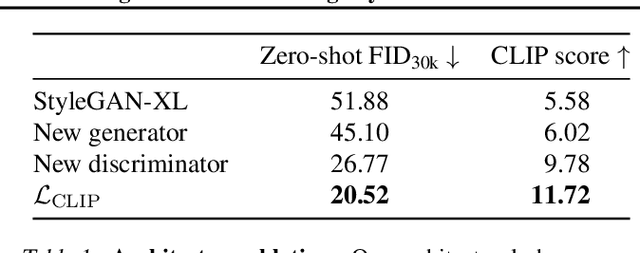

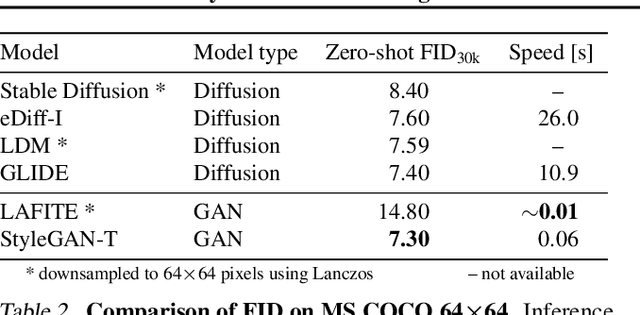
Text-to-image synthesis has recently seen significant progress thanks to large pretrained language models, large-scale training data, and the introduction of scalable model families such as diffusion and autoregressive models. However, the best-performing models require iterative evaluation to generate a single sample. In contrast, generative adversarial networks (GANs) only need a single forward pass. They are thus much faster, but they currently remain far behind the state-of-the-art in large-scale text-to-image synthesis. This paper aims to identify the necessary steps to regain competitiveness. Our proposed model, StyleGAN-T, addresses the specific requirements of large-scale text-to-image synthesis, such as large capacity, stable training on diverse datasets, strong text alignment, and controllable variation vs. text alignment tradeoff. StyleGAN-T significantly improves over previous GANs and outperforms distilled diffusion models - the previous state-of-the-art in fast text-to-image synthesis - in terms of sample quality and speed.
eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
Nov 17, 2022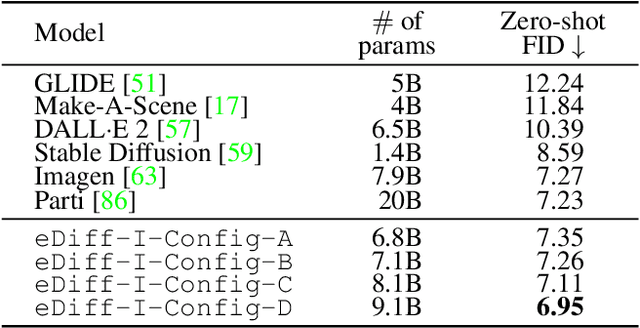



Large-scale diffusion-based generative models have led to breakthroughs in text-conditioned high-resolution image synthesis. Starting from random noise, such text-to-image diffusion models gradually synthesize images in an iterative fashion while conditioning on text prompts. We find that their synthesis behavior qualitatively changes throughout this process: Early in sampling, generation strongly relies on the text prompt to generate text-aligned content, while later, the text conditioning is almost entirely ignored. This suggests that sharing model parameters throughout the entire generation process may not be ideal. Therefore, in contrast to existing works, we propose to train an ensemble of text-to-image diffusion models specialized for different synthesis stages. To maintain training efficiency, we initially train a single model, which is then split into specialized models that are trained for the specific stages of the iterative generation process. Our ensemble of diffusion models, called eDiff-I, results in improved text alignment while maintaining the same inference computation cost and preserving high visual quality, outperforming previous large-scale text-to-image diffusion models on the standard benchmark. In addition, we train our model to exploit a variety of embeddings for conditioning, including the T5 text, CLIP text, and CLIP image embeddings. We show that these different embeddings lead to different behaviors. Notably, the CLIP image embedding allows an intuitive way of transferring the style of a reference image to the target text-to-image output. Lastly, we show a technique that enables eDiff-I's "paint-with-words" capability. A user can select the word in the input text and paint it in a canvas to control the output, which is very handy for crafting the desired image in mind. The project page is available at https://deepimagination.cc/eDiff-I/
Disentangling Random and Cyclic Effects in Time-Lapse Sequences
Jul 04, 2022
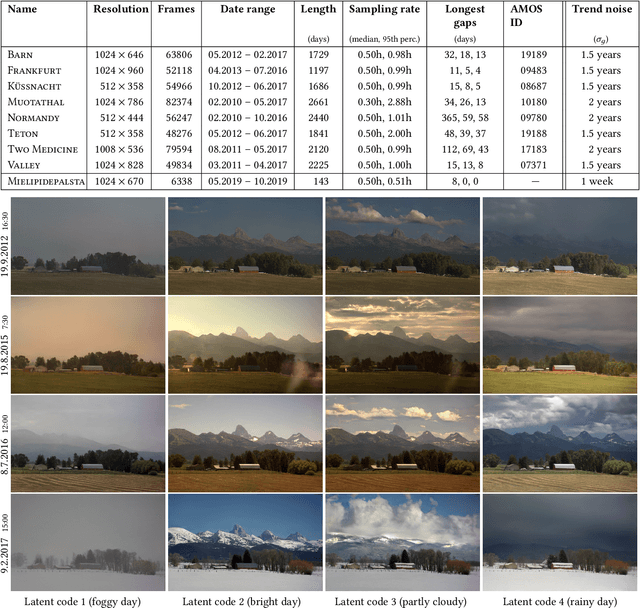


Time-lapse image sequences offer visually compelling insights into dynamic processes that are too slow to observe in real time. However, playing a long time-lapse sequence back as a video often results in distracting flicker due to random effects, such as weather, as well as cyclic effects, such as the day-night cycle. We introduce the problem of disentangling time-lapse sequences in a way that allows separate, after-the-fact control of overall trends, cyclic effects, and random effects in the images, and describe a technique based on data-driven generative models that achieves this goal. This enables us to "re-render" the sequences in ways that would not be possible with the input images alone. For example, we can stabilize a long sequence to focus on plant growth over many months, under selectable, consistent weather. Our approach is based on Generative Adversarial Networks (GAN) that are conditioned with the time coordinate of the time-lapse sequence. Our architecture and training procedure are designed so that the networks learn to model random variations, such as weather, using the GAN's latent space, and to disentangle overall trends and cyclic variations by feeding the conditioning time label to the model using Fourier features with specific frequencies. We show that our models are robust to defects in the training data, enabling us to amend some of the practical difficulties in capturing long time-lapse sequences, such as temporary occlusions, uneven frame spacing, and missing frames.
Generating Long Videos of Dynamic Scenes
Jun 09, 2022

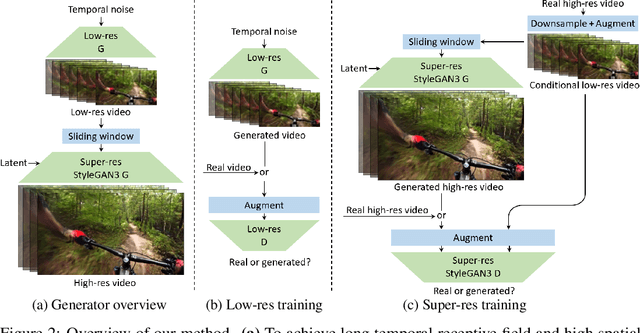

We present a video generation model that accurately reproduces object motion, changes in camera viewpoint, and new content that arises over time. Existing video generation methods often fail to produce new content as a function of time while maintaining consistencies expected in real environments, such as plausible dynamics and object persistence. A common failure case is for content to never change due to over-reliance on inductive biases to provide temporal consistency, such as a single latent code that dictates content for the entire video. On the other extreme, without long-term consistency, generated videos may morph unrealistically between different scenes. To address these limitations, we prioritize the time axis by redesigning the temporal latent representation and learning long-term consistency from data by training on longer videos. To this end, we leverage a two-phase training strategy, where we separately train using longer videos at a low resolution and shorter videos at a high resolution. To evaluate the capabilities of our model, we introduce two new benchmark datasets with explicit focus on long-term temporal dynamics.
Elucidating the Design Space of Diffusion-Based Generative Models
Jun 01, 2022

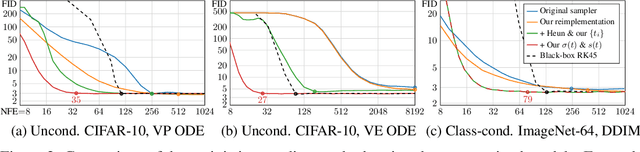

We argue that the theory and practice of diffusion-based generative models are currently unnecessarily convoluted and seek to remedy the situation by presenting a design space that clearly separates the concrete design choices. This lets us identify several changes to both the sampling and training processes, as well as preconditioning of the score networks. Together, our improvements yield new state-of-the-art FID of 1.79 for CIFAR-10 in a class-conditional setting and 1.97 in an unconditional setting, with much faster sampling (35 network evaluations per image) than prior designs. To further demonstrate their modular nature, we show that our design changes dramatically improve both the efficiency and quality obtainable with pre-trained score networks from previous work, including improving the FID of an existing ImageNet-64 model from 2.07 to near-SOTA 1.55.
The Role of ImageNet Classes in Fréchet Inception Distance
Mar 11, 2022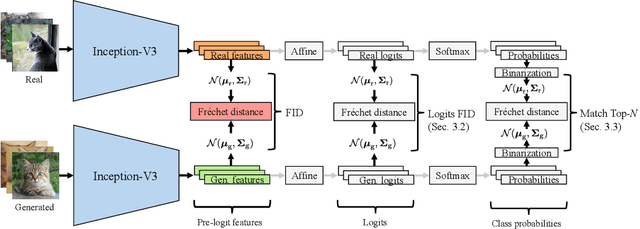
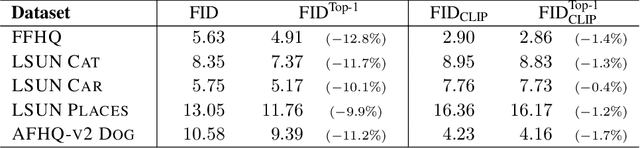
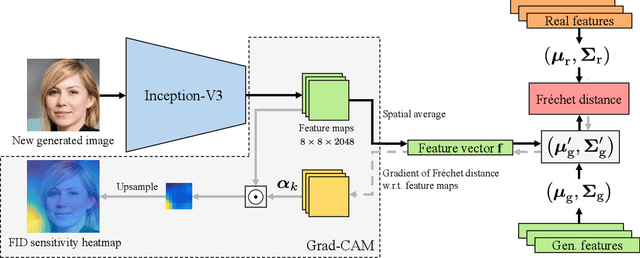

Fr\'echet Inception Distance (FID) is a metric for quantifying the distance between two distributions of images. Given its status as a standard yardstick for ranking models in data-driven generative modeling research, it seems important that the distance is computed from general, "vision-related" features. But is it? We observe that FID is essentially a distance between sets of ImageNet class probabilities. We trace the reason to the fact that the standard feature space, the penultimate "pre-logit" layer of a particular Inception-V3 classifier network, is only one affine transform away from the logits, i.e., ImageNet classes, and thus, the features are necessarily highly specialized to them. This has unintuitive consequences for the metric's sensitivity. For example, when evaluating a model for human faces, we observe that, on average, FID is actually very insensitive to the facial region, and that the probabilities of classes like "bow tie" or "seat belt" play a much larger role. Further, we show that FID can be significantly reduced -- without actually improving the quality of results -- by an attack that first generates a slightly larger set of candidates, and then chooses a subset that happens to match the histogram of such "fringe features" in the real data. We then demonstrate that this observation has practical relevance in case of ImageNet pre-training of GANs, where a part of the observed FID improvement turns out not to be real. Our results suggest caution against over-interpreting FID improvements, and underline the need for distribution metrics that are more perceptually uniform.
Alias-Free Generative Adversarial Networks
Jul 15, 2021
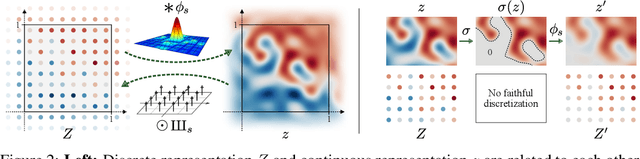
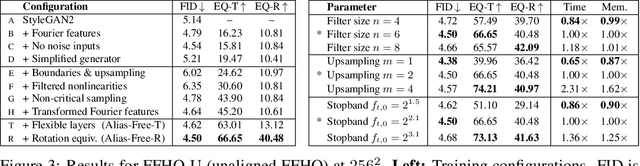
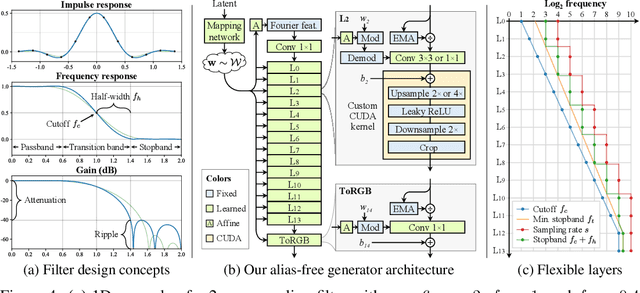
We observe that despite their hierarchical convolutional nature, the synthesis process of typical generative adversarial networks depends on absolute pixel coordinates in an unhealthy manner. This manifests itself as, e.g., detail appearing to be glued to image coordinates instead of the surfaces of depicted objects. We trace the root cause to careless signal processing that causes aliasing in the generator network. Interpreting all signals in the network as continuous, we derive generally applicable, small architectural changes that guarantee that unwanted information cannot leak into the hierarchical synthesis process. The resulting networks match the FID of StyleGAN2 but differ dramatically in their internal representations, and they are fully equivariant to translation and rotation even at subpixel scales. Our results pave the way for generative models better suited for video and animation.