 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Role of ImageNet Classes in Fréchet Inception Distance
Paper and Code
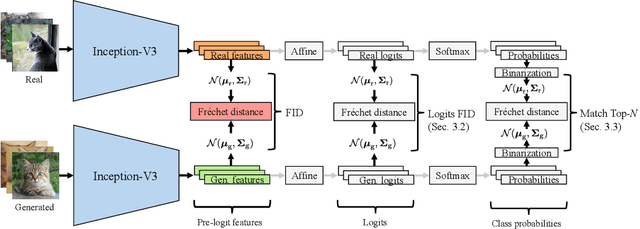
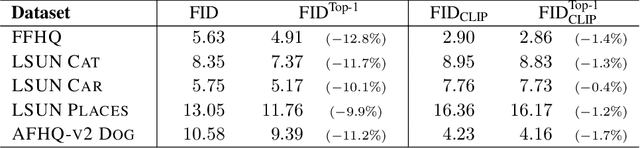
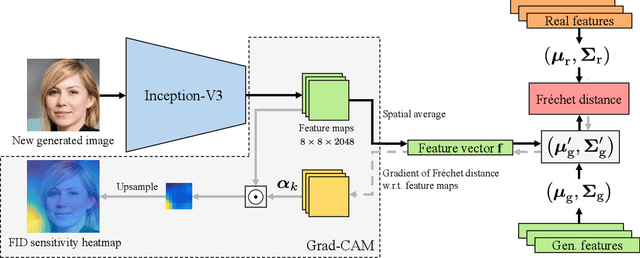

Fr\'echet Inception Distance (FID) is a metric for quantifying the distance between two distributions of images. Given its status as a standard yardstick for ranking models in data-driven generative modeling research, it seems important that the distance is computed from general, "vision-related" features. But is it? We observe that FID is essentially a distance between sets of ImageNet class probabilities. We trace the reason to the fact that the standard feature space, the penultimate "pre-logit" layer of a particular Inception-V3 classifier network, is only one affine transform away from the logits, i.e., ImageNet classes, and thus, the features are necessarily highly specialized to them. This has unintuitive consequences for the metric's sensitivity. For example, when evaluating a model for human faces, we observe that, on average, FID is actually very insensitive to the facial region, and that the probabilities of classes like "bow tie" or "seat belt" play a much larger role. Further, we show that FID can be significantly reduced -- without actually improving the quality of results -- by an attack that first generates a slightly larger set of candidates, and then chooses a subset that happens to match the histogram of such "fringe features" in the real data. We then demonstrate that this observation has practical relevance in case of ImageNet pre-training of GANs, where a part of the observed FID improvement turns out not to be real. Our results suggest caution against over-interpreting FID improvements, and underline the need for distribution metrics that are more perceptually uniform.