 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePutting People in Their Place: Affordance-Aware Human Insertion into Scenes
Apr 27, 2023
We study the problem of inferring scene affordances by presenting a method for realistically inserting people into scenes. Given a scene image with a marked region and an image of a person, we insert the person into the scene while respecting the scene affordances. Our model can infer the set of realistic poses given the scene context, re-pose the reference person, and harmonize the composition. We set up the task in a self-supervised fashion by learning to re-pose humans in video clips. We train a large-scale diffusion model on a dataset of 2.4M video clips that produces diverse plausible poses while respecting the scene context. Given the learned human-scene composition, our model can also hallucinate realistic people and scenes when prompted without conditioning and also enables interactive editing. A quantitative evaluation shows that our method synthesizes more realistic human appearance and more natural human-scene interactions than prior work.
InstructPix2Pix: Learning to Follow Image Editing Instructions
Nov 17, 2022



We propose a method for editing images from human instructions: given an input image and a written instruction that tells the model what to do, our model follows these instructions to edit the image. To obtain training data for this problem, we combine the knowledge of two large pretrained models -- a language model (GPT-3) and a text-to-image model (Stable Diffusion) -- to generate a large dataset of image editing examples. Our conditional diffusion model, InstructPix2Pix, is trained on our generated data, and generalizes to real images and user-written instructions at inference time. Since it performs edits in the forward pass and does not require per example fine-tuning or inversion, our model edits images quickly, in a matter of seconds. We show compelling editing results for a diverse collection of input images and written instructions.
Learning to Learn with Generative Models of Neural Network Checkpoints
Sep 26, 2022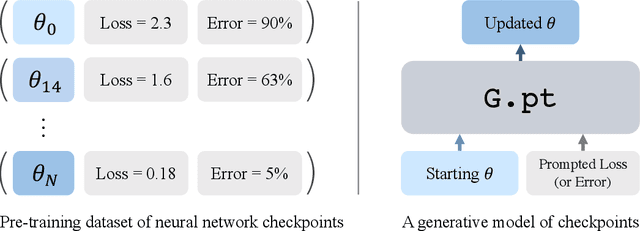
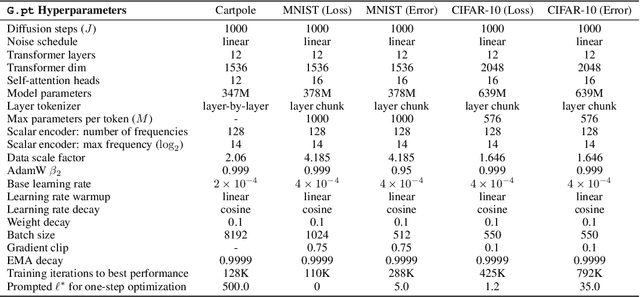
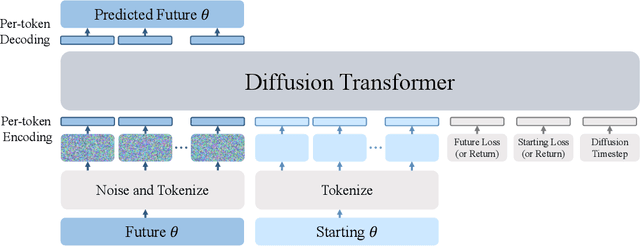

We explore a data-driven approach for learning to optimize neural networks. We construct a dataset of neural network checkpoints and train a generative model on the parameters. In particular, our model is a conditional diffusion transformer that, given an initial input parameter vector and a prompted loss, error, or return, predicts the distribution over parameter updates that achieve the desired metric. At test time, it can optimize neural networks with unseen parameters for downstream tasks in just one update. We find that our approach successfully generates parameters for a wide range of loss prompts. Moreover, it can sample multimodal parameter solutions and has favorable scaling properties. We apply our method to different neural network architectures and tasks in supervised and reinforcement learning.
Studying Bias in GANs through the Lens of Race
Sep 15, 2022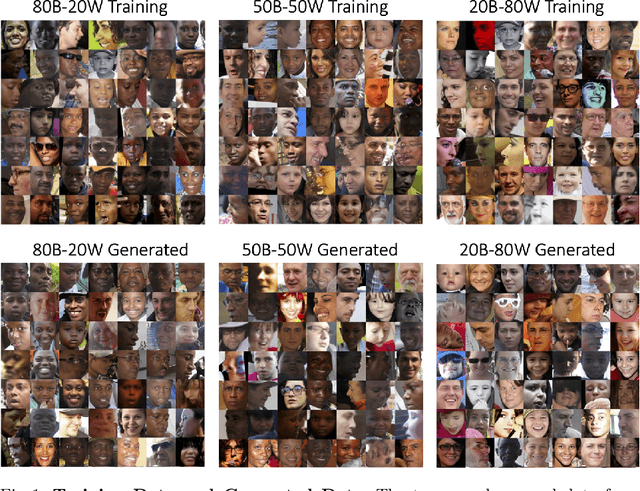



In this work, we study how the performance and evaluation of generative image models are impacted by the racial composition of their training datasets. By examining and controlling the racial distributions in various training datasets, we are able to observe the impacts of different training distributions on generated image quality and the racial distributions of the generated images. Our results show that the racial compositions of generated images successfully preserve that of the training data. However, we observe that truncation, a technique used to generate higher quality images during inference, exacerbates racial imbalances in the data. Lastly, when examining the relationship between image quality and race, we find that the highest perceived visual quality images of a given race come from a distribution where that race is well-represented, and that annotators consistently prefer generated images of white people over those of Black people.
Generating Long Videos of Dynamic Scenes
Jun 09, 2022

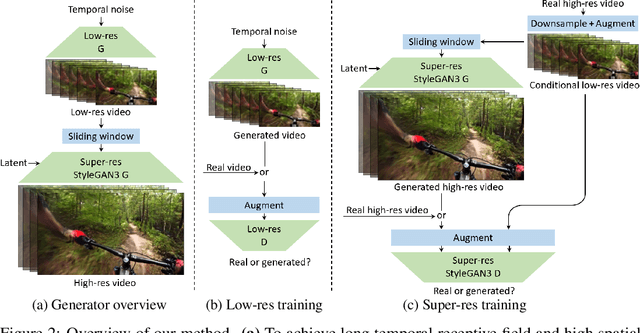

We present a video generation model that accurately reproduces object motion, changes in camera viewpoint, and new content that arises over time. Existing video generation methods often fail to produce new content as a function of time while maintaining consistencies expected in real environments, such as plausible dynamics and object persistence. A common failure case is for content to never change due to over-reliance on inductive biases to provide temporal consistency, such as a single latent code that dictates content for the entire video. On the other extreme, without long-term consistency, generated videos may morph unrealistically between different scenes. To address these limitations, we prioritize the time axis by redesigning the temporal latent representation and learning long-term consistency from data by training on longer videos. To this end, we leverage a two-phase training strategy, where we separately train using longer videos at a low resolution and shorter videos at a high resolution. To evaluate the capabilities of our model, we introduce two new benchmark datasets with explicit focus on long-term temporal dynamics.
Hallucinating Pose-Compatible Scenes
Dec 13, 2021
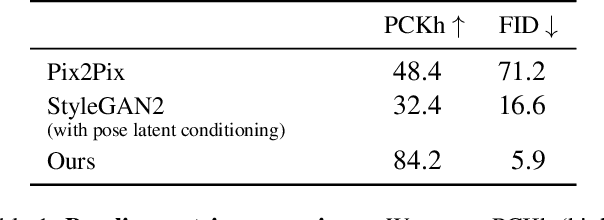

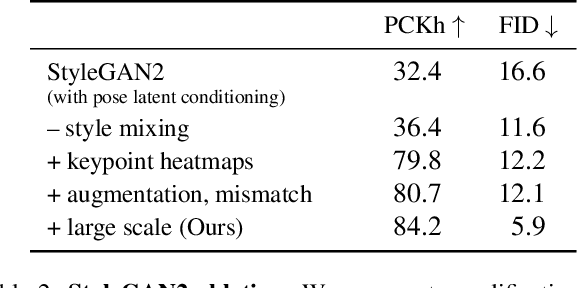
What does human pose tell us about a scene? We propose a task to answer this question: given human pose as input, hallucinate a compatible scene. Subtle cues captured by human pose -- action semantics, environment affordances, object interactions -- provide surprising insight into which scenes are compatible. We present a large-scale generative adversarial network for pose-conditioned scene generation. We significantly scale the size and complexity of training data, curating a massive meta-dataset containing over 19 million frames of humans in everyday environments. We double the capacity of our model with respect to StyleGAN2 to handle such complex data, and design a pose conditioning mechanism that drives our model to learn the nuanced relationship between pose and scene. We leverage our trained model for various applications: hallucinating pose-compatible scene(s) with or without humans, visualizing incompatible scenes and poses, placing a person from one generated image into another scene, and animating pose. Our model produces diverse samples and outperforms pose-conditioned StyleGAN2 and Pix2Pix baselines in terms of accurate human placement (percent of correct keypoints) and image quality (Frechet inception distance).
Handheld Mobile Photography in Very Low Light
Oct 24, 2019

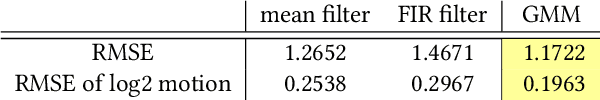

Taking photographs in low light using a mobile phone is challenging and rarely produces pleasing results. Aside from the physical limits imposed by read noise and photon shot noise, these cameras are typically handheld, have small apertures and sensors, use mass-produced analog electronics that cannot easily be cooled, and are commonly used to photograph subjects that move, like children and pets. In this paper we describe a system for capturing clean, sharp, colorful photographs in light as low as 0.3~lux, where human vision becomes monochromatic and indistinct. To permit handheld photography without flash illumination, we capture, align, and combine multiple frames. Our system employs "motion metering", which uses an estimate of motion magnitudes (whether due to handshake or moving objects) to identify the number of frames and the per-frame exposure times that together minimize both noise and motion blur in a captured burst. We combine these frames using robust alignment and merging techniques that are specialized for high-noise imagery. To ensure accurate colors in such low light, we employ a learning-based auto white balancing algorithm. To prevent the photographs from looking like they were shot in daylight, we use tone mapping techniques inspired by illusionistic painting: increasing contrast, crushing shadows to black, and surrounding the scene with darkness. All of these processes are performed using the limited computational resources of a mobile device. Our system can be used by novice photographers to produce shareable pictures in a few seconds based on a single shutter press, even in environments so dim that humans cannot see clearly.
* 22 pages, 27 figures
Learning to Synthesize Motion Blur
Nov 27, 2018
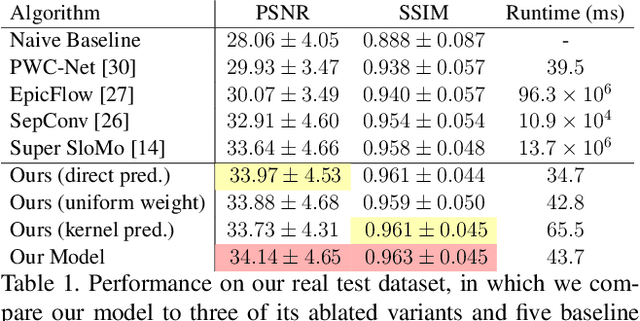


We present a technique for synthesizing a motion blurred image from a pair of unblurred images captured in succession. To build this system we motivate and design a differentiable "line prediction" layer to be used as part of a neural network architecture, with which we can learn a system to regress from image pairs to motion blurred images that span the capture time of the input image pair. Training this model requires an abundance of data, and so we design and execute a strategy for using frame interpolation techniques to generate a large-scale synthetic dataset of motion blurred images and their respective inputs. We additionally capture a high quality test set of real motion blurred images, synthesized from slow motion videos, with which we evaluate our model against several baseline techniques that can be used to synthesize motion blur. Our model produces higher accuracy output than our baselines, and is several orders of magnitude faster than those baselines with competitive accuracy.
Unprocessing Images for Learned Raw Denoising
Nov 27, 2018
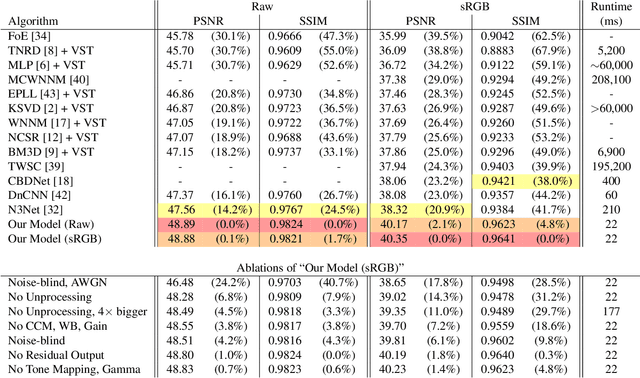

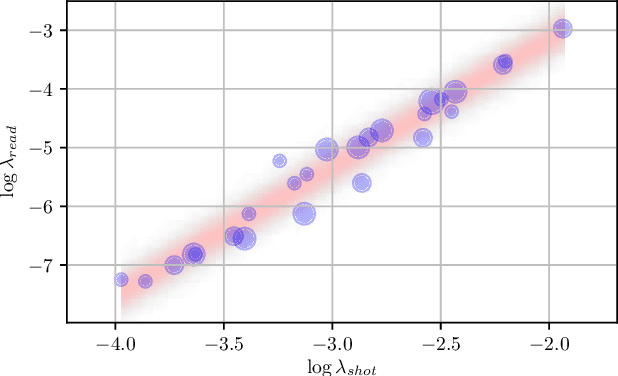
Machine learning techniques work best when the data used for training resembles the data used for evaluation. This holds true for learned single-image denoising algorithms, which are applied to real raw camera sensor readings but, due to practical constraints, are often trained on synthetic image data. Though it is understood that generalizing from synthetic to real data requires careful consideration of the noise properties of image sensors, the other aspects of a camera's image processing pipeline (gain, color correction, tone mapping, etc) are often overlooked, despite their significant effect on how raw measurements are transformed into finished images. To address this, we present a technique to "unprocess" images by inverting each step of an image processing pipeline, thereby allowing us to synthesize realistic raw sensor measurements from commonly available internet photos. We additionally model the relevant components of an image processing pipeline when evaluating our loss function, which allows training to be aware of all relevant photometric processing that will occur after denoising. By processing and unprocessing model outputs and training data in this way, we are able to train a simple convolutional neural network that has 14%-38% lower error rates and is 9x-18x faster than the previous state of the art on the Darmstadt Noise Dataset, and generalizes to sensors outside of that dataset as well.