 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReCapture: Generative Video Camera Controls for User-Provided Videos using Masked Video Fine-Tuning
Nov 07, 2024



Recently, breakthroughs in video modeling have allowed for controllable camera trajectories in generated videos. However, these methods cannot be directly applied to user-provided videos that are not generated by a video model. In this paper, we present ReCapture, a method for generating new videos with novel camera trajectories from a single user-provided video. Our method allows us to re-generate the reference video, with all its existing scene motion, from vastly different angles and with cinematic camera motion. Notably, using our method we can also plausibly hallucinate parts of the scene that were not observable in the reference video. Our method works by (1) generating a noisy anchor video with a new camera trajectory using multiview diffusion models or depth-based point cloud rendering and then (2) regenerating the anchor video into a clean and temporally consistent reangled video using our proposed masked video fine-tuning technique.
Computational Long Exposure Mobile Photography
Aug 02, 2023
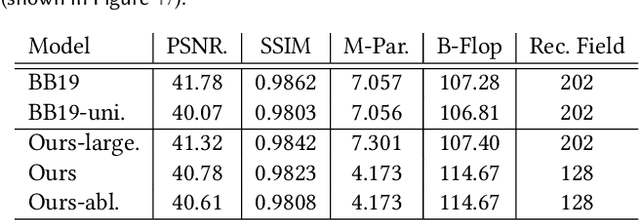


Long exposure photography produces stunning imagery, representing moving elements in a scene with motion-blur. It is generally employed in two modalities, producing either a foreground or a background blur effect. Foreground blur images are traditionally captured on a tripod-mounted camera and portray blurred moving foreground elements, such as silky water or light trails, over a perfectly sharp background landscape. Background blur images, also called panning photography, are captured while the camera is tracking a moving subject, to produce an image of a sharp subject over a background blurred by relative motion. Both techniques are notoriously challenging and require additional equipment and advanced skills. In this paper, we describe a computational burst photography system that operates in a hand-held smartphone camera app, and achieves these effects fully automatically, at the tap of the shutter button. Our approach first detects and segments the salient subject. We track the scene motion over multiple frames and align the images in order to preserve desired sharpness and to produce aesthetically pleasing motion streaks. We capture an under-exposed burst and select the subset of input frames that will produce blur trails of controlled length, regardless of scene or camera motion velocity. We predict inter-frame motion and synthesize motion-blur to fill the temporal gaps between the input frames. Finally, we composite the blurred image with the sharp regular exposure to protect the sharpness of faces or areas of the scene that are barely moving, and produce a final high resolution and high dynamic range (HDR) photograph. Our system democratizes a capability previously reserved to professionals, and makes this creative style accessible to most casual photographers. More information and supplementary material can be found on our project webpage: https://motion-mode.github.io/
* 15 pages, 17 figures
Zoom-to-Inpaint: Image Inpainting with High Frequency Details
Dec 17, 2020

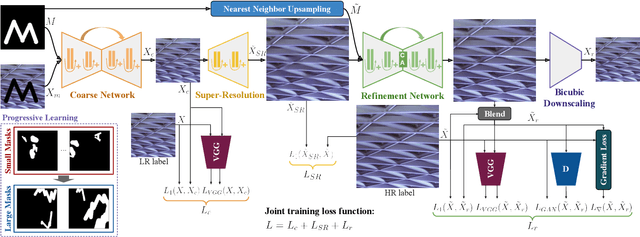
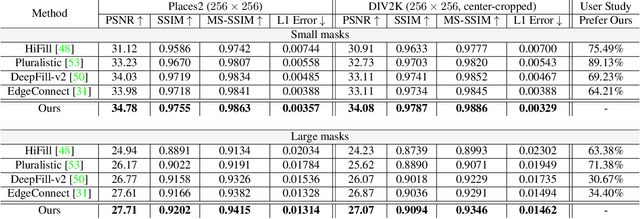
Although deep learning has enabled a huge leap forward in image inpainting, current methods are often unable to synthesize realistic high-frequency details. In this paper, we propose applying super resolution to coarsely reconstructed outputs, refining them at high resolution, and then downscaling the output to the original resolution. By introducing high-resolution images to the refinement network, our framework is able to reconstruct finer details that are usually smoothed out due to spectral bias - the tendency of neural networks to reconstruct low frequencies better than high frequencies. To assist training the refinement network on large upscaled holes, we propose a progressive learning technique in which the size of the missing regions increases as training progresses. Our zoom-in, refine and zoom-out strategy, combined with high-resolution supervision and progressive learning, constitutes a framework-agnostic approach for enhancing high-frequency details that can be applied to other inpainting methods. We provide qualitative and quantitative evaluations along with an ablation analysis to show the effectiveness of our approach, which outperforms state-of-the-art inpainting methods.
Handheld Mobile Photography in Very Low Light
Oct 24, 2019

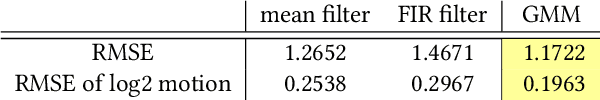

Taking photographs in low light using a mobile phone is challenging and rarely produces pleasing results. Aside from the physical limits imposed by read noise and photon shot noise, these cameras are typically handheld, have small apertures and sensors, use mass-produced analog electronics that cannot easily be cooled, and are commonly used to photograph subjects that move, like children and pets. In this paper we describe a system for capturing clean, sharp, colorful photographs in light as low as 0.3~lux, where human vision becomes monochromatic and indistinct. To permit handheld photography without flash illumination, we capture, align, and combine multiple frames. Our system employs "motion metering", which uses an estimate of motion magnitudes (whether due to handshake or moving objects) to identify the number of frames and the per-frame exposure times that together minimize both noise and motion blur in a captured burst. We combine these frames using robust alignment and merging techniques that are specialized for high-noise imagery. To ensure accurate colors in such low light, we employ a learning-based auto white balancing algorithm. To prevent the photographs from looking like they were shot in daylight, we use tone mapping techniques inspired by illusionistic painting: increasing contrast, crushing shadows to black, and surrounding the scene with darkness. All of these processes are performed using the limited computational resources of a mobile device. Our system can be used by novice photographers to produce shareable pictures in a few seconds based on a single shutter press, even in environments so dim that humans cannot see clearly.
* 22 pages, 27 figures