 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlterbute: Editing Intrinsic Attributes of Objects in Images
Jan 15, 2026We introduce Alterbute, a diffusion-based method for editing an object's intrinsic attributes in an image. We allow changing color, texture, material, and even the shape of an object, while preserving its perceived identity and scene context. Existing approaches either rely on unsupervised priors that often fail to preserve identity or use overly restrictive supervision that prevents meaningful intrinsic variations. Our method relies on: (i) a relaxed training objective that allows the model to change both intrinsic and extrinsic attributes conditioned on an identity reference image, a textual prompt describing the target intrinsic attributes, and a background image and object mask defining the extrinsic context. At inference, we restrict extrinsic changes by reusing the original background and object mask, thereby ensuring that only the desired intrinsic attributes are altered; (ii) Visual Named Entities (VNEs) - fine-grained visual identity categories (e.g., ''Porsche 911 Carrera'') that group objects sharing identity-defining features while allowing variation in intrinsic attributes. We use a vision-language model to automatically extract VNE labels and intrinsic attribute descriptions from a large public image dataset, enabling scalable, identity-preserving supervision. Alterbute outperforms existing methods on identity-preserving object intrinsic attribute editing.
LightLab: Controlling Light Sources in Images with Diffusion Models
May 14, 2025We present a simple, yet effective diffusion-based method for fine-grained, parametric control over light sources in an image. Existing relighting methods either rely on multiple input views to perform inverse rendering at inference time, or fail to provide explicit control over light changes. Our method fine-tunes a diffusion model on a small set of real raw photograph pairs, supplemented by synthetically rendered images at scale, to elicit its photorealistic prior for relighting. We leverage the linearity of light to synthesize image pairs depicting controlled light changes of either a target light source or ambient illumination. Using this data and an appropriate fine-tuning scheme, we train a model for precise illumination changes with explicit control over light intensity and color. Lastly, we show how our method can achieve compelling light editing results, and outperforms existing methods based on user preference.
ObjectMate: A Recurrence Prior for Object Insertion and Subject-Driven Generation
Dec 11, 2024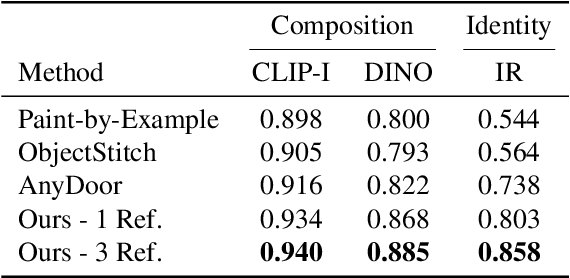

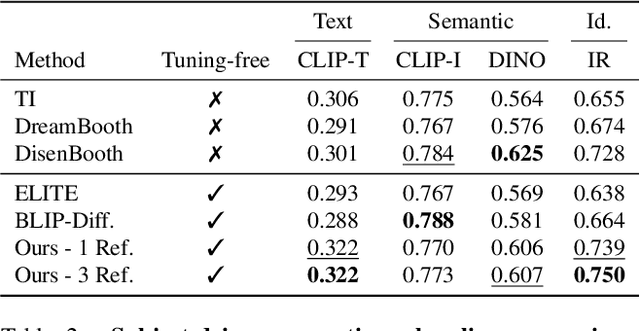
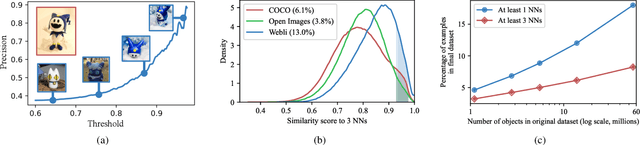
This paper introduces a tuning-free method for both object insertion and subject-driven generation. The task involves composing an object, given multiple views, into a scene specified by either an image or text. Existing methods struggle to fully meet the task's challenging objectives: (i) seamlessly composing the object into the scene with photorealistic pose and lighting, and (ii) preserving the object's identity. We hypothesize that achieving these goals requires large scale supervision, but manually collecting sufficient data is simply too expensive. The key observation in this paper is that many mass-produced objects recur across multiple images of large unlabeled datasets, in different scenes, poses, and lighting conditions. We use this observation to create massive supervision by retrieving sets of diverse views of the same object. This powerful paired dataset enables us to train a straightforward text-to-image diffusion architecture to map the object and scene descriptions to the composited image. We compare our method, ObjectMate, with state-of-the-art methods for object insertion and subject-driven generation, using a single or multiple references. Empirically, ObjectMate achieves superior identity preservation and more photorealistic composition. Differently from many other multi-reference methods, ObjectMate does not require slow test-time tuning.
ReCapture: Generative Video Camera Controls for User-Provided Videos using Masked Video Fine-Tuning
Nov 07, 2024



Recently, breakthroughs in video modeling have allowed for controllable camera trajectories in generated videos. However, these methods cannot be directly applied to user-provided videos that are not generated by a video model. In this paper, we present ReCapture, a method for generating new videos with novel camera trajectories from a single user-provided video. Our method allows us to re-generate the reference video, with all its existing scene motion, from vastly different angles and with cinematic camera motion. Notably, using our method we can also plausibly hallucinate parts of the scene that were not observable in the reference video. Our method works by (1) generating a noisy anchor video with a new camera trajectory using multiview diffusion models or depth-based point cloud rendering and then (2) regenerating the anchor video into a clean and temporally consistent reangled video using our proposed masked video fine-tuning technique.
Unbounded: A Generative Infinite Game of Character Life Simulation
Oct 24, 2024


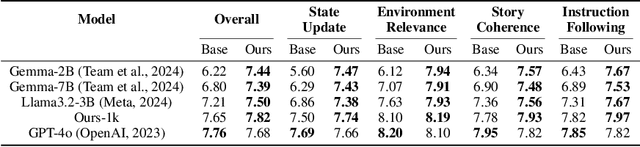
We introduce the concept of a generative infinite game, a video game that transcends the traditional boundaries of finite, hard-coded systems by using generative models. Inspired by James P. Carse's distinction between finite and infinite games, we leverage recent advances in generative AI to create Unbounded: a game of character life simulation that is fully encapsulated in generative models. Specifically, Unbounded draws inspiration from sandbox life simulations and allows you to interact with your autonomous virtual character in a virtual world by feeding, playing with and guiding it - with open-ended mechanics generated by an LLM, some of which can be emergent. In order to develop Unbounded, we propose technical innovations in both the LLM and visual generation domains. Specifically, we present: (1) a specialized, distilled large language model (LLM) that dynamically generates game mechanics, narratives, and character interactions in real-time, and (2) a new dynamic regional image prompt Adapter (IP-Adapter) for vision models that ensures consistent yet flexible visual generation of a character across multiple environments. We evaluate our system through both qualitative and quantitative analysis, showing significant improvements in character life simulation, user instruction following, narrative coherence, and visual consistency for both characters and the environments compared to traditional related approaches.
Magic Insert: Style-Aware Drag-and-Drop
Jul 02, 2024We present Magic Insert, a method for dragging-and-dropping subjects from a user-provided image into a target image of a different style in a physically plausible manner while matching the style of the target image. This work formalizes the problem of style-aware drag-and-drop and presents a method for tackling it by addressing two sub-problems: style-aware personalization and realistic object insertion in stylized images. For style-aware personalization, our method first fine-tunes a pretrained text-to-image diffusion model using LoRA and learned text tokens on the subject image, and then infuses it with a CLIP representation of the target style. For object insertion, we use Bootstrapped Domain Adaption to adapt a domain-specific photorealistic object insertion model to the domain of diverse artistic styles. Overall, the method significantly outperforms traditional approaches such as inpainting. Finally, we present a dataset, SubjectPlop, to facilitate evaluation and future progress in this area. Project page: https://magicinsert.github.io/
ObjectDrop: Bootstrapping Counterfactuals for Photorealistic Object Removal and Insertion
Mar 27, 2024



Diffusion models have revolutionized image editing but often generate images that violate physical laws, particularly the effects of objects on the scene, e.g., occlusions, shadows, and reflections. By analyzing the limitations of self-supervised approaches, we propose a practical solution centered on a \q{counterfactual} dataset. Our method involves capturing a scene before and after removing a single object, while minimizing other changes. By fine-tuning a diffusion model on this dataset, we are able to not only remove objects but also their effects on the scene. However, we find that applying this approach for photorealistic object insertion requires an impractically large dataset. To tackle this challenge, we propose bootstrap supervision; leveraging our object removal model trained on a small counterfactual dataset, we synthetically expand this dataset considerably. Our approach significantly outperforms prior methods in photorealistic object removal and insertion, particularly at modeling the effects of objects on the scene.
PALP: Prompt Aligned Personalization of Text-to-Image Models
Jan 11, 2024



Content creators often aim to create personalized images using personal subjects that go beyond the capabilities of conventional text-to-image models. Additionally, they may want the resulting image to encompass a specific location, style, ambiance, and more. Existing personalization methods may compromise personalization ability or the alignment to complex textual prompts. This trade-off can impede the fulfillment of user prompts and subject fidelity. We propose a new approach focusing on personalization methods for a \emph{single} prompt to address this issue. We term our approach prompt-aligned personalization. While this may seem restrictive, our method excels in improving text alignment, enabling the creation of images with complex and intricate prompts, which may pose a challenge for current techniques. In particular, our method keeps the personalized model aligned with a target prompt using an additional score distillation sampling term. We demonstrate the versatility of our method in multi- and single-shot settings and further show that it can compose multiple subjects or use inspiration from reference images, such as artworks. We compare our approach quantitatively and qualitatively with existing baselines and state-of-the-art techniques.
RealFill: Reference-Driven Generation for Authentic Image Completion
Sep 28, 2023Recent advances in generative imagery have brought forth outpainting and inpainting models that can produce high-quality, plausible image content in unknown regions, but the content these models hallucinate is necessarily inauthentic, since the models lack sufficient context about the true scene. In this work, we propose RealFill, a novel generative approach for image completion that fills in missing regions of an image with the content that should have been there. RealFill is a generative inpainting model that is personalized using only a few reference images of a scene. These reference images do not have to be aligned with the target image, and can be taken with drastically varying viewpoints, lighting conditions, camera apertures, or image styles. Once personalized, RealFill is able to complete a target image with visually compelling contents that are faithful to the original scene. We evaluate RealFill on a new image completion benchmark that covers a set of diverse and challenging scenarios, and find that it outperforms existing approaches by a large margin. See more results on our project page: https://realfill.github.io
Computational Long Exposure Mobile Photography
Aug 02, 2023
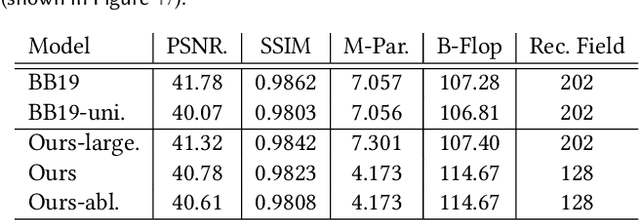


Long exposure photography produces stunning imagery, representing moving elements in a scene with motion-blur. It is generally employed in two modalities, producing either a foreground or a background blur effect. Foreground blur images are traditionally captured on a tripod-mounted camera and portray blurred moving foreground elements, such as silky water or light trails, over a perfectly sharp background landscape. Background blur images, also called panning photography, are captured while the camera is tracking a moving subject, to produce an image of a sharp subject over a background blurred by relative motion. Both techniques are notoriously challenging and require additional equipment and advanced skills. In this paper, we describe a computational burst photography system that operates in a hand-held smartphone camera app, and achieves these effects fully automatically, at the tap of the shutter button. Our approach first detects and segments the salient subject. We track the scene motion over multiple frames and align the images in order to preserve desired sharpness and to produce aesthetically pleasing motion streaks. We capture an under-exposed burst and select the subset of input frames that will produce blur trails of controlled length, regardless of scene or camera motion velocity. We predict inter-frame motion and synthesize motion-blur to fill the temporal gaps between the input frames. Finally, we composite the blurred image with the sharp regular exposure to protect the sharpness of faces or areas of the scene that are barely moving, and produce a final high resolution and high dynamic range (HDR) photograph. Our system democratizes a capability previously reserved to professionals, and makes this creative style accessible to most casual photographers. More information and supplementary material can be found on our project webpage: https://motion-mode.github.io/
* 15 pages, 17 figures