 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReCapture: Generative Video Camera Controls for User-Provided Videos using Masked Video Fine-Tuning
Nov 07, 2024



Recently, breakthroughs in video modeling have allowed for controllable camera trajectories in generated videos. However, these methods cannot be directly applied to user-provided videos that are not generated by a video model. In this paper, we present ReCapture, a method for generating new videos with novel camera trajectories from a single user-provided video. Our method allows us to re-generate the reference video, with all its existing scene motion, from vastly different angles and with cinematic camera motion. Notably, using our method we can also plausibly hallucinate parts of the scene that were not observable in the reference video. Our method works by (1) generating a noisy anchor video with a new camera trajectory using multiview diffusion models or depth-based point cloud rendering and then (2) regenerating the anchor video into a clean and temporally consistent reangled video using our proposed masked video fine-tuning technique.
Unbounded: A Generative Infinite Game of Character Life Simulation
Oct 24, 2024


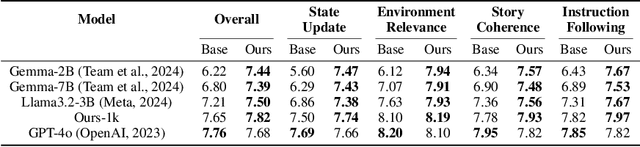
We introduce the concept of a generative infinite game, a video game that transcends the traditional boundaries of finite, hard-coded systems by using generative models. Inspired by James P. Carse's distinction between finite and infinite games, we leverage recent advances in generative AI to create Unbounded: a game of character life simulation that is fully encapsulated in generative models. Specifically, Unbounded draws inspiration from sandbox life simulations and allows you to interact with your autonomous virtual character in a virtual world by feeding, playing with and guiding it - with open-ended mechanics generated by an LLM, some of which can be emergent. In order to develop Unbounded, we propose technical innovations in both the LLM and visual generation domains. Specifically, we present: (1) a specialized, distilled large language model (LLM) that dynamically generates game mechanics, narratives, and character interactions in real-time, and (2) a new dynamic regional image prompt Adapter (IP-Adapter) for vision models that ensures consistent yet flexible visual generation of a character across multiple environments. We evaluate our system through both qualitative and quantitative analysis, showing significant improvements in character life simulation, user instruction following, narrative coherence, and visual consistency for both characters and the environments compared to traditional related approaches.
Magic Insert: Style-Aware Drag-and-Drop
Jul 02, 2024We present Magic Insert, a method for dragging-and-dropping subjects from a user-provided image into a target image of a different style in a physically plausible manner while matching the style of the target image. This work formalizes the problem of style-aware drag-and-drop and presents a method for tackling it by addressing two sub-problems: style-aware personalization and realistic object insertion in stylized images. For style-aware personalization, our method first fine-tunes a pretrained text-to-image diffusion model using LoRA and learned text tokens on the subject image, and then infuses it with a CLIP representation of the target style. For object insertion, we use Bootstrapped Domain Adaption to adapt a domain-specific photorealistic object insertion model to the domain of diverse artistic styles. Overall, the method significantly outperforms traditional approaches such as inpainting. Finally, we present a dataset, SubjectPlop, to facilitate evaluation and future progress in this area. Project page: https://magicinsert.github.io/
RealFill: Reference-Driven Generation for Authentic Image Completion
Sep 28, 2023Recent advances in generative imagery have brought forth outpainting and inpainting models that can produce high-quality, plausible image content in unknown regions, but the content these models hallucinate is necessarily inauthentic, since the models lack sufficient context about the true scene. In this work, we propose RealFill, a novel generative approach for image completion that fills in missing regions of an image with the content that should have been there. RealFill is a generative inpainting model that is personalized using only a few reference images of a scene. These reference images do not have to be aligned with the target image, and can be taken with drastically varying viewpoints, lighting conditions, camera apertures, or image styles. Once personalized, RealFill is able to complete a target image with visually compelling contents that are faithful to the original scene. We evaluate RealFill on a new image completion benchmark that covers a set of diverse and challenging scenarios, and find that it outperforms existing approaches by a large margin. See more results on our project page: https://realfill.github.io
HyperDreamBooth: HyperNetworks for Fast Personalization of Text-to-Image Models
Jul 13, 2023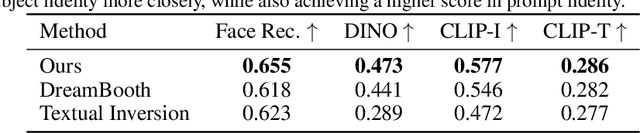



Personalization has emerged as a prominent aspect within the field of generative AI, enabling the synthesis of individuals in diverse contexts and styles, while retaining high-fidelity to their identities. However, the process of personalization presents inherent challenges in terms of time and memory requirements. Fine-tuning each personalized model needs considerable GPU time investment, and storing a personalized model per subject can be demanding in terms of storage capacity. To overcome these challenges, we propose HyperDreamBooth-a hypernetwork capable of efficiently generating a small set of personalized weights from a single image of a person. By composing these weights into the diffusion model, coupled with fast finetuning, HyperDreamBooth can generate a person's face in various contexts and styles, with high subject details while also preserving the model's crucial knowledge of diverse styles and semantic modifications. Our method achieves personalization on faces in roughly 20 seconds, 25x faster than DreamBooth and 125x faster than Textual Inversion, using as few as one reference image, with the same quality and style diversity as DreamBooth. Also our method yields a model that is 10000x smaller than a normal DreamBooth model. Project page: https://hyperdreambooth.github.io
Defocus Map Estimation and Deblurring from a Single Dual-Pixel Image
Oct 12, 2021
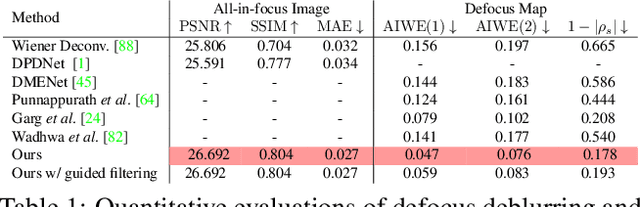
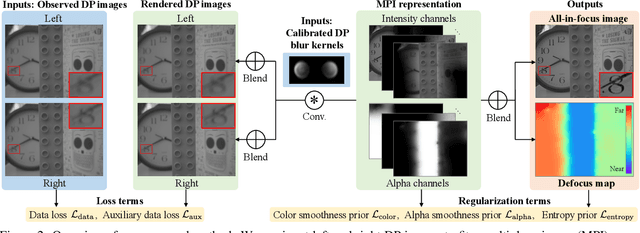
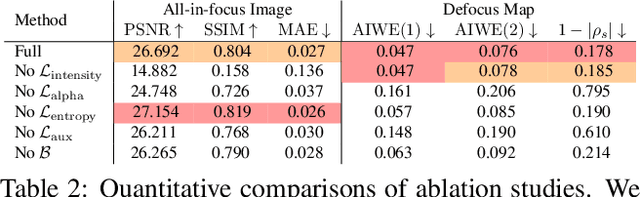
We present a method that takes as input a single dual-pixel image, and simultaneously estimates the image's defocus map -- the amount of defocus blur at each pixel -- and recovers an all-in-focus image. Our method is inspired from recent works that leverage the dual-pixel sensors available in many consumer cameras to assist with autofocus, and use them for recovery of defocus maps or all-in-focus images. These prior works have solved the two recovery problems independently of each other, and often require large labeled datasets for supervised training. By contrast, we show that it is beneficial to treat these two closely-connected problems simultaneously. To this end, we set up an optimization problem that, by carefully modeling the optics of dual-pixel images, jointly solves both problems. We use data captured with a consumer smartphone camera to demonstrate that, after a one-time calibration step, our approach improves upon prior works for both defocus map estimation and blur removal, despite being entirely unsupervised.
Zoom-to-Inpaint: Image Inpainting with High Frequency Details
Dec 17, 2020

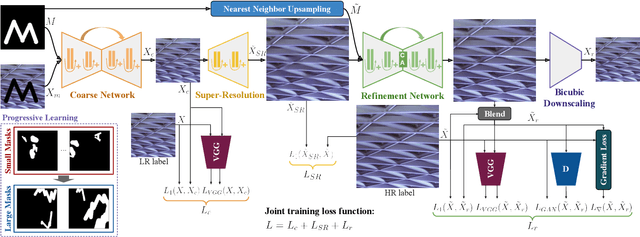
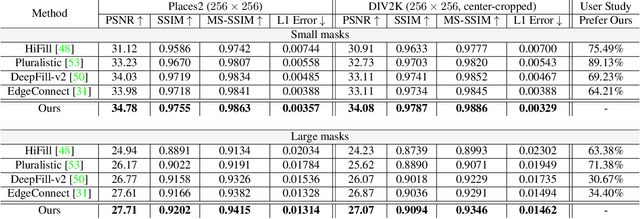
Although deep learning has enabled a huge leap forward in image inpainting, current methods are often unable to synthesize realistic high-frequency details. In this paper, we propose applying super resolution to coarsely reconstructed outputs, refining them at high resolution, and then downscaling the output to the original resolution. By introducing high-resolution images to the refinement network, our framework is able to reconstruct finer details that are usually smoothed out due to spectral bias - the tendency of neural networks to reconstruct low frequencies better than high frequencies. To assist training the refinement network on large upscaled holes, we propose a progressive learning technique in which the size of the missing regions increases as training progresses. Our zoom-in, refine and zoom-out strategy, combined with high-resolution supervision and progressive learning, constitutes a framework-agnostic approach for enhancing high-frequency details that can be applied to other inpainting methods. We provide qualitative and quantitative evaluations along with an ablation analysis to show the effectiveness of our approach, which outperforms state-of-the-art inpainting methods.
Learned Dual-View Reflection Removal
Oct 01, 2020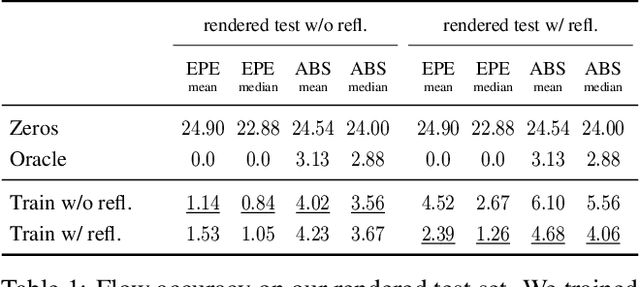

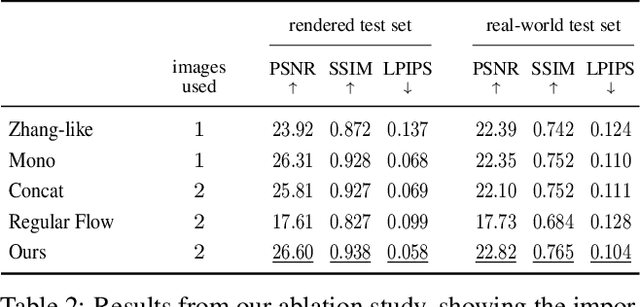

Traditional reflection removal algorithms either use a single image as input, which suffers from intrinsic ambiguities, or use multiple images from a moving camera, which is inconvenient for users. We instead propose a learning-based dereflection algorithm that uses stereo images as input. This is an effective trade-off between the two extremes: the parallax between two views provides cues to remove reflections, and two views are easy to capture due to the adoption of stereo cameras in smartphones. Our model consists of a learning-based reflection-invariant flow model for dual-view registration, and a learned synthesis model for combining aligned image pairs. Because no dataset for dual-view reflection removal exists, we render a synthetic dataset of dual-views with and without reflections for use in training. Our evaluation on an additional real-world dataset of stereo pairs shows that our algorithm outperforms existing single-image and multi-image dereflection approaches.
Learning to Autofocus
May 02, 2020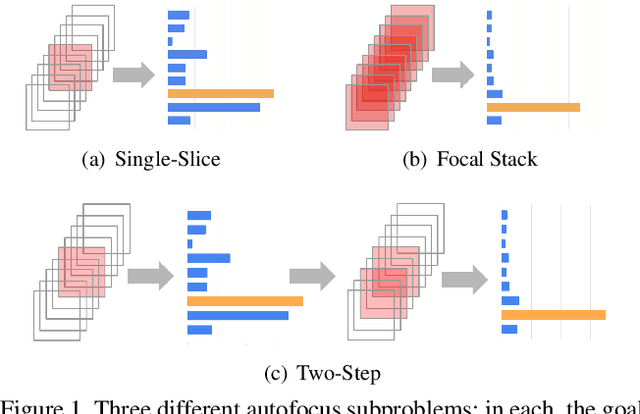

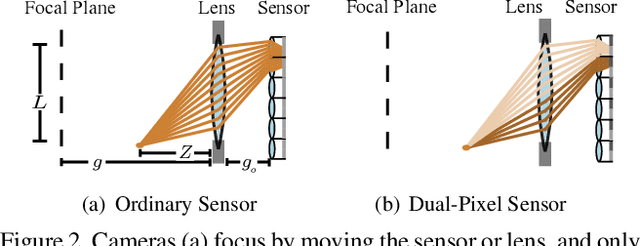
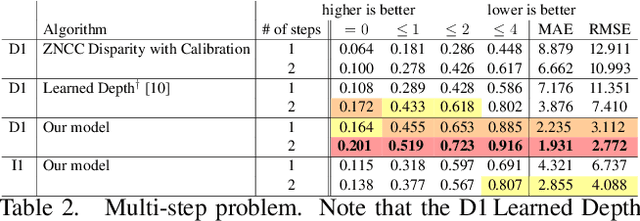
Autofocus is an important task for digital cameras, yet current approaches often exhibit poor performance. We propose a learning-based approach to this problem, and provide a realistic dataset of sufficient size for effective learning. Our dataset is labeled with per-pixel depths obtained from multi-view stereo, following "Learning single camera depth estimation using dual-pixels". Using this dataset, we apply modern deep classification models and an ordinal regression loss to obtain an efficient learning-based autofocus technique. We demonstrate that our approach provides a significant improvement compared with previous learned and non-learned methods: our model reduces the mean absolute error by a factor of 3.6 over the best comparable baseline algorithm. Our dataset and code are publicly available.
Du$^2$Net: Learning Depth Estimation from Dual-Cameras and Dual-Pixels
Mar 31, 2020
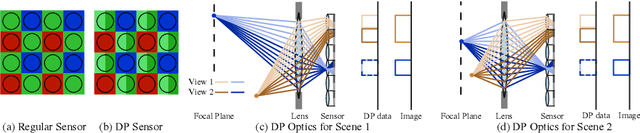
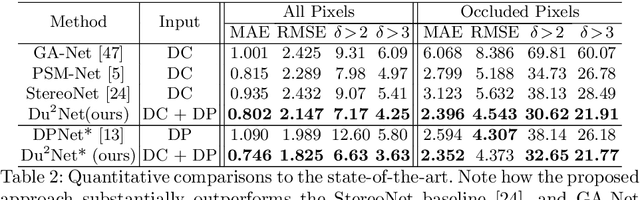
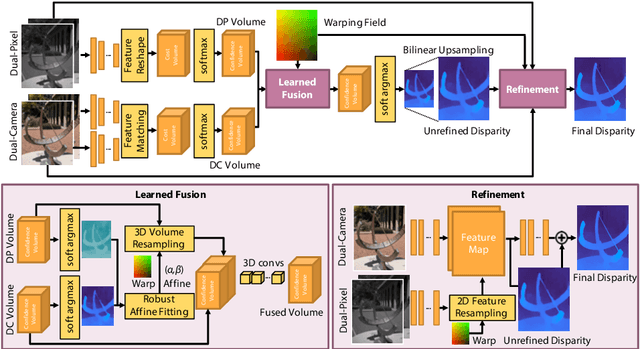
Computational stereo has reached a high level of accuracy, but degrades in the presence of occlusions, repeated textures, and correspondence errors along edges. We present a novel approach based on neural networks for depth estimation that combines stereo from dual cameras with stereo from a dual-pixel sensor, which is increasingly common on consumer cameras. Our network uses a novel architecture to fuse these two sources of information and can overcome the above-mentioned limitations of pure binocular stereo matching. Our method provides a dense depth map with sharp edges, which is crucial for computational photography applications like synthetic shallow-depth-of-field or 3D Photos. Additionally, we avoid the inherent ambiguity due to the aperture problem in stereo cameras by designing the stereo baseline to be orthogonal to the dual-pixel baseline. We present experiments and comparisons with state-of-the-art approaches to show that our method offers a substantial improvement over previous works.