 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamWalk: Style Space Exploration using Diffusion Guidance
Apr 04, 2024Text-conditioned diffusion models can generate impressive images, but fall short when it comes to fine-grained control. Unlike direct-editing tools like Photoshop, text conditioned models require the artist to perform "prompt engineering," constructing special text sentences to control the style or amount of a particular subject present in the output image. Our goal is to provide fine-grained control over the style and substance specified by the prompt, for example to adjust the intensity of styles in different regions of the image (Figure 1). Our approach is to decompose the text prompt into conceptual elements, and apply a separate guidance term for each element in a single diffusion process. We introduce guidance scale functions to control when in the diffusion process and \emph{where} in the image to intervene. Since the method is based solely on adjusting diffusion guidance, it does not require fine-tuning or manipulating the internal layers of the diffusion model's neural network, and can be used in conjunction with LoRA- or DreamBooth-trained models (Figure2). Project page: https://mshu1.github.io/dreamwalk.github.io/
Dimensions of Motion: Learning to Predict a Subspace of Optical Flow from a Single Image
Jan 06, 2022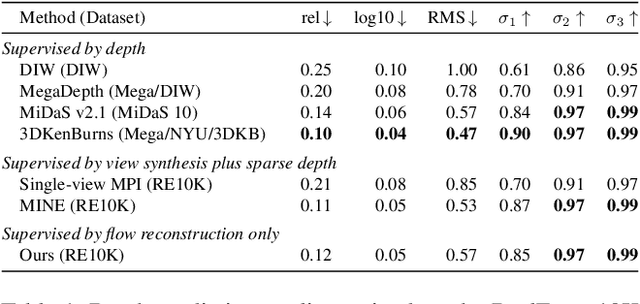


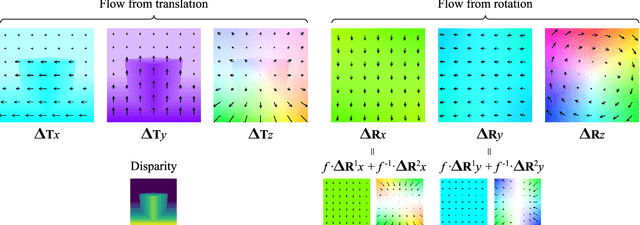
We introduce the problem of predicting, from a single video frame, a low-dimensional subspace of optical flow which includes the actual instantaneous optical flow. We show how several natural scene assumptions allow us to identify an appropriate flow subspace via a set of basis flow fields parameterized by disparity and a representation of object instances. The flow subspace, together with a novel loss function, can be used for the tasks of predicting monocular depth or predicting depth plus an object instance embedding. This provides a new approach to learning these tasks in an unsupervised fashion using monocular input video without requiring camera intrinsics or poses.
Deep survival analysis with longitudinal X-rays for COVID-19
Aug 22, 2021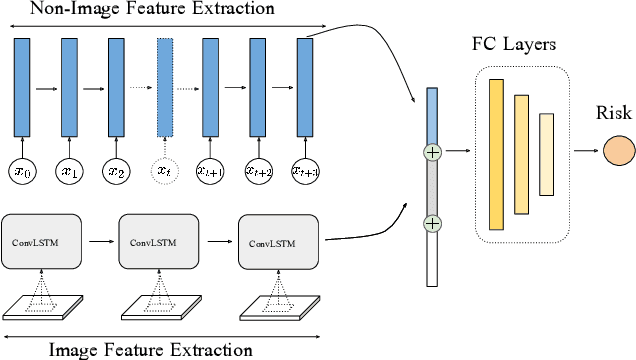
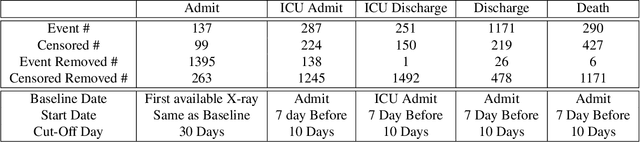
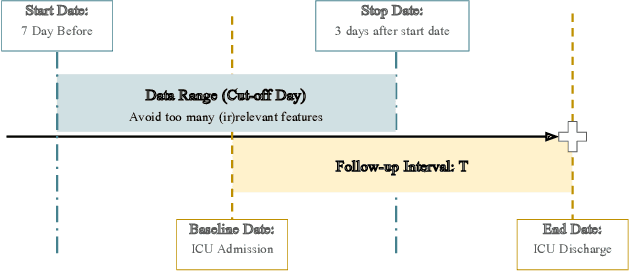
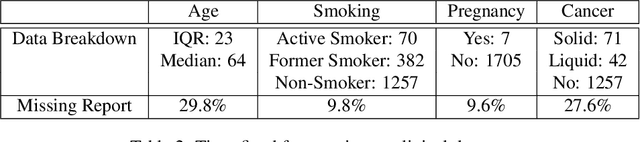
Time-to-event analysis is an important statistical tool for allocating clinical resources such as ICU beds. However, classical techniques like the Cox model cannot directly incorporate images due to their high dimensionality. We propose a deep learning approach that naturally incorporates multiple, time-dependent imaging studies as well as non-imaging data into time-to-event analysis. Our techniques are benchmarked on a clinical dataset of 1,894 COVID-19 patients, and show that image sequences significantly improve predictions. For example, classical time-to-event methods produce a concordance error of around 30-40% for predicting hospital admission, while our error is 25% without images and 20% with multiple X-rays included. Ablation studies suggest that our models are not learning spurious features such as scanner artifacts. While our focus and evaluation is on COVID-19, the methods we develop are broadly applicable.
Object-centered image stitching
Nov 23, 2020

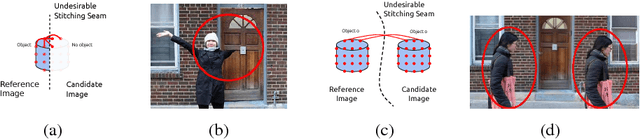

Image stitching is typically decomposed into three phases: registration, which aligns the source images with a common target image; seam finding, which determines for each target pixel the source image it should come from; and blending, which smooths transitions over the seams. As described in [1], the seam finding phase attempts to place seams between pixels where the transition between source images is not noticeable. Here, we observe that the most problematic failures of this approach occur when objects are cropped, omitted, or duplicated. We therefore take an object-centered approach to the problem, leveraging recent advances in object detection [2,3,4]. We penalize candidate solutions with this class of error by modifying the energy function used in the seam finding stage. This produces substantially more realistic stitching results on challenging imagery. In addition, these methods can be used to determine when there is non-recoverable occlusion in the input data, and also suggest a simple evaluation metric that can be used to evaluate the output of stitching algorithms.
Robust image stitching with multiple registrations
Nov 23, 2020
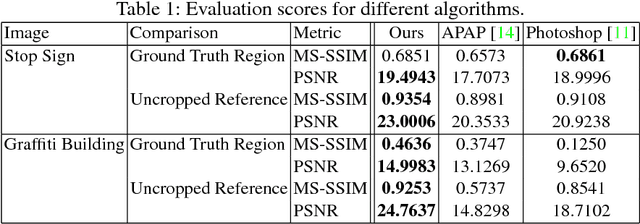


Panorama creation is one of the most widely deployed techniques in computer vision. In addition to industry applications such as Google Street View, it is also used by millions of consumers in smartphones and other cameras. Traditionally, the problem is decomposed into three phases: registration, which picks a single transformation of each source image to align it to the other inputs, seam finding, which selects a source image for each pixel in the final result, and blending, which fixes minor visual artifacts. Here, we observe that the use of a single registration often leads to errors, especially in scenes with significant depth variation or object motion. We propose instead the use of multiple registrations, permitting regions of the image at different depths to be captured with greater accuracy. MRF inference techniques naturally extend to seam finding over multiple registrations, and we show here that their energy functions can be readily modified with new terms that discourage duplication and tearing, common problems that are exacerbated by the use of multiple registrations. Our techniques are closely related to layer-based stereo, and move image stitching closer to explicit scene modeling. Experimental evidence demonstrates that our techniques often generate significantly better panoramas when there is substantial motion or parallax.
Learning to Autofocus
May 02, 2020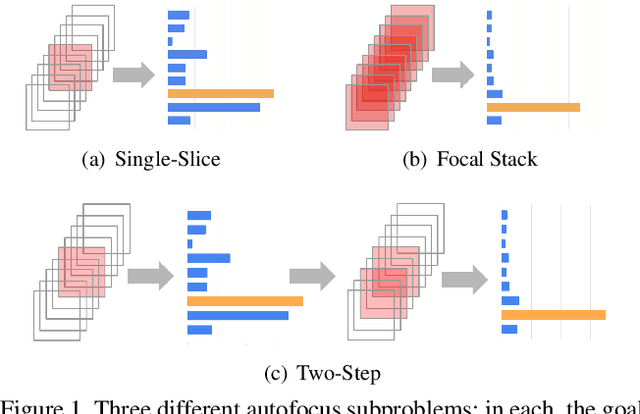

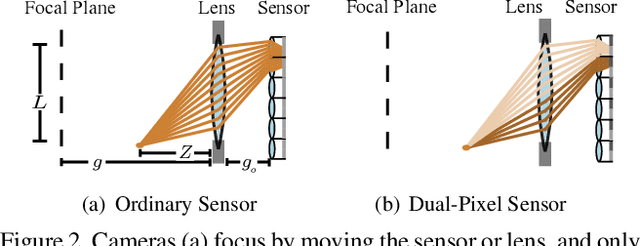
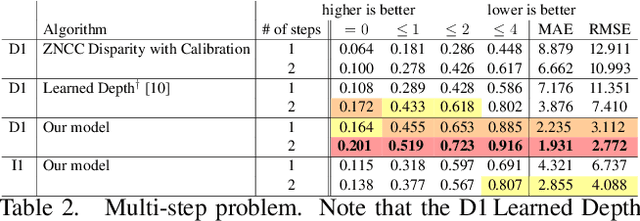
Autofocus is an important task for digital cameras, yet current approaches often exhibit poor performance. We propose a learning-based approach to this problem, and provide a realistic dataset of sufficient size for effective learning. Our dataset is labeled with per-pixel depths obtained from multi-view stereo, following "Learning single camera depth estimation using dual-pixels". Using this dataset, we apply modern deep classification models and an ordinal regression loss to obtain an efficient learning-based autofocus technique. We demonstrate that our approach provides a significant improvement compared with previous learned and non-learned methods: our model reduces the mean absolute error by a factor of 3.6 over the best comparable baseline algorithm. Our dataset and code are publicly available.
Deep networks with probabilistic gates
Dec 11, 2018
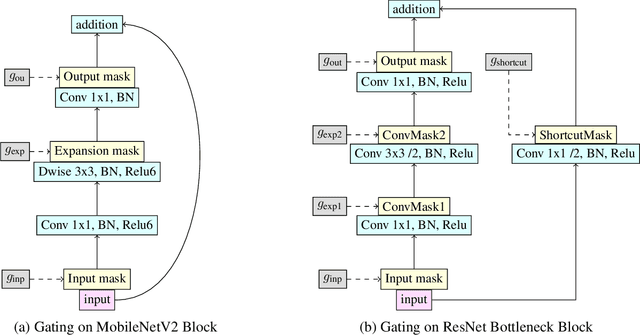
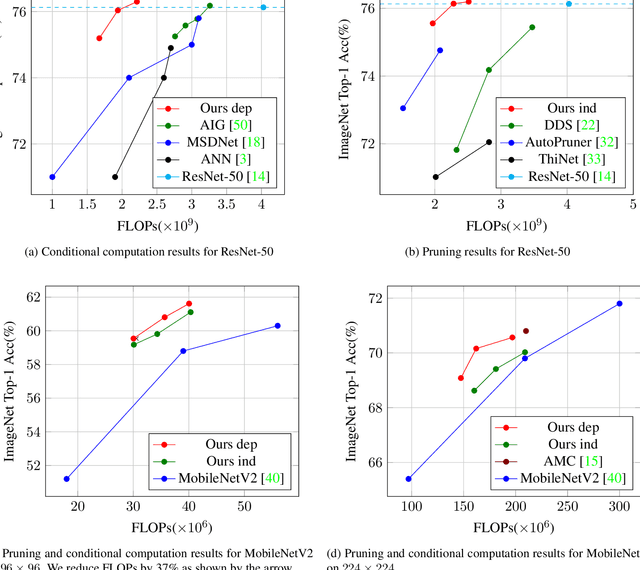
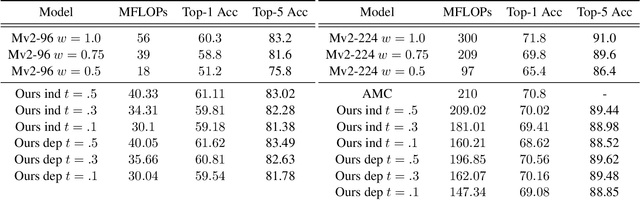
We investigate learning to probabilistically bypass computations in a network architecture. Our approach is motivated by AIG, where layers are conditionally executed depending on their inputs, and the network is trained against a target bypass rate using a per-layer loss. We propose a per-batch loss function, and describe strategies for handling probabilistic bypass during inference as well as training. Per-batch loss allows the network additional flexibility. In particular, a form of mode collapse becomes plausible, where some layers are nearly always bypassed and some almost never; such a configuration is strongly discouraged by AIG's per-layer loss. We explore several inference-time strategies, including the natural MAP approach. With data-dependent bypass, we demonstrate improved performance over AIG. With data-independent bypass, as in stochastic depth, we observe mode collapse and effectively prune layers. We demonstrate our techniques on ResNet-50 and ResNet-101 for ImageNet , where our techniques produce improved accuracy (.15--.41% in precision@1) with substantially less computation (bypassing 25--40% of the layers).