 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal Force: Teaching Video Models To Accomplish Physics-Conditioned Goals
Jan 09, 2026Recent advancements in video generation have enabled the development of ``world models'' capable of simulating potential futures for robotics and planning. However, specifying precise goals for these models remains a challenge; text instructions are often too abstract to capture physical nuances, while target images are frequently infeasible to specify for dynamic tasks. To address this, we introduce Goal Force, a novel framework that allows users to define goals via explicit force vectors and intermediate dynamics, mirroring how humans conceptualize physical tasks. We train a video generation model on a curated dataset of synthetic causal primitives-such as elastic collisions and falling dominos-teaching it to propagate forces through time and space. Despite being trained on simple physics data, our model exhibits remarkable zero-shot generalization to complex, real-world scenarios, including tool manipulation and multi-object causal chains. Our results suggest that by grounding video generation in fundamental physical interactions, models can emerge as implicit neural physics simulators, enabling precise, physics-aware planning without reliance on external engines. We release all datasets, code, model weights, and interactive video demos at our project page.
GeCo: A Differentiable Geometric Consistency Metric for Video Generation
Dec 25, 2025We introduce GeCo, a geometry-grounded metric for jointly detecting geometric deformation and occlusion-inconsistency artifacts in static scenes. By fusing residual motion and depth priors, GeCo produces interpretable, dense consistency maps that reveal these artifacts. We use GeCo to systematically benchmark recent video generation models, uncovering common failure modes, and further employ it as a training-free guidance loss to reduce deformation artifacts during video generation.
VLIC: Vision-Language Models As Perceptual Judges for Human-Aligned Image Compression
Dec 17, 2025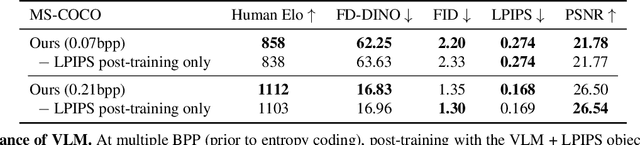

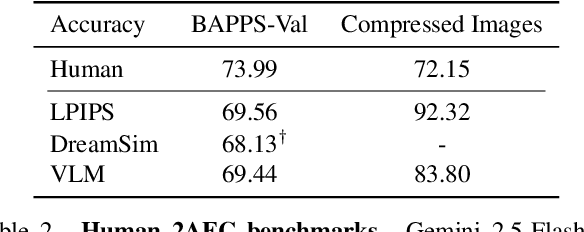
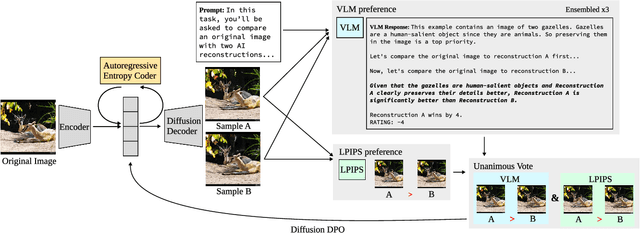
Evaluations of image compression performance which include human preferences have generally found that naive distortion functions such as MSE are insufficiently aligned to human perception. In order to align compression models to human perception, prior work has employed differentiable perceptual losses consisting of neural networks calibrated on large-scale datasets of human psycho-visual judgments. We show that, surprisingly, state-of-the-art vision-language models (VLMs) can replicate binary human two-alternative forced choice (2AFC) judgments zero-shot when asked to reason about the differences between pairs of images. Motivated to exploit the powerful zero-shot visual reasoning capabilities of VLMs, we propose Vision-Language Models for Image Compression (VLIC), a diffusion-based image compression system designed to be post-trained with binary VLM judgments. VLIC leverages existing techniques for diffusion model post-training with preferences, rather than distilling the VLM judgments into a separate perceptual loss network. We show that calibrating this system on VLM judgments produces competitive or state-of-the-art performance on human-aligned visual compression depending on the dataset, according to perceptual metrics and large-scale user studies. We additionally conduct an extensive analysis of the VLM-based reward design and training procedure and share important insights. More visuals are available at https://kylesargent.github.io/vlic
Force Prompting: Video Generation Models Can Learn and Generalize Physics-based Control Signals
May 26, 2025



Recent advances in video generation models have sparked interest in world models capable of simulating realistic environments. While navigation has been well-explored, physically meaningful interactions that mimic real-world forces remain largely understudied. In this work, we investigate using physical forces as a control signal for video generation and propose force prompts which enable users to interact with images through both localized point forces, such as poking a plant, and global wind force fields, such as wind blowing on fabric. We demonstrate that these force prompts can enable videos to respond realistically to physical control signals by leveraging the visual and motion prior in the original pretrained model, without using any 3D asset or physics simulator at inference. The primary challenge of force prompting is the difficulty in obtaining high quality paired force-video training data, both in the real world due to the difficulty of obtaining force signals, and in synthetic data due to limitations in the visual quality and domain diversity of physics simulators. Our key finding is that video generation models can generalize remarkably well when adapted to follow physical force conditioning from videos synthesized by Blender, even with limited demonstrations of few objects. Our method can generate videos which simulate forces across diverse geometries, settings, and materials. We also try to understand the source of this generalization and perform ablations that reveal two key elements: visual diversity and the use of specific text keywords during training. Our approach is trained on only around 15k training examples for a single day on four A100 GPUs, and outperforms existing methods on force adherence and physics realism, bringing world models closer to real-world physics interactions. We release all datasets, code, weights, and interactive video demos at our project page.
WonderPlay: Dynamic 3D Scene Generation from a Single Image and Actions
May 23, 2025WonderPlay is a novel framework integrating physics simulation with video generation for generating action-conditioned dynamic 3D scenes from a single image. While prior works are restricted to rigid body or simple elastic dynamics, WonderPlay features a hybrid generative simulator to synthesize a wide range of 3D dynamics. The hybrid generative simulator first uses a physics solver to simulate coarse 3D dynamics, which subsequently conditions a video generator to produce a video with finer, more realistic motion. The generated video is then used to update the simulated dynamic 3D scene, closing the loop between the physics solver and the video generator. This approach enables intuitive user control to be combined with the accurate dynamics of physics-based simulators and the expressivity of diffusion-based video generators. Experimental results demonstrate that WonderPlay enables users to interact with various scenes of diverse content, including cloth, sand, snow, liquid, smoke, elastic, and rigid bodies -- all using a single image input. Code will be made public. Project website: https://kyleleey.github.io/WonderPlay/
Motion Prompting: Controlling Video Generation with Motion Trajectories
Dec 03, 2024Motion control is crucial for generating expressive and compelling video content; however, most existing video generation models rely mainly on text prompts for control, which struggle to capture the nuances of dynamic actions and temporal compositions. To this end, we train a video generation model conditioned on spatio-temporally sparse or dense motion trajectories. In contrast to prior motion conditioning work, this flexible representation can encode any number of trajectories, object-specific or global scene motion, and temporally sparse motion; due to its flexibility we refer to this conditioning as motion prompts. While users may directly specify sparse trajectories, we also show how to translate high-level user requests into detailed, semi-dense motion prompts, a process we term motion prompt expansion. We demonstrate the versatility of our approach through various applications, including camera and object motion control, "interacting" with an image, motion transfer, and image editing. Our results showcase emergent behaviors, such as realistic physics, suggesting the potential of motion prompts for probing video models and interacting with future generative world models. Finally, we evaluate quantitatively, conduct a human study, and demonstrate strong performance. Video results are available on our webpage: https://motion-prompting.github.io/
High-Resolution Frame Interpolation with Patch-based Cascaded Diffusion
Oct 15, 2024Despite the recent progress, existing frame interpolation methods still struggle with processing extremely high resolution input and handling challenging cases such as repetitive textures, thin objects, and large motion. To address these issues, we introduce a patch-based cascaded pixel diffusion model for frame interpolation, HiFI, that excels in these scenarios while achieving competitive performance on standard benchmarks. Cascades, which generate a series of images from low- to high-resolution, can help significantly with large or complex motion that require both global context for a coarse solution and detailed context for high resolution output. However, contrary to prior work on cascaded diffusion models which perform diffusion on increasingly large resolutions, we use a single model that always performs diffusion at the same resolution and upsamples by processing patches of the inputs and the prior solution. We show that this technique drastically reduces memory usage at inference time and also allows us to use a single model at test time, solving both frame interpolation and spatial up-sampling, saving training cost. We show that HiFI helps significantly with high resolution and complex repeated textures that require global context. HiFI demonstrates comparable or beyond state-of-the-art performance on multiple benchmarks (Vimeo, Xiph, X-Test, SEPE-8K). On our newly introduced dataset that focuses on particularly challenging cases, HiFI also significantly outperforms other baselines on these cases. Please visit our project page for video results: https://hifi-diffusion.github.io
A Simple Approach to Unifying Diffusion-based Conditional Generation
Oct 15, 2024
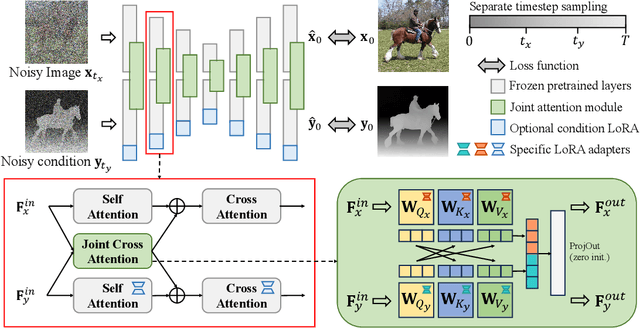
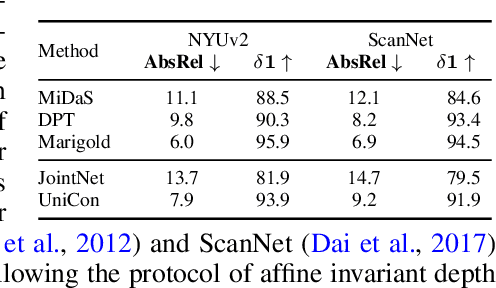

Recent progress in image generation has sparked research into controlling these models through condition signals, with various methods addressing specific challenges in conditional generation. Instead of proposing another specialized technique, we introduce a simple, unified framework to handle diverse conditional generation tasks involving a specific image-condition correlation. By learning a joint distribution over a correlated image pair (e.g. image and depth) with a diffusion model, our approach enables versatile capabilities via different inference-time sampling schemes, including controllable image generation (e.g. depth to image), estimation (e.g. image to depth), signal guidance, joint generation (image & depth), and coarse control. Previous attempts at unification often introduce significant complexity through multi-stage training, architectural modification, or increased parameter counts. In contrast, our simple formulation requires a single, computationally efficient training stage, maintains the standard model input, and adds minimal learned parameters (15% of the base model). Moreover, our model supports additional capabilities like non-spatially aligned and coarse conditioning. Extensive results show that our single model can produce comparable results with specialized methods and better results than prior unified methods. We also demonstrate that multiple models can be effectively combined for multi-signal conditional generation.
MonST3R: A Simple Approach for Estimating Geometry in the Presence of Motion
Oct 04, 2024



Estimating geometry from dynamic scenes, where objects move and deform over time, remains a core challenge in computer vision. Current approaches often rely on multi-stage pipelines or global optimizations that decompose the problem into subtasks, like depth and flow, leading to complex systems prone to errors. In this paper, we present Motion DUSt3R (MonST3R), a novel geometry-first approach that directly estimates per-timestep geometry from dynamic scenes. Our key insight is that by simply estimating a pointmap for each timestep, we can effectively adapt DUST3R's representation, previously only used for static scenes, to dynamic scenes. However, this approach presents a significant challenge: the scarcity of suitable training data, namely dynamic, posed videos with depth labels. Despite this, we show that by posing the problem as a fine-tuning task, identifying several suitable datasets, and strategically training the model on this limited data, we can surprisingly enable the model to handle dynamics, even without an explicit motion representation. Based on this, we introduce new optimizations for several downstream video-specific tasks and demonstrate strong performance on video depth and camera pose estimation, outperforming prior work in terms of robustness and efficiency. Moreover, MonST3R shows promising results for primarily feed-forward 4D reconstruction.
WonderWorld: Interactive 3D Scene Generation from a Single Image
Jun 14, 2024We present WonderWorld, a novel framework for interactive 3D scene extrapolation that enables users to explore and shape virtual environments based on a single input image and user-specified text. While significant improvements have been made to the visual quality of scene generation, existing methods are run offline, taking tens of minutes to hours to generate a scene. By leveraging Fast Gaussian Surfels and a guided diffusion-based depth estimation method, WonderWorld generates geometrically consistent extrapolation while significantly reducing computational time. Our framework generates connected and diverse 3D scenes in less than 10 seconds on a single A6000 GPU, enabling real-time user interaction and exploration. We demonstrate the potential of WonderWorld for applications in virtual reality, gaming, and creative design, where users can quickly generate and navigate immersive, potentially infinite virtual worlds from a single image. Our approach represents a significant advancement in interactive 3D scene generation, opening up new possibilities for user-driven content creation and exploration in virtual environments. We will release full code and software for reproducibility. Project website: https://WonderWorld-2024.github.io/