 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnder One Sun: Multi-Object Generative Perception of Materials and Illumination
Mar 19, 2026We introduce Multi-Object Generative Perception (MultiGP), a generative inverse rendering method for stochastic sampling of all radiometric constituents -- reflectance, texture, and illumination -- underlying object appearance from a single image. Our key idea to solve this inherently ambiguous radiometric disentanglement is to leverage the fact that while their texture and reflectance may differ, objects in the same scene are all lit by the same illumination. MultiGP exploits this consensus to produce samples of reflectance, texture, and illumination from a single image of known shapes based on four key technical contributions: a cascaded end-to-end architecture that combines image-space and angular-space disentanglement; Coordinated Guidance for diffusion convergence to a single consistent illumination estimate; Axial Attention applied to facilitate ``cross-talk'' between objects of different reflectance; and a Texture Extraction ControlNet to preserve high-frequency texture details while ensuring decoupling from estimated lighting. Experimental results demonstrate that MultiGP effectively leverages the complementary spatial and frequency characteristics of multiple object appearances to recover individual texture and reflectance as well as the common illumination.
UFO-4D: Unposed Feedforward 4D Reconstruction from Two Images
Mar 05, 2026Dense 4D reconstruction from unposed images remains a critical challenge, with current methods relying on slow test-time optimization or fragmented, task-specific feedforward models. We introduce UFO-4D, a unified feedforward framework to reconstruct a dense, explicit 4D representation from just a pair of unposed images. UFO-4D directly estimates dynamic 3D Gaussian Splats, enabling the joint and consistent estimation of 3D geometry, 3D motion, and camera pose in a feedforward manner. Our core insight is that differentiably rendering multiple signals from a single Dynamic 3D Gaussian representation offers major training advantages. This approach enables a self-supervised image synthesis loss while tightly coupling appearance, depth, and motion. Since all modalities share the same geometric primitives, supervising one inherently regularizes and improves the others. This synergy overcomes data scarcity, allowing UFO-4D to outperform prior work by up to 3 times in joint geometry, motion, and camera pose estimation. Our representation also enables high-fidelity 4D interpolation across novel views and time. Please visit our project page for visual results: https://ufo-4d.github.io/
GeCo: A Differentiable Geometric Consistency Metric for Video Generation
Dec 25, 2025We introduce GeCo, a geometry-grounded metric for jointly detecting geometric deformation and occlusion-inconsistency artifacts in static scenes. By fusing residual motion and depth priors, GeCo produces interpretable, dense consistency maps that reveal these artifacts. We use GeCo to systematically benchmark recent video generation models, uncovering common failure modes, and further employ it as a training-free guidance loss to reduce deformation artifacts during video generation.
CObL: Toward Zero-Shot Ordinal Layering without User Prompting
Aug 11, 2025



Vision benefits from grouping pixels into objects and understanding their spatial relationships, both laterally and in depth. We capture this with a scene representation comprising an occlusion-ordered stack of "object layers," each containing an isolated and amodally-completed object. To infer this representation from an image, we introduce a diffusion-based architecture named Concurrent Object Layers (CObL). CObL generates a stack of object layers in parallel, using Stable Diffusion as a prior for natural objects and inference-time guidance to ensure the inferred layers composite back to the input image. We train CObL using a few thousand synthetically-generated images of multi-object tabletop scenes, and we find that it zero-shot generalizes to photographs of real-world tabletops with varying numbers of novel objects. In contrast to recent models for amodal object completion, CObL reconstructs multiple occluded objects without user prompting and without knowing the number of objects beforehand. Unlike previous models for unsupervised object-centric representation learning, CObL is not limited to the world it was trained in.
Grayscale to Hyperspectral at Any Resolution Using a Phase-Only Lens
Dec 03, 2024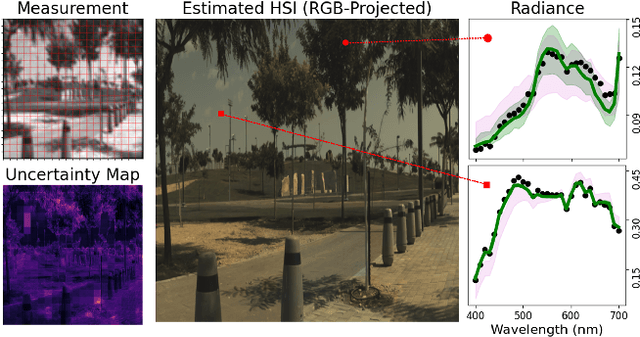
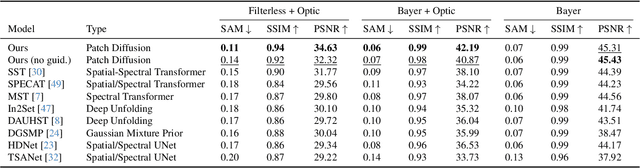
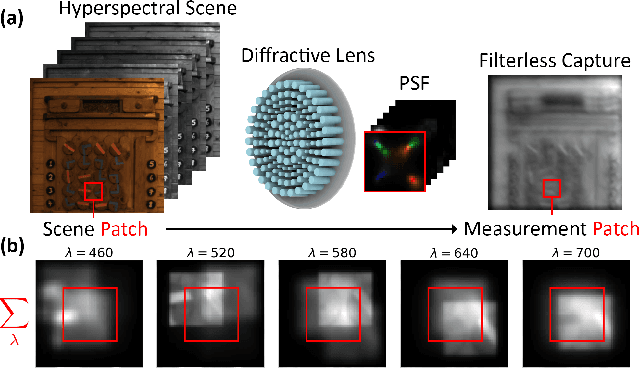
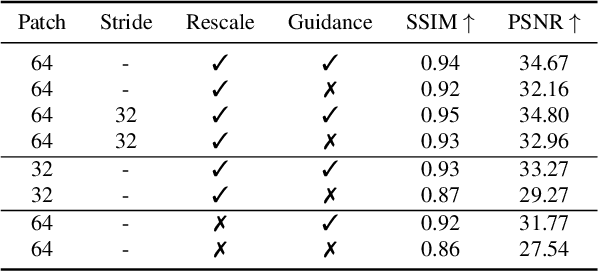
We consider the problem of reconstructing a $H\times W\times 31$ hyperspectral image from a $H\times W$ grayscale snapshot measurement that is captured using a single diffractive optic and a filterless panchromatic photosensor. This problem is severely ill-posed, and we present the first model that is able to produce high-quality results. We train a conditional denoising diffusion model that maps a small grayscale measurement patch to a hyperspectral patch. We then deploy the model to many patches in parallel, using global physics-based guidance to synchronize the patch predictions. Our model can be trained using small hyperspectral datasets and then deployed to reconstruct hyperspectral images of arbitrary size. Also, by drawing multiple samples with different seeds, our model produces useful uncertainty maps. We show that our model achieves state-of-the-art performance on previous snapshot hyperspectral benchmarks where reconstruction is better conditioned. Our work lays the foundation for a new class of high-resolution hyperspectral imagers that are compact and light-efficient.
Multistable Shape from Shading Emerges from Patch Diffusion
May 23, 2024Models for monocular shape reconstruction of surfaces with diffuse reflection -- shape from shading -- ought to produce distributions of outputs, because there are fundamental mathematical ambiguities of both continuous (e.g., bas-relief) and discrete (e.g., convex/concave) varieties which are also experienced by humans. Yet, the outputs of current models are limited to point estimates or tight distributions around single modes, which prevent them from capturing these effects. We introduce a model that reconstructs a multimodal distribution of shapes from a single shading image, which aligns with the human experience of multistable perception. We train a small denoising diffusion process to generate surface normal fields from $16\times 16$ patches of synthetic images of everyday 3D objects. We deploy this model patch-wise at multiple scales, with guidance from inter-patch shape consistency constraints. Despite its relatively small parameter count and predominantly bottom-up structure, we show that multistable shape explanations emerge from this model for ''ambiguous'' test images that humans experience as being multistable. At the same time, the model produces veridical shape estimates for object-like images that include distinctive occluding contours and appear less ambiguous. This may inspire new architectures for stochastic 3D shape perception that are more efficient and better aligned with human experience.
Boundary Attention: Learning to Find Faint Boundaries at Any Resolution
Jan 01, 2024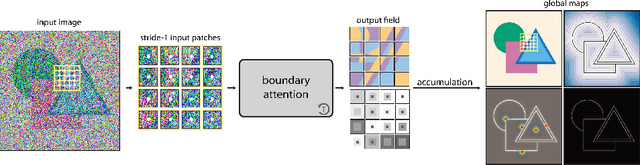
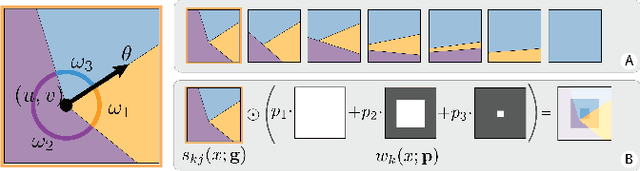
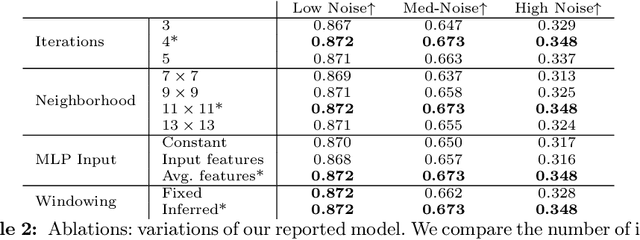
We present a differentiable model that explicitly models boundaries -- including contours, corners and junctions -- using a new mechanism that we call boundary attention. We show that our model provides accurate results even when the boundary signal is very weak or is swamped by noise. Compared to previous classical methods for finding faint boundaries, our model has the advantages of being differentiable; being scalable to larger images; and automatically adapting to an appropriate level of geometric detail in each part of an image. Compared to previous deep methods for finding boundaries via end-to-end training, it has the advantages of providing sub-pixel precision, being more resilient to noise, and being able to process any image at its native resolution and aspect ratio.
Polarization Multi-Image Synthesis with Birefringent Metasurfaces
Jul 16, 2023



Optical metasurfaces composed of precisely engineered nanostructures have gained significant attention for their ability to manipulate light and implement distinct functionalities based on the properties of the incident field. Computational imaging systems have started harnessing this capability to produce sets of coded measurements that benefit certain tasks when paired with digital post-processing. Inspired by these works, we introduce a new system that uses a birefringent metasurface with a polarizer-mosaicked photosensor to capture four optically-coded measurements in a single exposure. We apply this system to the task of incoherent opto-electronic filtering, where digital spatial-filtering operations are replaced by simpler, per-pixel sums across the four polarization channels, independent of the spatial filter size. In contrast to previous work on incoherent opto-electronic filtering that can realize only one spatial filter, our approach can realize a continuous family of filters from a single capture, with filters being selected from the family by adjusting the post-capture digital summation weights. To find a metasurface that can realize a set of user-specified spatial filters, we introduce a form of gradient descent with a novel regularizer that encourages light efficiency and a high signal-to-noise ratio. We demonstrate several examples in simulation and with fabricated prototypes, including some with spatial filters that have prescribed variations with respect to depth and wavelength.
Eclipse: Disambiguating Illumination and Materials using Unintended Shadows
Jun 08, 2023
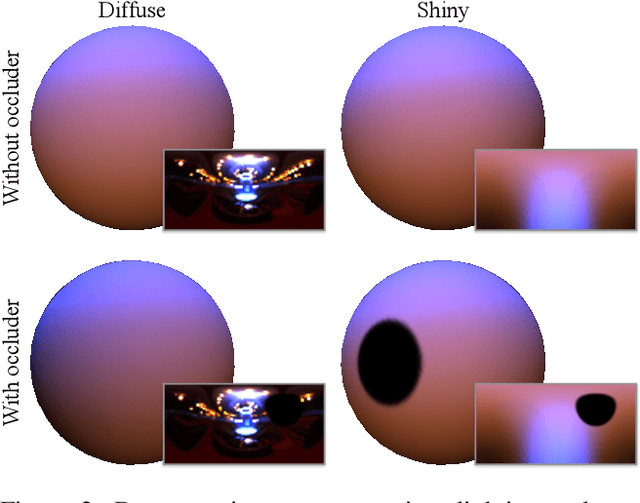


Decomposing an object's appearance into representations of its materials and the surrounding illumination is difficult, even when the object's 3D shape is known beforehand. This problem is ill-conditioned because diffuse materials severely blur incoming light, and is ill-posed because diffuse materials under high-frequency lighting can be indistinguishable from shiny materials under low-frequency lighting. We show that it is possible to recover precise materials and illumination -- even from diffuse objects -- by exploiting unintended shadows, like the ones cast onto an object by the photographer who moves around it. These shadows are a nuisance in most previous inverse rendering pipelines, but here we exploit them as signals that improve conditioning and help resolve material-lighting ambiguities. We present a method based on differentiable Monte Carlo ray tracing that uses images of an object to jointly recover its spatially-varying materials, the surrounding illumination environment, and the shapes of the unseen light occluders who inadvertently cast shadows upon it.
Ref-NeRF: Structured View-Dependent Appearance for Neural Radiance Fields
Dec 07, 2021
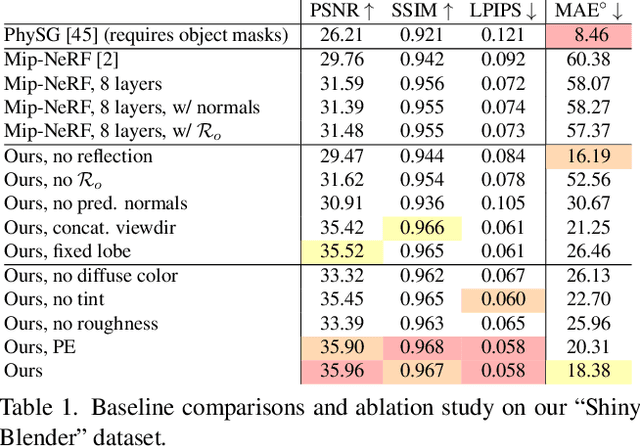
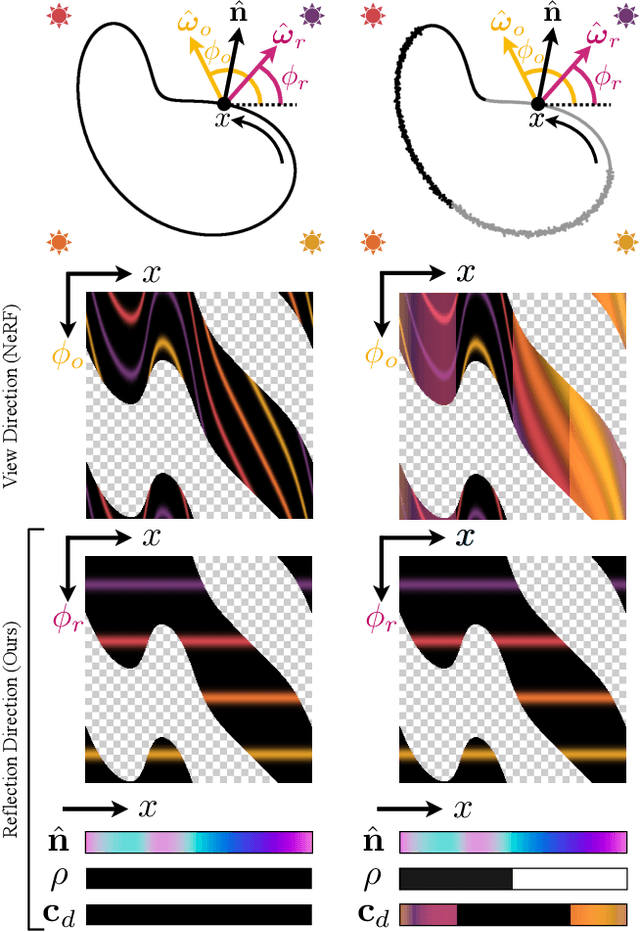
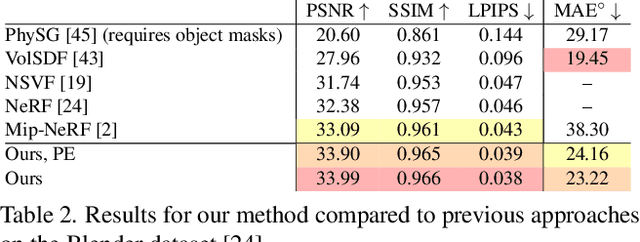
Neural Radiance Fields (NeRF) is a popular view synthesis technique that represents a scene as a continuous volumetric function, parameterized by multilayer perceptrons that provide the volume density and view-dependent emitted radiance at each location. While NeRF-based techniques excel at representing fine geometric structures with smoothly varying view-dependent appearance, they often fail to accurately capture and reproduce the appearance of glossy surfaces. We address this limitation by introducing Ref-NeRF, which replaces NeRF's parameterization of view-dependent outgoing radiance with a representation of reflected radiance and structures this function using a collection of spatially-varying scene properties. We show that together with a regularizer on normal vectors, our model significantly improves the realism and accuracy of specular reflections. Furthermore, we show that our model's internal representation of outgoing radiance is interpretable and useful for scene editing.