 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlash Cache: Reducing Bias in Radiance Cache Based Inverse Rendering
Sep 09, 2024State-of-the-art techniques for 3D reconstruction are largely based on volumetric scene representations, which require sampling multiple points to compute the color arriving along a ray. Using these representations for more general inverse rendering -- reconstructing geometry, materials, and lighting from observed images -- is challenging because recursively path-tracing such volumetric representations is expensive. Recent works alleviate this issue through the use of radiance caches: data structures that store the steady-state, infinite-bounce radiance arriving at any point from any direction. However, these solutions rely on approximations that introduce bias into the renderings and, more importantly, into the gradients used for optimization. We present a method that avoids these approximations while remaining computationally efficient. In particular, we leverage two techniques to reduce variance for unbiased estimators of the rendering equation: (1) an occlusion-aware importance sampler for incoming illumination and (2) a fast cache architecture that can be used as a control variate for the radiance from a high-quality, but more expensive, volumetric cache. We show that by removing these biases our approach improves the generality of radiance cache based inverse rendering, as well as increasing quality in the presence of challenging light transport effects such as specular reflections.
NeRF-Casting: Improved View-Dependent Appearance with Consistent Reflections
May 23, 2024

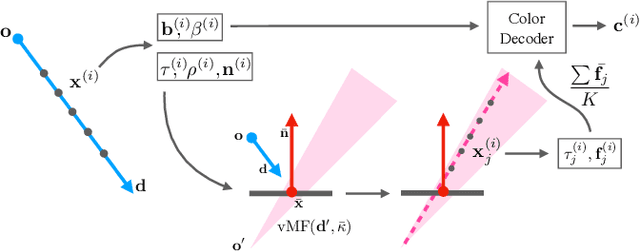

Neural Radiance Fields (NeRFs) typically struggle to reconstruct and render highly specular objects, whose appearance varies quickly with changes in viewpoint. Recent works have improved NeRF's ability to render detailed specular appearance of distant environment illumination, but are unable to synthesize consistent reflections of closer content. Moreover, these techniques rely on large computationally-expensive neural networks to model outgoing radiance, which severely limits optimization and rendering speed. We address these issues with an approach based on ray tracing: instead of querying an expensive neural network for the outgoing view-dependent radiance at points along each camera ray, our model casts reflection rays from these points and traces them through the NeRF representation to render feature vectors which are decoded into color using a small inexpensive network. We demonstrate that our model outperforms prior methods for view synthesis of scenes containing shiny objects, and that it is the only existing NeRF method that can synthesize photorealistic specular appearance and reflections in real-world scenes, while requiring comparable optimization time to current state-of-the-art view synthesis models.
GaussianFlow: Splatting Gaussian Dynamics for 4D Content Creation
Mar 19, 2024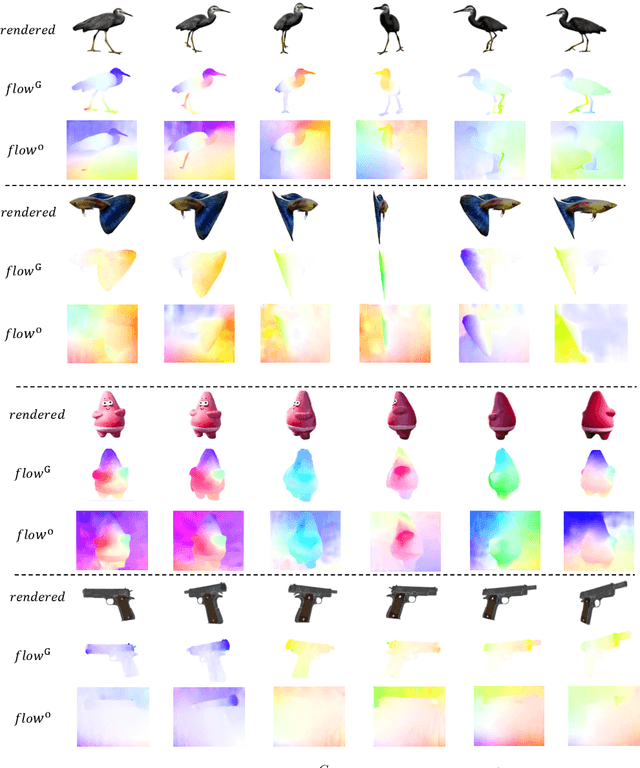
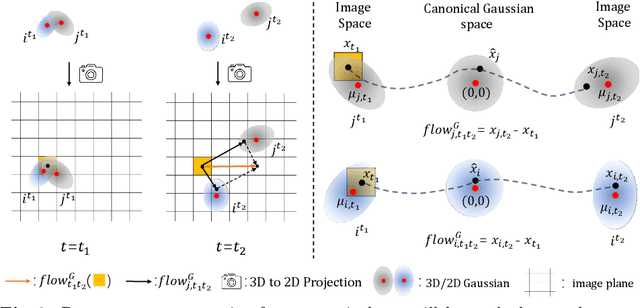

Creating 4D fields of Gaussian Splatting from images or videos is a challenging task due to its under-constrained nature. While the optimization can draw photometric reference from the input videos or be regulated by generative models, directly supervising Gaussian motions remains underexplored. In this paper, we introduce a novel concept, Gaussian flow, which connects the dynamics of 3D Gaussians and pixel velocities between consecutive frames. The Gaussian flow can be efficiently obtained by splatting Gaussian dynamics into the image space. This differentiable process enables direct dynamic supervision from optical flow. Our method significantly benefits 4D dynamic content generation and 4D novel view synthesis with Gaussian Splatting, especially for contents with rich motions that are hard to be handled by existing methods. The common color drifting issue that happens in 4D generation is also resolved with improved Guassian dynamics. Superior visual quality on extensive experiments demonstrates our method's effectiveness. Quantitative and qualitative evaluations show that our method achieves state-of-the-art results on both tasks of 4D generation and 4D novel view synthesis. Project page: https://zerg-overmind.github.io/GaussianFlow.github.io/
Disentangled 3D Scene Generation with Layout Learning
Feb 26, 2024We introduce a method to generate 3D scenes that are disentangled into their component objects. This disentanglement is unsupervised, relying only on the knowledge of a large pretrained text-to-image model. Our key insight is that objects can be discovered by finding parts of a 3D scene that, when rearranged spatially, still produce valid configurations of the same scene. Concretely, our method jointly optimizes multiple NeRFs from scratch - each representing its own object - along with a set of layouts that composite these objects into scenes. We then encourage these composited scenes to be in-distribution according to the image generator. We show that despite its simplicity, our approach successfully generates 3D scenes decomposed into individual objects, enabling new capabilities in text-to-3D content creation. For results and an interactive demo, see our project page at https://dave.ml/layoutlearning/
Binary Opacity Grids: Capturing Fine Geometric Detail for Mesh-Based View Synthesis
Feb 19, 2024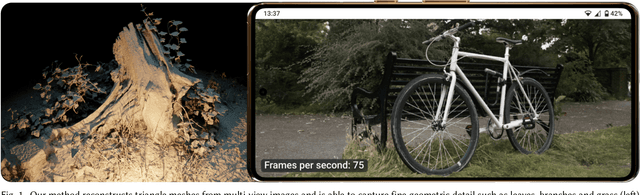



While surface-based view synthesis algorithms are appealing due to their low computational requirements, they often struggle to reproduce thin structures. In contrast, more expensive methods that model the scene's geometry as a volumetric density field (e.g. NeRF) excel at reconstructing fine geometric detail. However, density fields often represent geometry in a "fuzzy" manner, which hinders exact localization of the surface. In this work, we modify density fields to encourage them to converge towards surfaces, without compromising their ability to reconstruct thin structures. First, we employ a discrete opacity grid representation instead of a continuous density field, which allows opacity values to discontinuously transition from zero to one at the surface. Second, we anti-alias by casting multiple rays per pixel, which allows occlusion boundaries and subpixel structures to be modelled without using semi-transparent voxels. Third, we minimize the binary entropy of the opacity values, which facilitates the extraction of surface geometry by encouraging opacity values to binarize towards the end of training. Lastly, we develop a fusion-based meshing strategy followed by mesh simplification and appearance model fitting. The compact meshes produced by our model can be rendered in real-time on mobile devices and achieve significantly higher view synthesis quality compared to existing mesh-based approaches.
Nuvo: Neural UV Mapping for Unruly 3D Representations
Dec 11, 2023Existing UV mapping algorithms are designed to operate on well-behaved meshes, instead of the geometry representations produced by state-of-the-art 3D reconstruction and generation techniques. As such, applying these methods to the volume densities recovered by neural radiance fields and related techniques (or meshes triangulated from such fields) results in texture atlases that are too fragmented to be useful for tasks such as view synthesis or appearance editing. We present a UV mapping method designed to operate on geometry produced by 3D reconstruction and generation techniques. Instead of computing a mapping defined on a mesh's vertices, our method Nuvo uses a neural field to represent a continuous UV mapping, and optimizes it to be a valid and well-behaved mapping for just the set of visible points, i.e. only points that affect the scene's appearance. We show that our model is robust to the challenges posed by ill-behaved geometry, and that it produces editable UV mappings that can represent detailed appearance.
ReconFusion: 3D Reconstruction with Diffusion Priors
Dec 05, 20233D reconstruction methods such as Neural Radiance Fields (NeRFs) excel at rendering photorealistic novel views of complex scenes. However, recovering a high-quality NeRF typically requires tens to hundreds of input images, resulting in a time-consuming capture process. We present ReconFusion to reconstruct real-world scenes using only a few photos. Our approach leverages a diffusion prior for novel view synthesis, trained on synthetic and multiview datasets, which regularizes a NeRF-based 3D reconstruction pipeline at novel camera poses beyond those captured by the set of input images. Our method synthesizes realistic geometry and texture in underconstrained regions while preserving the appearance of observed regions. We perform an extensive evaluation across various real-world datasets, including forward-facing and 360-degree scenes, demonstrating significant performance improvements over previous few-view NeRF reconstruction approaches.
Generative Powers of Ten
Dec 04, 2023We present a method that uses a text-to-image model to generate consistent content across multiple image scales, enabling extreme semantic zooms into a scene, e.g., ranging from a wide-angle landscape view of a forest to a macro shot of an insect sitting on one of the tree branches. We achieve this through a joint multi-scale diffusion sampling approach that encourages consistency across different scales while preserving the integrity of each individual sampling process. Since each generated scale is guided by a different text prompt, our method enables deeper levels of zoom than traditional super-resolution methods that may struggle to create new contextual structure at vastly different scales. We compare our method qualitatively with alternative techniques in image super-resolution and outpainting, and show that our method is most effective at generating consistent multi-scale content.
State of the Art on Diffusion Models for Visual Computing
Oct 11, 2023The field of visual computing is rapidly advancing due to the emergence of generative artificial intelligence (AI), which unlocks unprecedented capabilities for the generation, editing, and reconstruction of images, videos, and 3D scenes. In these domains, diffusion models are the generative AI architecture of choice. Within the last year alone, the literature on diffusion-based tools and applications has seen exponential growth and relevant papers are published across the computer graphics, computer vision, and AI communities with new works appearing daily on arXiv. This rapid growth of the field makes it difficult to keep up with all recent developments. The goal of this state-of-the-art report (STAR) is to introduce the basic mathematical concepts of diffusion models, implementation details and design choices of the popular Stable Diffusion model, as well as overview important aspects of these generative AI tools, including personalization, conditioning, inversion, among others. Moreover, we give a comprehensive overview of the rapidly growing literature on diffusion-based generation and editing, categorized by the type of generated medium, including 2D images, videos, 3D objects, locomotion, and 4D scenes. Finally, we discuss available datasets, metrics, open challenges, and social implications. This STAR provides an intuitive starting point to explore this exciting topic for researchers, artists, and practitioners alike.
CamP: Camera Preconditioning for Neural Radiance Fields
Aug 30, 2023



Neural Radiance Fields (NeRF) can be optimized to obtain high-fidelity 3D scene reconstructions of objects and large-scale scenes. However, NeRFs require accurate camera parameters as input -- inaccurate camera parameters result in blurry renderings. Extrinsic and intrinsic camera parameters are usually estimated using Structure-from-Motion (SfM) methods as a pre-processing step to NeRF, but these techniques rarely yield perfect estimates. Thus, prior works have proposed jointly optimizing camera parameters alongside a NeRF, but these methods are prone to local minima in challenging settings. In this work, we analyze how different camera parameterizations affect this joint optimization problem, and observe that standard parameterizations exhibit large differences in magnitude with respect to small perturbations, which can lead to an ill-conditioned optimization problem. We propose using a proxy problem to compute a whitening transform that eliminates the correlation between camera parameters and normalizes their effects, and we propose to use this transform as a preconditioner for the camera parameters during joint optimization. Our preconditioned camera optimization significantly improves reconstruction quality on scenes from the Mip-NeRF 360 dataset: we reduce error rates (RMSE) by 67% compared to state-of-the-art NeRF approaches that do not optimize for cameras like Zip-NeRF, and by 29% relative to state-of-the-art joint optimization approaches using the camera parameterization of SCNeRF. Our approach is easy to implement, does not significantly increase runtime, can be applied to a wide variety of camera parameterizations, and can straightforwardly be incorporated into other NeRF-like models.