 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIllumiNeRF: 3D Relighting without Inverse Rendering
Jun 10, 2024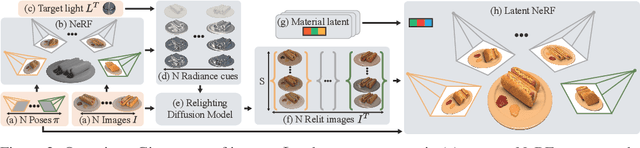



Existing methods for relightable view synthesis -- using a set of images of an object under unknown lighting to recover a 3D representation that can be rendered from novel viewpoints under a target illumination -- are based on inverse rendering, and attempt to disentangle the object geometry, materials, and lighting that explain the input images. Furthermore, this typically involves optimization through differentiable Monte Carlo rendering, which is brittle and computationally-expensive. In this work, we propose a simpler approach: we first relight each input image using an image diffusion model conditioned on lighting and then reconstruct a Neural Radiance Field (NeRF) with these relit images, from which we render novel views under the target lighting. We demonstrate that this strategy is surprisingly competitive and achieves state-of-the-art results on multiple relighting benchmarks. Please see our project page at https://illuminerf.github.io/.
ReconFusion: 3D Reconstruction with Diffusion Priors
Dec 05, 20233D reconstruction methods such as Neural Radiance Fields (NeRFs) excel at rendering photorealistic novel views of complex scenes. However, recovering a high-quality NeRF typically requires tens to hundreds of input images, resulting in a time-consuming capture process. We present ReconFusion to reconstruct real-world scenes using only a few photos. Our approach leverages a diffusion prior for novel view synthesis, trained on synthetic and multiview datasets, which regularizes a NeRF-based 3D reconstruction pipeline at novel camera poses beyond those captured by the set of input images. Our method synthesizes realistic geometry and texture in underconstrained regions while preserving the appearance of observed regions. We perform an extensive evaluation across various real-world datasets, including forward-facing and 360-degree scenes, demonstrating significant performance improvements over previous few-view NeRF reconstruction approaches.
CamP: Camera Preconditioning for Neural Radiance Fields
Aug 30, 2023



Neural Radiance Fields (NeRF) can be optimized to obtain high-fidelity 3D scene reconstructions of objects and large-scale scenes. However, NeRFs require accurate camera parameters as input -- inaccurate camera parameters result in blurry renderings. Extrinsic and intrinsic camera parameters are usually estimated using Structure-from-Motion (SfM) methods as a pre-processing step to NeRF, but these techniques rarely yield perfect estimates. Thus, prior works have proposed jointly optimizing camera parameters alongside a NeRF, but these methods are prone to local minima in challenging settings. In this work, we analyze how different camera parameterizations affect this joint optimization problem, and observe that standard parameterizations exhibit large differences in magnitude with respect to small perturbations, which can lead to an ill-conditioned optimization problem. We propose using a proxy problem to compute a whitening transform that eliminates the correlation between camera parameters and normalizes their effects, and we propose to use this transform as a preconditioner for the camera parameters during joint optimization. Our preconditioned camera optimization significantly improves reconstruction quality on scenes from the Mip-NeRF 360 dataset: we reduce error rates (RMSE) by 67% compared to state-of-the-art NeRF approaches that do not optimize for cameras like Zip-NeRF, and by 29% relative to state-of-the-art joint optimization approaches using the camera parameterization of SCNeRF. Our approach is easy to implement, does not significantly increase runtime, can be applied to a wide variety of camera parameterizations, and can straightforwardly be incorporated into other NeRF-like models.
HyperNeRF: A Higher-Dimensional Representation for Topologically Varying Neural Radiance Fields
Jun 24, 2021
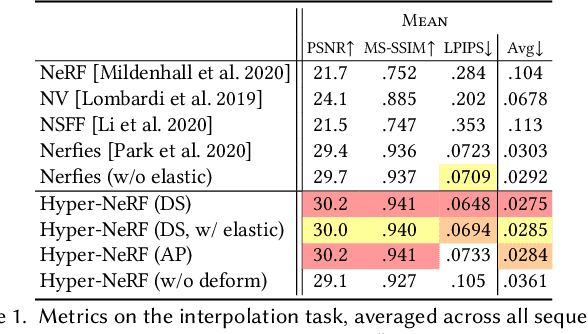
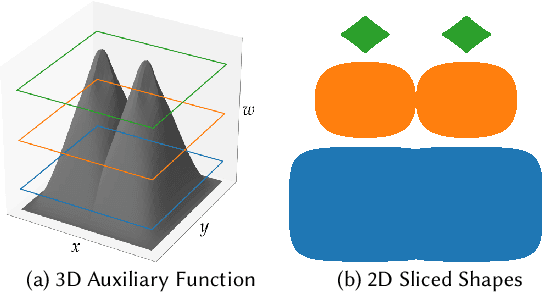
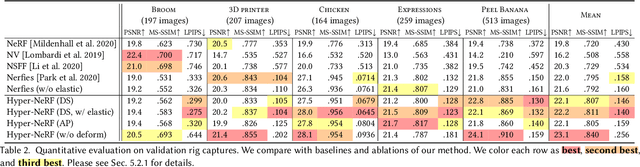
Neural Radiance Fields (NeRF) are able to reconstruct scenes with unprecedented fidelity, and various recent works have extended NeRF to handle dynamic scenes. A common approach to reconstruct such non-rigid scenes is through the use of a learned deformation field mapping from coordinates in each input image into a canonical template coordinate space. However, these deformation-based approaches struggle to model changes in topology, as topological changes require a discontinuity in the deformation field, but these deformation fields are necessarily continuous. We address this limitation by lifting NeRFs into a higher dimensional space, and by representing the 5D radiance field corresponding to each individual input image as a slice through this "hyper-space". Our method is inspired by level set methods, which model the evolution of surfaces as slices through a higher dimensional surface. We evaluate our method on two tasks: (i) interpolating smoothly between "moments", i.e., configurations of the scene, seen in the input images while maintaining visual plausibility, and (ii) novel-view synthesis at fixed moments. We show that our method, which we dub HyperNeRF, outperforms existing methods on both tasks by significant margins. Compared to Nerfies, HyperNeRF reduces average error rates by 8.6% for interpolation and 8.8% for novel-view synthesis, as measured by LPIPS.
FiG-NeRF: Figure-Ground Neural Radiance Fields for 3D Object Category Modelling
Apr 17, 2021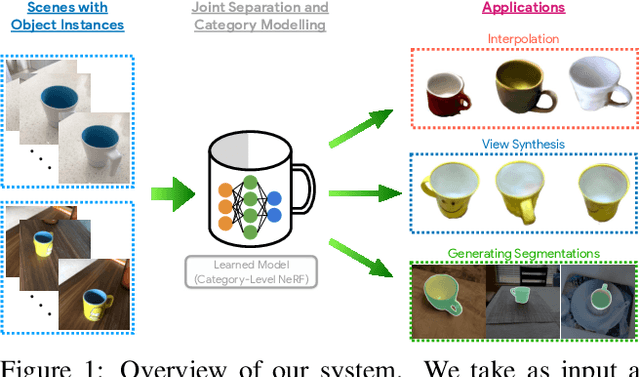

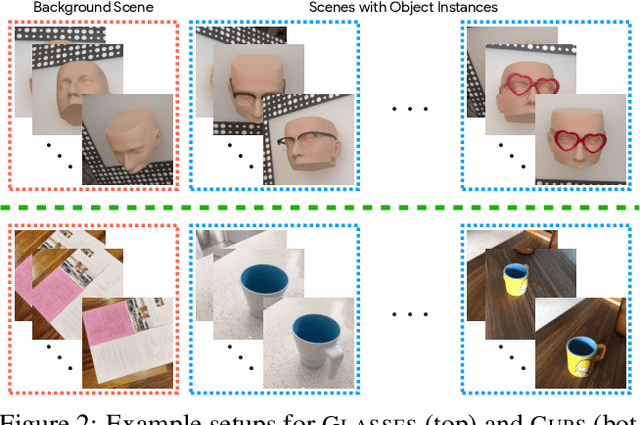
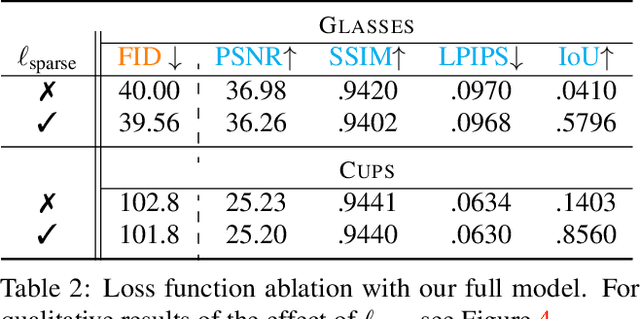
We investigate the use of Neural Radiance Fields (NeRF) to learn high quality 3D object category models from collections of input images. In contrast to previous work, we are able to do this whilst simultaneously separating foreground objects from their varying backgrounds. We achieve this via a 2-component NeRF model, FiG-NeRF, that prefers explanation of the scene as a geometrically constant background and a deformable foreground that represents the object category. We show that this method can learn accurate 3D object category models using only photometric supervision and casually captured images of the objects. Additionally, our 2-part decomposition allows the model to perform accurate and crisp amodal segmentation. We quantitatively evaluate our method with view synthesis and image fidelity metrics, using synthetic, lab-captured, and in-the-wild data. Our results demonstrate convincing 3D object category modelling that exceed the performance of existing methods.
Deformable Neural Radiance Fields
Nov 26, 2020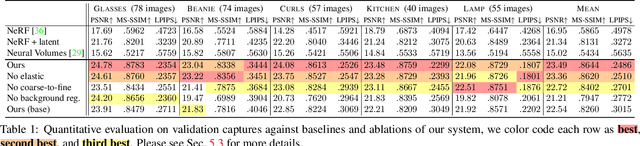


We present the first method capable of photorealistically reconstructing a non-rigidly deforming scene using photos/videos captured casually from mobile phones. Our approach -- D-NeRF -- augments neural radiance fields (NeRF) by optimizing an additional continuous volumetric deformation field that warps each observed point into a canonical 5D NeRF. We observe that these NeRF-like deformation fields are prone to local minima, and propose a coarse-to-fine optimization method for coordinate-based models that allows for more robust optimization. By adapting principles from geometry processing and physical simulation to NeRF-like models, we propose an elastic regularization of the deformation field that further improves robustness. We show that D-NeRF can turn casually captured selfie photos/videos into deformable NeRF models that allow for photorealistic renderings of the subject from arbitrary viewpoints, which we dub "nerfies." We evaluate our method by collecting data using a rig with two mobile phones that take time-synchronized photos, yielding train/validation images of the same pose at different viewpoints. We show that our method faithfully reconstructs non-rigidly deforming scenes and reproduces unseen views with high fidelity.
LatentFusion: End-to-End Differentiable Reconstruction and Rendering for Unseen Object Pose Estimation
Dec 13, 2019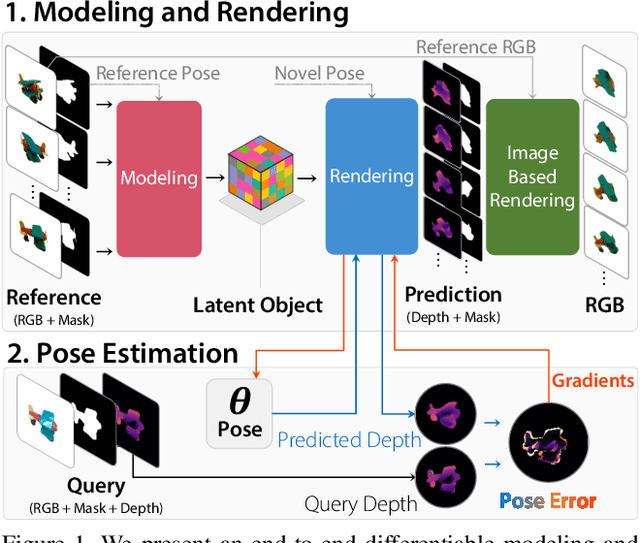
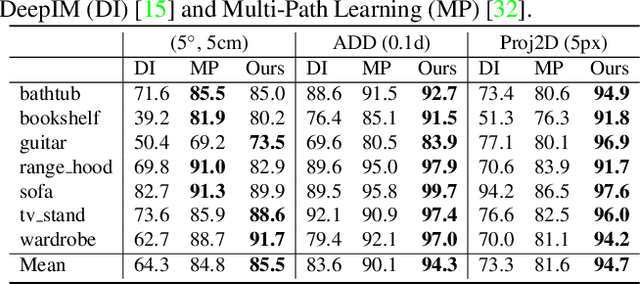
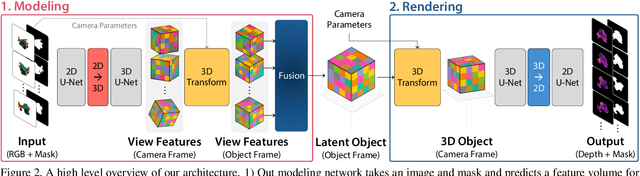
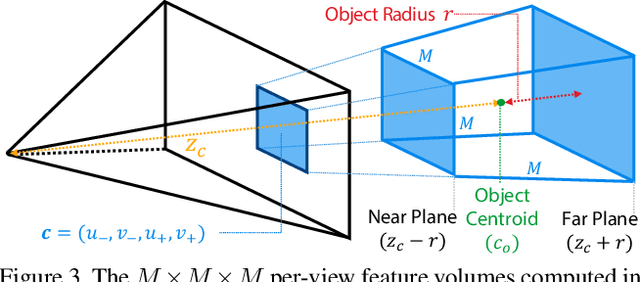
Current 6D object pose estimation methods usually require a 3D model for each object. These methods also require additional training in order to incorporate new objects. As a result, they are difficult to scale to a large number of objects and cannot be directly applied to unseen objects. In this work, we propose a novel framework for 6D pose estimation of unseen objects. We design an end-to-end neural network that reconstructs a latent 3D representation of an object using a small number of reference views of the object. Using the learned 3D representation, the network is able to render the object from arbitrary views. Using this neural renderer, we directly optimize for pose given an input image. By training our network with a large number of 3D shapes for reconstruction and rendering, our network generalizes well to unseen objects. We present a new dataset for unseen object pose estimation--MOPED. We evaluate the performance of our method for unseen object pose estimation on MOPED as well as the ModelNet dataset.
PhotoShape: Photorealistic Materials for Large-Scale Shape Collections
Sep 26, 2018
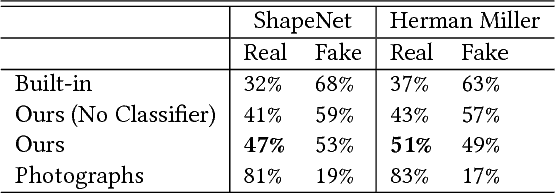


Existing online 3D shape repositories contain thousands of 3D models but lack photorealistic appearance. We present an approach to automatically assign high-quality, realistic appearance models to large scale 3D shape collections. The key idea is to jointly leverage three types of online data -- shape collections, material collections, and photo collections, using the photos as reference to guide assignment of materials to shapes. By generating a large number of synthetic renderings, we train a convolutional neural network to classify materials in real photos, and employ 3D-2D alignment techniques to transfer materials to different parts of each shape model. Our system produces photorealistic, relightable, 3D shapes (PhotoShapes).