 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentFusion: End-to-End Differentiable Reconstruction and Rendering for Unseen Object Pose Estimation
Paper and Code
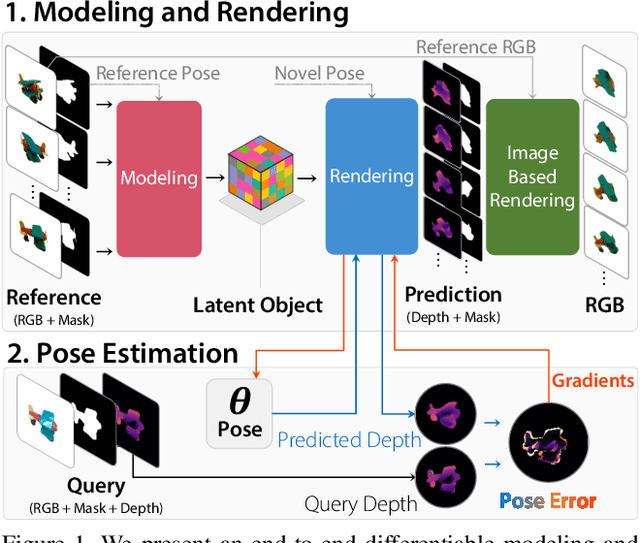
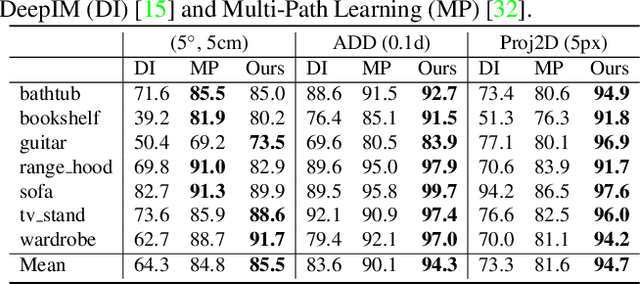
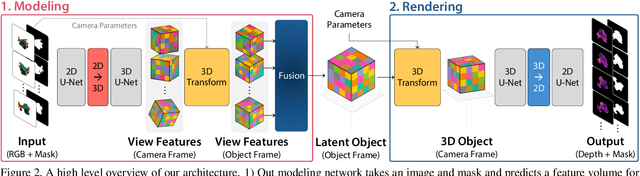
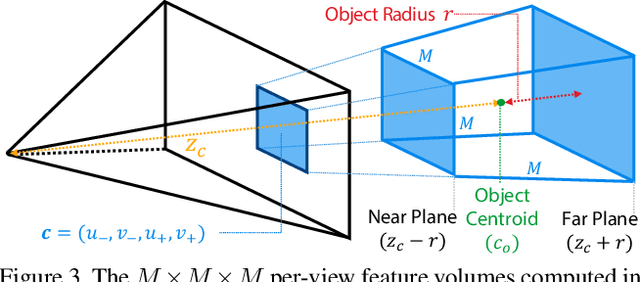
Current 6D object pose estimation methods usually require a 3D model for each object. These methods also require additional training in order to incorporate new objects. As a result, they are difficult to scale to a large number of objects and cannot be directly applied to unseen objects. In this work, we propose a novel framework for 6D pose estimation of unseen objects. We design an end-to-end neural network that reconstructs a latent 3D representation of an object using a small number of reference views of the object. Using the learned 3D representation, the network is able to render the object from arbitrary views. Using this neural renderer, we directly optimize for pose given an input image. By training our network with a large number of 3D shapes for reconstruction and rendering, our network generalizes well to unseen objects. We present a new dataset for unseen object pose estimation--MOPED. We evaluate the performance of our method for unseen object pose estimation on MOPED as well as the ModelNet dataset.