 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIllumiNeRF: 3D Relighting without Inverse Rendering
Jun 10, 2024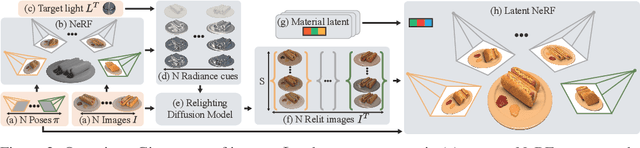



Existing methods for relightable view synthesis -- using a set of images of an object under unknown lighting to recover a 3D representation that can be rendered from novel viewpoints under a target illumination -- are based on inverse rendering, and attempt to disentangle the object geometry, materials, and lighting that explain the input images. Furthermore, this typically involves optimization through differentiable Monte Carlo rendering, which is brittle and computationally-expensive. In this work, we propose a simpler approach: we first relight each input image using an image diffusion model conditioned on lighting and then reconstruct a Neural Radiance Field (NeRF) with these relit images, from which we render novel views under the target lighting. We demonstrate that this strategy is surprisingly competitive and achieves state-of-the-art results on multiple relighting benchmarks. Please see our project page at https://illuminerf.github.io/.
SHINOBI: Shape and Illumination using Neural Object Decomposition via BRDF Optimization In-the-wild
Jan 18, 2024We present SHINOBI, an end-to-end framework for the reconstruction of shape, material, and illumination from object images captured with varying lighting, pose, and background. Inverse rendering of an object based on unconstrained image collections is a long-standing challenge in computer vision and graphics and requires a joint optimization over shape, radiance, and pose. We show that an implicit shape representation based on a multi-resolution hash encoding enables faster and robust shape reconstruction with joint camera alignment optimization that outperforms prior work. Further, to enable the editing of illumination and object reflectance (i.e. material) we jointly optimize BRDF and illumination together with the object's shape. Our method is class-agnostic and works on in-the-wild image collections of objects to produce relightable 3D assets for several use cases such as AR/VR, movies, games, etc. Project page: https://shinobi.aengelhardt.com Video: https://www.youtube.com/watch?v=iFENQ6AcYd8&feature=youtu.be