 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Neural Network and NER-Based Text Summarization
Feb 05, 2024With the abundance of data and information in todays time, it is nearly impossible for man, or, even machine, to go through all of the data line by line. What one usually does is to try to skim through the lines and retain the absolutely important information, that in a more formal term is called summarization. Text summarization is an important task that aims to compress lengthy documents or articles into shorter, coherent representations while preserving the core information and meaning. This project introduces an innovative approach to text summarization, leveraging the capabilities of Graph Neural Networks (GNNs) and Named Entity Recognition (NER) systems. GNNs, with their exceptional ability to capture and process the relational data inherent in textual information, are adept at understanding the complex structures within large documents. Meanwhile, NER systems contribute by identifying and emphasizing key entities, ensuring that the summarization process maintains a focus on the most critical aspects of the text. By integrating these two technologies, our method aims to enhances the efficiency of summarization and also tries to ensures a high degree relevance in the condensed content. This project, therefore, offers a promising direction for handling the ever increasing volume of textual data in an information-saturated world.
HyperNeRF: A Higher-Dimensional Representation for Topologically Varying Neural Radiance Fields
Jun 24, 2021
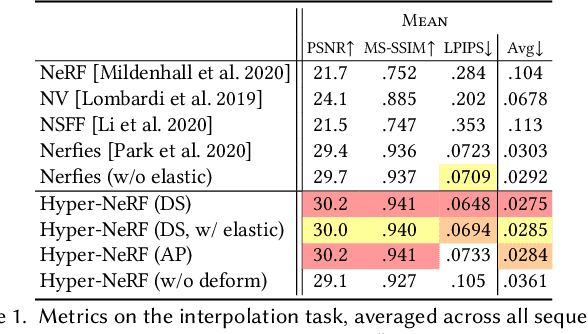
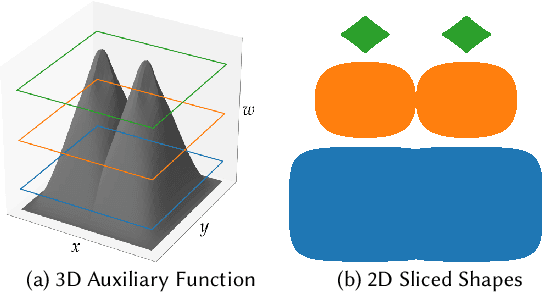
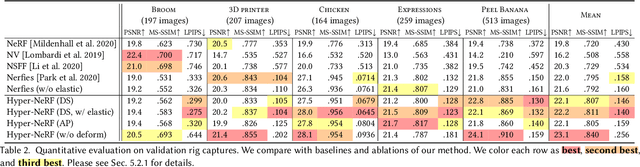
Neural Radiance Fields (NeRF) are able to reconstruct scenes with unprecedented fidelity, and various recent works have extended NeRF to handle dynamic scenes. A common approach to reconstruct such non-rigid scenes is through the use of a learned deformation field mapping from coordinates in each input image into a canonical template coordinate space. However, these deformation-based approaches struggle to model changes in topology, as topological changes require a discontinuity in the deformation field, but these deformation fields are necessarily continuous. We address this limitation by lifting NeRFs into a higher dimensional space, and by representing the 5D radiance field corresponding to each individual input image as a slice through this "hyper-space". Our method is inspired by level set methods, which model the evolution of surfaces as slices through a higher dimensional surface. We evaluate our method on two tasks: (i) interpolating smoothly between "moments", i.e., configurations of the scene, seen in the input images while maintaining visual plausibility, and (ii) novel-view synthesis at fixed moments. We show that our method, which we dub HyperNeRF, outperforms existing methods on both tasks by significant margins. Compared to Nerfies, HyperNeRF reduces average error rates by 8.6% for interpolation and 8.8% for novel-view synthesis, as measured by LPIPS.
Deformable Neural Radiance Fields
Nov 26, 2020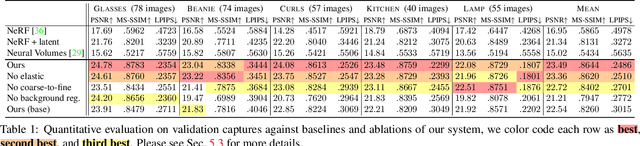


We present the first method capable of photorealistically reconstructing a non-rigidly deforming scene using photos/videos captured casually from mobile phones. Our approach -- D-NeRF -- augments neural radiance fields (NeRF) by optimizing an additional continuous volumetric deformation field that warps each observed point into a canonical 5D NeRF. We observe that these NeRF-like deformation fields are prone to local minima, and propose a coarse-to-fine optimization method for coordinate-based models that allows for more robust optimization. By adapting principles from geometry processing and physical simulation to NeRF-like models, we propose an elastic regularization of the deformation field that further improves robustness. We show that D-NeRF can turn casually captured selfie photos/videos into deformable NeRF models that allow for photorealistic renderings of the subject from arbitrary viewpoints, which we dub "nerfies." We evaluate our method by collecting data using a rig with two mobile phones that take time-synchronized photos, yielding train/validation images of the same pose at different viewpoints. We show that our method faithfully reconstructs non-rigidly deforming scenes and reproduces unseen views with high fidelity.
Real-time Burst Photo Selection Using a Light-Head Adversarial Network
Mar 20, 2018
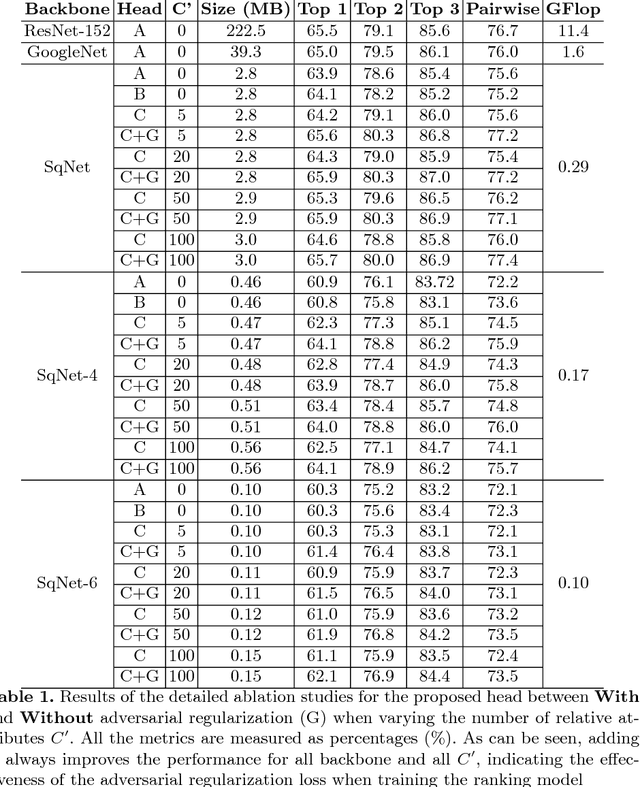
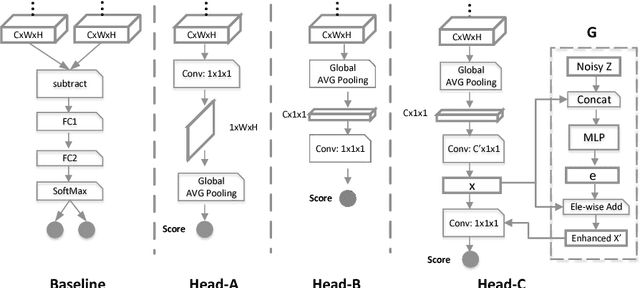
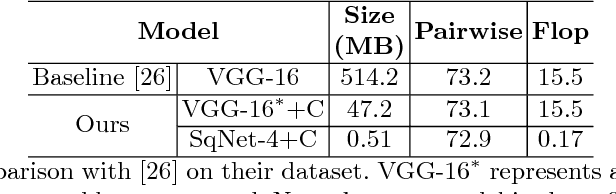
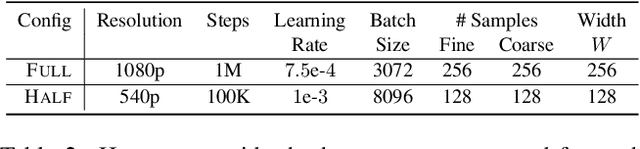
We present an automatic moment capture system that runs in real-time on mobile cameras. The system is designed to run in the viewfinder mode and capture a burst sequence of frames before and after the shutter is pressed. For each frame, the system predicts in real-time a "goodness" score, based on which the best moment in the burst can be selected immediately after the shutter is released, without any user interference. To solve the problem, we develop a highly efficient deep neural network ranking model, which implicitly learns a "latent relative attribute" space to capture subtle visual differences within a sequence of burst images. Then the overall goodness is computed as a linear aggregation of the goodnesses of all the latent attributes. The latent relative attributes and the aggregation function can be seamlessly integrated in one fully convolutional network and trained in an end-to-end fashion. To obtain a compact model which can run on mobile devices in real-time, we have explored and evaluated a wide range of network design choices, taking into account the constraints of model size, computational cost, and accuracy. Extensive studies show that the best frame predicted by our model hit users' top-1 (out of 11 on average) choice for $64.1\%$ cases and top-3 choices for $86.2\%$ cases. Moreover, the model(only 0.47M Bytes) can run in real time on mobile devices, e.g. only 13ms on iPhone 7 for one frame prediction.
Comparison of Optimization Methods in Optical Flow Estimation
May 02, 2016



Optical flow estimation is a widely known problem in computer vision introduced by Gibson, J.J(1950) to describe the visual perception of human by stimulus objects. Estimation of optical flow model can be achieved by solving for the motion vectors from region of interest in the the different timeline. In this paper, we assumed slightly uniform change of velocity between two nearby frames, and solve the optical flow problem by traditional method, Lucas-Kanade(1981). This method performs minimization of errors between template and target frame warped back onto the template. Solving minimization steps requires optimization methods which have diverse convergence rate and error. We explored first and second order optimization methods, and compare their results with Gauss-Newton method in Lucas-Kanade. We generated 105 videos with 10,500 frames by synthetic objects, and 10 videos with 1,000 frames from real world footage. Our experimental results could be used as tuning parameters for Lucas-Kanade method.