 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZipMap: Linear-Time Stateful 3D Reconstruction with Test-Time Training
Mar 04, 2026Feed-forward transformer models have driven rapid progress in 3D vision, but state-of-the-art methods such as VGGT and $π^3$ have a computational cost that scales quadratically with the number of input images, making them inefficient when applied to large image collections. Sequential-reconstruction approaches reduce this cost but sacrifice reconstruction quality. We introduce ZipMap, a stateful feed-forward model that achieves linear-time, bidirectional 3D reconstruction while matching or surpassing the accuracy of quadratic-time methods. ZipMap employs test-time training layers to zip an entire image collection into a compact hidden scene state in a single forward pass, enabling reconstruction of over 700 frames in under 10 seconds on a single H100 GPU, more than $20\times$ faster than state-of-the-art methods such as VGGT. Moreover, we demonstrate the benefits of having a stateful representation in real-time scene-state querying and its extension to sequential streaming reconstruction.
Spatiotemporally Consistent Indoor Lighting Estimation with Diffusion Priors
Aug 11, 2025
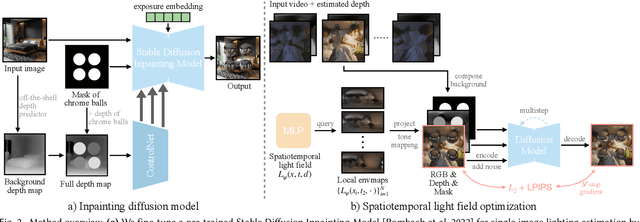


Indoor lighting estimation from a single image or video remains a challenge due to its highly ill-posed nature, especially when the lighting condition of the scene varies spatially and temporally. We propose a method that estimates from an input video a continuous light field describing the spatiotemporally varying lighting of the scene. We leverage 2D diffusion priors for optimizing such light field represented as a MLP. To enable zero-shot generalization to in-the-wild scenes, we fine-tune a pre-trained image diffusion model to predict lighting at multiple locations by jointly inpainting multiple chrome balls as light probes. We evaluate our method on indoor lighting estimation from a single image or video and show superior performance over compared baselines. Most importantly, we highlight results on spatiotemporally consistent lighting estimation from in-the-wild videos, which is rarely demonstrated in previous works.
* 11 pages. Accepted by SIGGRAPH 2025 as Conference Paper
SimVS: Simulating World Inconsistencies for Robust View Synthesis
Dec 10, 2024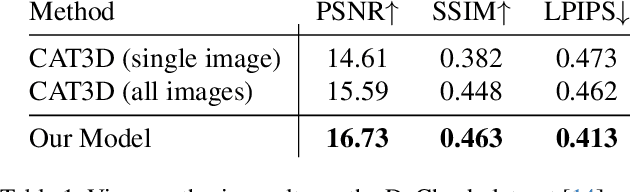



Novel-view synthesis techniques achieve impressive results for static scenes but struggle when faced with the inconsistencies inherent to casual capture settings: varying illumination, scene motion, and other unintended effects that are difficult to model explicitly. We present an approach for leveraging generative video models to simulate the inconsistencies in the world that can occur during capture. We use this process, along with existing multi-view datasets, to create synthetic data for training a multi-view harmonization network that is able to reconcile inconsistent observations into a consistent 3D scene. We demonstrate that our world-simulation strategy significantly outperforms traditional augmentation methods in handling real-world scene variations, thereby enabling highly accurate static 3D reconstructions in the presence of a variety of challenging inconsistencies. Project page: https://alextrevithick.github.io/simvs
CAT4D: Create Anything in 4D with Multi-View Video Diffusion Models
Nov 27, 2024



We present CAT4D, a method for creating 4D (dynamic 3D) scenes from monocular video. CAT4D leverages a multi-view video diffusion model trained on a diverse combination of datasets to enable novel view synthesis at any specified camera poses and timestamps. Combined with a novel sampling approach, this model can transform a single monocular video into a multi-view video, enabling robust 4D reconstruction via optimization of a deformable 3D Gaussian representation. We demonstrate competitive performance on novel view synthesis and dynamic scene reconstruction benchmarks, and highlight the creative capabilities for 4D scene generation from real or generated videos. See our project page for results and interactive demos: \url{cat-4d.github.io}.
Generative Camera Dolly: Extreme Monocular Dynamic Novel View Synthesis
May 23, 2024



Accurate reconstruction of complex dynamic scenes from just a single viewpoint continues to be a challenging task in computer vision. Current dynamic novel view synthesis methods typically require videos from many different camera viewpoints, necessitating careful recording setups, and significantly restricting their utility in the wild as well as in terms of embodied AI applications. In this paper, we propose $\textbf{GCD}$, a controllable monocular dynamic view synthesis pipeline that leverages large-scale diffusion priors to, given a video of any scene, generate a synchronous video from any other chosen perspective, conditioned on a set of relative camera pose parameters. Our model does not require depth as input, and does not explicitly model 3D scene geometry, instead performing end-to-end video-to-video translation in order to achieve its goal efficiently. Despite being trained on synthetic multi-view video data only, zero-shot real-world generalization experiments show promising results in multiple domains, including robotics, object permanence, and driving environments. We believe our framework can potentially unlock powerful applications in rich dynamic scene understanding, perception for robotics, and interactive 3D video viewing experiences for virtual reality.
PhysDreamer: Physics-Based Interaction with 3D Objects via Video Generation
Apr 19, 2024Realistic object interactions are crucial for creating immersive virtual experiences, yet synthesizing realistic 3D object dynamics in response to novel interactions remains a significant challenge. Unlike unconditional or text-conditioned dynamics generation, action-conditioned dynamics requires perceiving the physical material properties of objects and grounding the 3D motion prediction on these properties, such as object stiffness. However, estimating physical material properties is an open problem due to the lack of material ground-truth data, as measuring these properties for real objects is highly difficult. We present PhysDreamer, a physics-based approach that endows static 3D objects with interactive dynamics by leveraging the object dynamics priors learned by video generation models. By distilling these priors, PhysDreamer enables the synthesis of realistic object responses to novel interactions, such as external forces or agent manipulations. We demonstrate our approach on diverse examples of elastic objects and evaluate the realism of the synthesized interactions through a user study. PhysDreamer takes a step towards more engaging and realistic virtual experiences by enabling static 3D objects to dynamically respond to interactive stimuli in a physically plausible manner. See our project page at https://physdreamer.github.io/.
ReconFusion: 3D Reconstruction with Diffusion Priors
Dec 05, 20233D reconstruction methods such as Neural Radiance Fields (NeRFs) excel at rendering photorealistic novel views of complex scenes. However, recovering a high-quality NeRF typically requires tens to hundreds of input images, resulting in a time-consuming capture process. We present ReconFusion to reconstruct real-world scenes using only a few photos. Our approach leverages a diffusion prior for novel view synthesis, trained on synthetic and multiview datasets, which regularizes a NeRF-based 3D reconstruction pipeline at novel camera poses beyond those captured by the set of input images. Our method synthesizes realistic geometry and texture in underconstrained regions while preserving the appearance of observed regions. We perform an extensive evaluation across various real-world datasets, including forward-facing and 360-degree scenes, demonstrating significant performance improvements over previous few-view NeRF reconstruction approaches.
Sin3DM: Learning a Diffusion Model from a Single 3D Textured Shape
May 24, 2023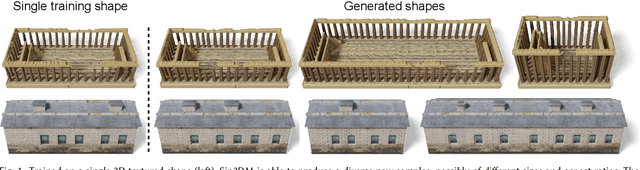
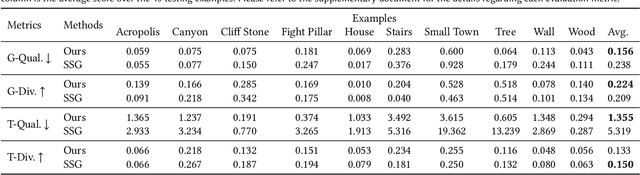
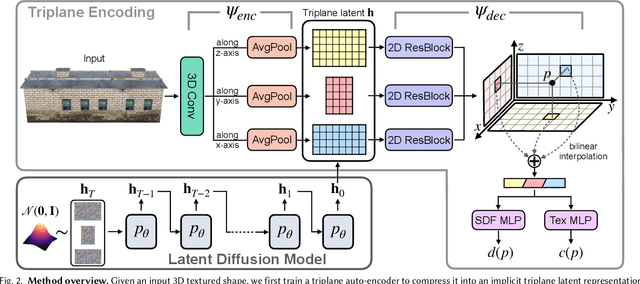
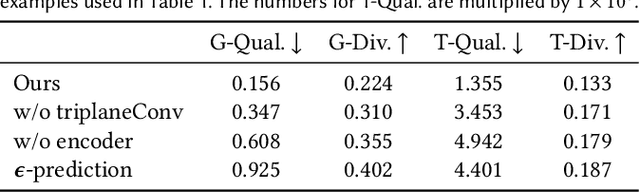
Synthesizing novel 3D models that resemble the input example has long been pursued by researchers and artists in computer graphics. In this paper, we present Sin3DM, a diffusion model that learns the internal patch distribution from a single 3D textured shape and generates high-quality variations with fine geometry and texture details. Training a diffusion model directly in 3D would induce large memory and computational cost. Therefore, we first compress the input into a lower-dimensional latent space and then train a diffusion model on it. Specifically, we encode the input 3D textured shape into triplane feature maps that represent the signed distance and texture fields of the input. The denoising network of our diffusion model has a limited receptive field to avoid overfitting, and uses triplane-aware 2D convolution blocks to improve the result quality. Aside from randomly generating new samples, our model also facilitates applications such as retargeting, outpainting and local editing. Through extensive qualitative and quantitative evaluation, we show that our model can generate 3D shapes of various types with better quality than prior methods.
Zero-1-to-3: Zero-shot One Image to 3D Object
Mar 20, 2023



We introduce Zero-1-to-3, a framework for changing the camera viewpoint of an object given just a single RGB image. To perform novel view synthesis in this under-constrained setting, we capitalize on the geometric priors that large-scale diffusion models learn about natural images. Our conditional diffusion model uses a synthetic dataset to learn controls of the relative camera viewpoint, which allow new images to be generated of the same object under a specified camera transformation. Even though it is trained on a synthetic dataset, our model retains a strong zero-shot generalization ability to out-of-distribution datasets as well as in-the-wild images, including impressionist paintings. Our viewpoint-conditioned diffusion approach can further be used for the task of 3D reconstruction from a single image. Qualitative and quantitative experiments show that our method significantly outperforms state-of-the-art single-view 3D reconstruction and novel view synthesis models by leveraging Internet-scale pre-training.
Implicit Neural Spatial Representations for Time-dependent PDEs
Sep 30, 2022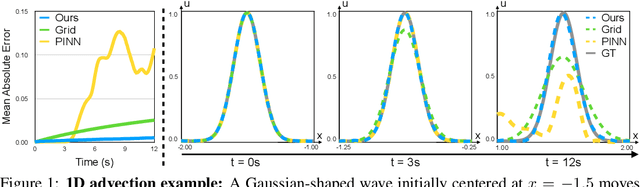

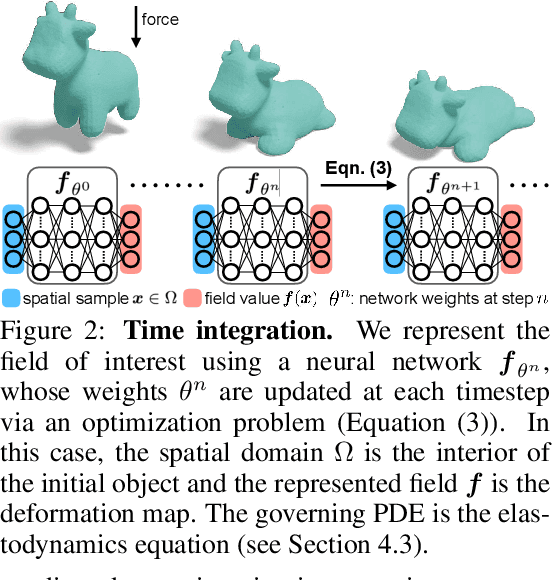

Numerically solving partial differential equations (PDEs) often entails spatial and temporal discretizations. Traditional methods (e.g., finite difference, finite element, smoothed-particle hydrodynamics) frequently adopt explicit spatial discretizations, such as grids, meshes, and point clouds, where each degree-of-freedom corresponds to a location in space. While these explicit spatial correspondences are intuitive to model and understand, these representations are not necessarily optimal for accuracy, memory-usage, or adaptivity. In this work, we explore implicit neural representation as an alternative spatial discretization, where spatial information is implicitly stored in the neural network weights. With implicit neural spatial representation, PDE-constrained time-stepping translates into updating neural network weights, which naturally integrates with commonly adopted optimization time integrators. We validate our approach on a variety of classic PDEs with examples involving large elastic deformations, turbulent fluids, and multiscale phenomena. While slower to compute than traditional representations, our approach exhibits higher accuracy, lower memory consumption, and dynamically adaptive allocation of degrees of freedom without complex remeshing.