 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSin3DM: Learning a Diffusion Model from a Single 3D Textured Shape
Paper and Code
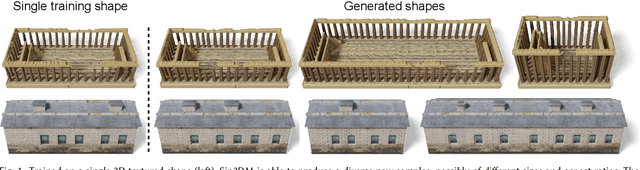
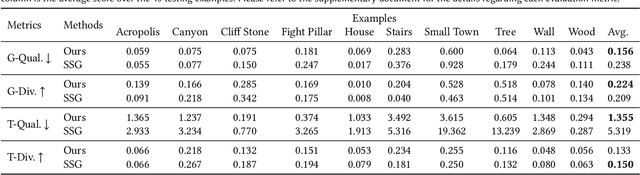
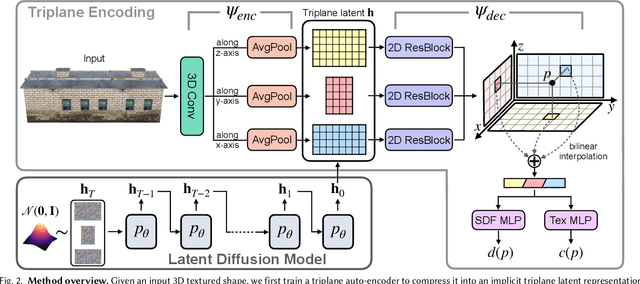
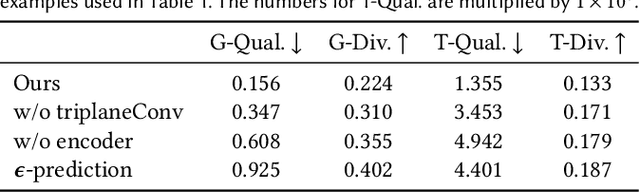
Synthesizing novel 3D models that resemble the input example has long been pursued by researchers and artists in computer graphics. In this paper, we present Sin3DM, a diffusion model that learns the internal patch distribution from a single 3D textured shape and generates high-quality variations with fine geometry and texture details. Training a diffusion model directly in 3D would induce large memory and computational cost. Therefore, we first compress the input into a lower-dimensional latent space and then train a diffusion model on it. Specifically, we encode the input 3D textured shape into triplane feature maps that represent the signed distance and texture fields of the input. The denoising network of our diffusion model has a limited receptive field to avoid overfitting, and uses triplane-aware 2D convolution blocks to improve the result quality. Aside from randomly generating new samples, our model also facilitates applications such as retargeting, outpainting and local editing. Through extensive qualitative and quantitative evaluation, we show that our model can generate 3D shapes of various types with better quality than prior methods.