 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAgger: Backwards Aggregation for Mitigating Drift in Autoregressive Video Diffusion Models
Dec 12, 2025



Autoregressive video models are promising for world modeling via next-frame prediction, but they suffer from exposure bias: a mismatch between training on clean contexts and inference on self-generated frames, causing errors to compound and quality to drift over time. We introduce Backwards Aggregation (BAgger), a self-supervised scheme that constructs corrective trajectories from the model's own rollouts, teaching it to recover from its mistakes. Unlike prior approaches that rely on few-step distillation and distribution-matching losses, which can hurt quality and diversity, BAgger trains with standard score or flow matching objectives, avoiding large teachers and long-chain backpropagation through time. We instantiate BAgger on causal diffusion transformers and evaluate on text-to-video, video extension, and multi-prompt generation, observing more stable long-horizon motion and better visual consistency with reduced drift.
Video World Models with Long-term Spatial Memory
Jun 05, 2025



Emerging world models autoregressively generate video frames in response to actions, such as camera movements and text prompts, among other control signals. Due to limited temporal context window sizes, these models often struggle to maintain scene consistency during revisits, leading to severe forgetting of previously generated environments. Inspired by the mechanisms of human memory, we introduce a novel framework to enhancing long-term consistency of video world models through a geometry-grounded long-term spatial memory. Our framework includes mechanisms to store and retrieve information from the long-term spatial memory and we curate custom datasets to train and evaluate world models with explicitly stored 3D memory mechanisms. Our evaluations show improved quality, consistency, and context length compared to relevant baselines, paving the way towards long-term consistent world generation.
Long-Context State-Space Video World Models
May 26, 2025Video diffusion models have recently shown promise for world modeling through autoregressive frame prediction conditioned on actions. However, they struggle to maintain long-term memory due to the high computational cost associated with processing extended sequences in attention layers. To overcome this limitation, we propose a novel architecture leveraging state-space models (SSMs) to extend temporal memory without compromising computational efficiency. Unlike previous approaches that retrofit SSMs for non-causal vision tasks, our method fully exploits the inherent advantages of SSMs in causal sequence modeling. Central to our design is a block-wise SSM scanning scheme, which strategically trades off spatial consistency for extended temporal memory, combined with dense local attention to ensure coherence between consecutive frames. We evaluate the long-term memory capabilities of our model through spatial retrieval and reasoning tasks over extended horizons. Experiments on Memory Maze and Minecraft datasets demonstrate that our approach surpasses baselines in preserving long-range memory, while maintaining practical inference speeds suitable for interactive applications.
FiVA: Fine-grained Visual Attribute Dataset for Text-to-Image Diffusion Models
Dec 10, 2024



Recent advances in text-to-image generation have enabled the creation of high-quality images with diverse applications. However, accurately describing desired visual attributes can be challenging, especially for non-experts in art and photography. An intuitive solution involves adopting favorable attributes from the source images. Current methods attempt to distill identity and style from source images. However, "style" is a broad concept that includes texture, color, and artistic elements, but does not cover other important attributes such as lighting and dynamics. Additionally, a simplified "style" adaptation prevents combining multiple attributes from different sources into one generated image. In this work, we formulate a more effective approach to decompose the aesthetics of a picture into specific visual attributes, allowing users to apply characteristics such as lighting, texture, and dynamics from different images. To achieve this goal, we constructed the first fine-grained visual attributes dataset (FiVA) to the best of our knowledge. This FiVA dataset features a well-organized taxonomy for visual attributes and includes around 1 M high-quality generated images with visual attribute annotations. Leveraging this dataset, we propose a fine-grained visual attribute adaptation framework (FiVA-Adapter), which decouples and adapts visual attributes from one or more source images into a generated one. This approach enhances user-friendly customization, allowing users to selectively apply desired attributes to create images that meet their unique preferences and specific content requirements.
Flying with Photons: Rendering Novel Views of Propagating Light
Apr 10, 2024We present an imaging and neural rendering technique that seeks to synthesize videos of light propagating through a scene from novel, moving camera viewpoints. Our approach relies on a new ultrafast imaging setup to capture a first-of-its kind, multi-viewpoint video dataset with picosecond-level temporal resolution. Combined with this dataset, we introduce an efficient neural volume rendering framework based on the transient field. This field is defined as a mapping from a 3D point and 2D direction to a high-dimensional, discrete-time signal that represents time-varying radiance at ultrafast timescales. Rendering with transient fields naturally accounts for effects due to the finite speed of light, including viewpoint-dependent appearance changes caused by light propagation delays to the camera. We render a range of complex effects, including scattering, specular reflection, refraction, and diffraction. Additionally, we demonstrate removing viewpoint-dependent propagation delays using a time warping procedure, rendering of relativistic effects, and video synthesis of direct and global components of light transport.
Orthogonal Adaptation for Modular Customization of Diffusion Models
Dec 05, 2023



Customization techniques for text-to-image models have paved the way for a wide range of previously unattainable applications, enabling the generation of specific concepts across diverse contexts and styles. While existing methods facilitate high-fidelity customization for individual concepts or a limited, pre-defined set of them, they fall short of achieving scalability, where a single model can seamlessly render countless concepts. In this paper, we address a new problem called Modular Customization, with the goal of efficiently merging customized models that were fine-tuned independently for individual concepts. This allows the merged model to jointly synthesize concepts in one image without compromising fidelity or incurring any additional computational costs. To address this problem, we introduce Orthogonal Adaptation, a method designed to encourage the customized models, which do not have access to each other during fine-tuning, to have orthogonal residual weights. This ensures that during inference time, the customized models can be summed with minimal interference. Our proposed method is both simple and versatile, applicable to nearly all optimizable weights in the model architecture. Through an extensive set of quantitative and qualitative evaluations, our method consistently outperforms relevant baselines in terms of efficiency and identity preservation, demonstrating a significant leap toward scalable customization of diffusion models.
Gaussian Shell Maps for Efficient 3D Human Generation
Nov 29, 2023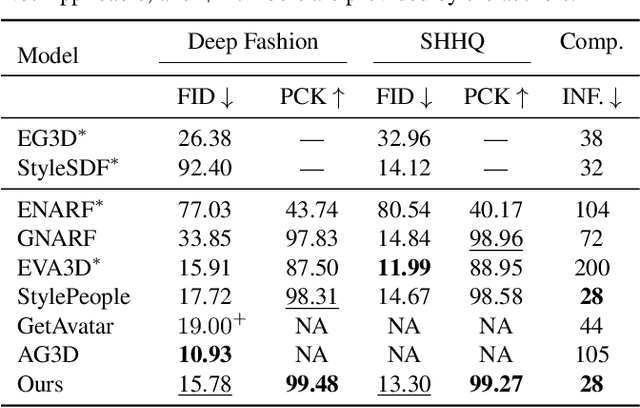



Efficient generation of 3D digital humans is important in several industries, including virtual reality, social media, and cinematic production. 3D generative adversarial networks (GANs) have demonstrated state-of-the-art (SOTA) quality and diversity for generated assets. Current 3D GAN architectures, however, typically rely on volume representations, which are slow to render, thereby hampering the GAN training and requiring multi-view-inconsistent 2D upsamplers. Here, we introduce Gaussian Shell Maps (GSMs) as a framework that connects SOTA generator network architectures with emerging 3D Gaussian rendering primitives using an articulable multi shell--based scaffold. In this setting, a CNN generates a 3D texture stack with features that are mapped to the shells. The latter represent inflated and deflated versions of a template surface of a digital human in a canonical body pose. Instead of rasterizing the shells directly, we sample 3D Gaussians on the shells whose attributes are encoded in the texture features. These Gaussians are efficiently and differentiably rendered. The ability to articulate the shells is important during GAN training and, at inference time, to deform a body into arbitrary user-defined poses. Our efficient rendering scheme bypasses the need for view-inconsistent upsamplers and achieves high-quality multi-view consistent renderings at a native resolution of $512 \times 512$ pixels. We demonstrate that GSMs successfully generate 3D humans when trained on single-view datasets, including SHHQ and DeepFashion.
State of the Art on Diffusion Models for Visual Computing
Oct 11, 2023The field of visual computing is rapidly advancing due to the emergence of generative artificial intelligence (AI), which unlocks unprecedented capabilities for the generation, editing, and reconstruction of images, videos, and 3D scenes. In these domains, diffusion models are the generative AI architecture of choice. Within the last year alone, the literature on diffusion-based tools and applications has seen exponential growth and relevant papers are published across the computer graphics, computer vision, and AI communities with new works appearing daily on arXiv. This rapid growth of the field makes it difficult to keep up with all recent developments. The goal of this state-of-the-art report (STAR) is to introduce the basic mathematical concepts of diffusion models, implementation details and design choices of the popular Stable Diffusion model, as well as overview important aspects of these generative AI tools, including personalization, conditioning, inversion, among others. Moreover, we give a comprehensive overview of the rapidly growing literature on diffusion-based generation and editing, categorized by the type of generated medium, including 2D images, videos, 3D objects, locomotion, and 4D scenes. Finally, we discuss available datasets, metrics, open challenges, and social implications. This STAR provides an intuitive starting point to explore this exciting topic for researchers, artists, and practitioners alike.
Instant Continual Learning of Neural Radiance Fields
Sep 06, 2023Neural radiance fields (NeRFs) have emerged as an effective method for novel-view synthesis and 3D scene reconstruction. However, conventional training methods require access to all training views during scene optimization. This assumption may be prohibitive in continual learning scenarios, where new data is acquired in a sequential manner and a continuous update of the NeRF is desired, as in automotive or remote sensing applications. When naively trained in such a continual setting, traditional scene representation frameworks suffer from catastrophic forgetting, where previously learned knowledge is corrupted after training on new data. Prior works in alleviating forgetting with NeRFs suffer from low reconstruction quality and high latency, making them impractical for real-world application. We propose a continual learning framework for training NeRFs that leverages replay-based methods combined with a hybrid explicit--implicit scene representation. Our method outperforms previous methods in reconstruction quality when trained in a continual setting, while having the additional benefit of being an order of magnitude faster.
Compositional 3D Scene Generation using Locally Conditioned Diffusion
Mar 23, 2023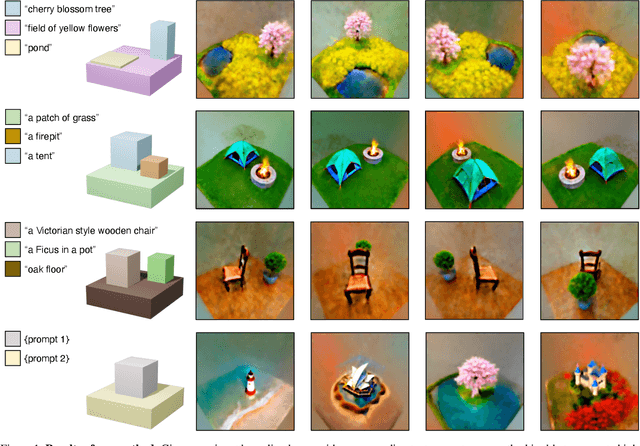
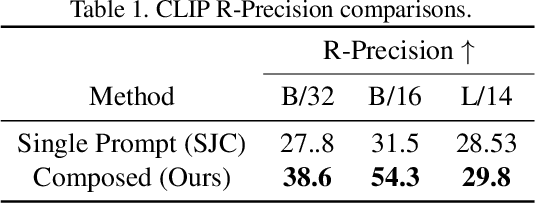
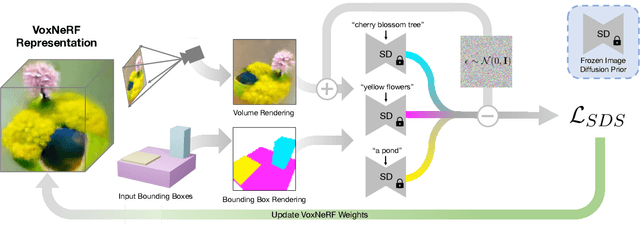
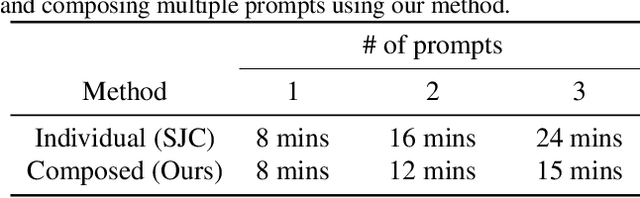
Designing complex 3D scenes has been a tedious, manual process requiring domain expertise. Emerging text-to-3D generative models show great promise for making this task more intuitive, but existing approaches are limited to object-level generation. We introduce \textbf{locally conditioned diffusion} as an approach to compositional scene diffusion, providing control over semantic parts using text prompts and bounding boxes while ensuring seamless transitions between these parts. We demonstrate a score distillation sampling--based text-to-3D synthesis pipeline that enables compositional 3D scene generation at a higher fidelity than relevant baselines.