 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSS4D: Native 4D Generative Model via Structured Spacetime Latents
Dec 16, 2025
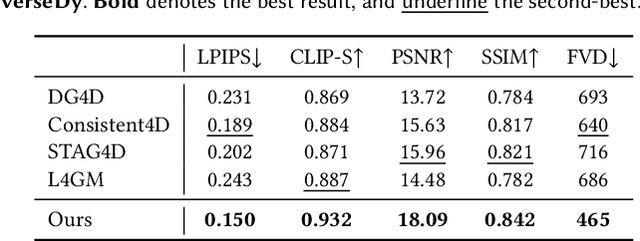
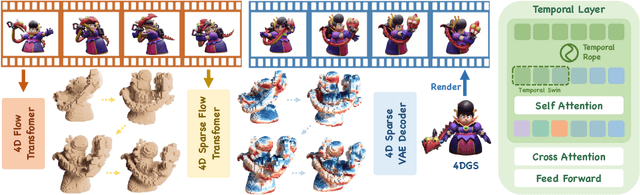
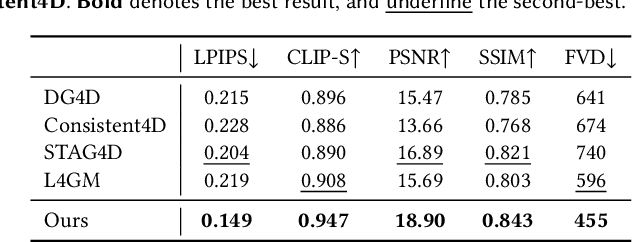
We present SS4D, a native 4D generative model that synthesizes dynamic 3D objects directly from monocular video. Unlike prior approaches that construct 4D representations by optimizing over 3D or video generative models, we train a generator directly on 4D data, achieving high fidelity, temporal coherence, and structural consistency. At the core of our method is a compressed set of structured spacetime latents. Specifically, (1) To address the scarcity of 4D training data, we build on a pre-trained single-image-to-3D model, preserving strong spatial consistency. (2) Temporal consistency is enforced by introducing dedicated temporal layers that reason across frames. (3) To support efficient training and inference over long video sequences, we compress the latent sequence along the temporal axis using factorized 4D convolutions and temporal downsampling blocks. In addition, we employ a carefully designed training strategy to enhance robustness against occlusion
* ToG(Siggraph Asia 2025)
GenDoP: Auto-regressive Camera Trajectory Generation as a Director of Photography
Apr 10, 2025Camera trajectory design plays a crucial role in video production, serving as a fundamental tool for conveying directorial intent and enhancing visual storytelling. In cinematography, Directors of Photography meticulously craft camera movements to achieve expressive and intentional framing. However, existing methods for camera trajectory generation remain limited: Traditional approaches rely on geometric optimization or handcrafted procedural systems, while recent learning-based methods often inherit structural biases or lack textual alignment, constraining creative synthesis. In this work, we introduce an auto-regressive model inspired by the expertise of Directors of Photography to generate artistic and expressive camera trajectories. We first introduce DataDoP, a large-scale multi-modal dataset containing 29K real-world shots with free-moving camera trajectories, depth maps, and detailed captions in specific movements, interaction with the scene, and directorial intent. Thanks to the comprehensive and diverse database, we further train an auto-regressive, decoder-only Transformer for high-quality, context-aware camera movement generation based on text guidance and RGBD inputs, named GenDoP. Extensive experiments demonstrate that compared to existing methods, GenDoP offers better controllability, finer-grained trajectory adjustments, and higher motion stability. We believe our approach establishes a new standard for learning-based cinematography, paving the way for future advancements in camera control and filmmaking. Our project website: https://kszpxxzmc.github.io/GenDoP/.
3DGen-Bench: Comprehensive Benchmark Suite for 3D Generative Models
Mar 27, 2025

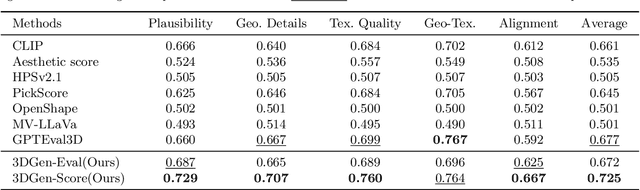
3D generation is experiencing rapid advancements, while the development of 3D evaluation has not kept pace. How to keep automatic evaluation equitably aligned with human perception has become a well-recognized challenge. Recent advances in the field of language and image generation have explored human preferences and showcased respectable fitting ability. However, the 3D domain still lacks such a comprehensive preference dataset over generative models. To mitigate this absence, we develop 3DGen-Arena, an integrated platform in a battle manner. Then, we carefully design diverse text and image prompts and leverage the arena platform to gather human preferences from both public users and expert annotators, resulting in a large-scale multi-dimension human preference dataset 3DGen-Bench. Using this dataset, we further train a CLIP-based scoring model, 3DGen-Score, and a MLLM-based automatic evaluator, 3DGen-Eval. These two models innovatively unify the quality evaluation of text-to-3D and image-to-3D generation, and jointly form our automated evaluation system with their respective strengths. Extensive experiments demonstrate the efficacy of our scoring model in predicting human preferences, exhibiting a superior correlation with human ranks compared to existing metrics. We believe that our 3DGen-Bench dataset and automated evaluation system will foster a more equitable evaluation in the field of 3D generation, further promoting the development of 3D generative models and their downstream applications.
IDArb: Intrinsic Decomposition for Arbitrary Number of Input Views and Illuminations
Dec 16, 2024



Capturing geometric and material information from images remains a fundamental challenge in computer vision and graphics. Traditional optimization-based methods often require hours of computational time to reconstruct geometry, material properties, and environmental lighting from dense multi-view inputs, while still struggling with inherent ambiguities between lighting and material. On the other hand, learning-based approaches leverage rich material priors from existing 3D object datasets but face challenges with maintaining multi-view consistency. In this paper, we introduce IDArb, a diffusion-based model designed to perform intrinsic decomposition on an arbitrary number of images under varying illuminations. Our method achieves accurate and multi-view consistent estimation on surface normals and material properties. This is made possible through a novel cross-view, cross-domain attention module and an illumination-augmented, view-adaptive training strategy. Additionally, we introduce ARB-Objaverse, a new dataset that provides large-scale multi-view intrinsic data and renderings under diverse lighting conditions, supporting robust training. Extensive experiments demonstrate that IDArb outperforms state-of-the-art methods both qualitatively and quantitatively. Moreover, our approach facilitates a range of downstream tasks, including single-image relighting, photometric stereo, and 3D reconstruction, highlighting its broad applications in realistic 3D content creation.
FiVA: Fine-grained Visual Attribute Dataset for Text-to-Image Diffusion Models
Dec 10, 2024



Recent advances in text-to-image generation have enabled the creation of high-quality images with diverse applications. However, accurately describing desired visual attributes can be challenging, especially for non-experts in art and photography. An intuitive solution involves adopting favorable attributes from the source images. Current methods attempt to distill identity and style from source images. However, "style" is a broad concept that includes texture, color, and artistic elements, but does not cover other important attributes such as lighting and dynamics. Additionally, a simplified "style" adaptation prevents combining multiple attributes from different sources into one generated image. In this work, we formulate a more effective approach to decompose the aesthetics of a picture into specific visual attributes, allowing users to apply characteristics such as lighting, texture, and dynamics from different images. To achieve this goal, we constructed the first fine-grained visual attributes dataset (FiVA) to the best of our knowledge. This FiVA dataset features a well-organized taxonomy for visual attributes and includes around 1 M high-quality generated images with visual attribute annotations. Leveraging this dataset, we propose a fine-grained visual attribute adaptation framework (FiVA-Adapter), which decouples and adapts visual attributes from one or more source images into a generated one. This approach enhances user-friendly customization, allowing users to selectively apply desired attributes to create images that meet their unique preferences and specific content requirements.
Omni6D: Large-Vocabulary 3D Object Dataset for Category-Level 6D Object Pose Estimation
Sep 26, 2024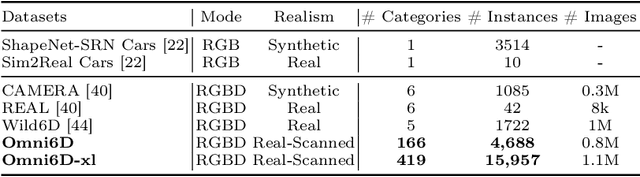
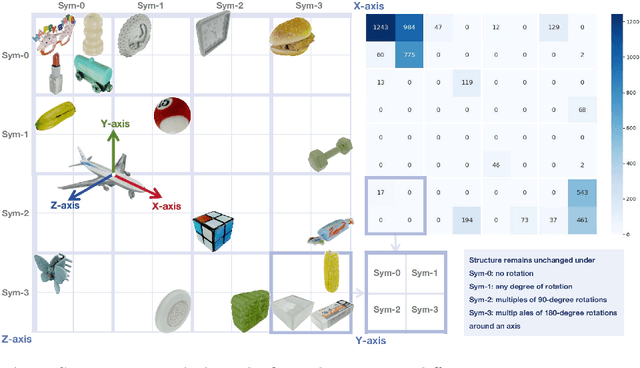


6D object pose estimation aims at determining an object's translation, rotation, and scale, typically from a single RGBD image. Recent advancements have expanded this estimation from instance-level to category-level, allowing models to generalize across unseen instances within the same category. However, this generalization is limited by the narrow range of categories covered by existing datasets, such as NOCS, which also tend to overlook common real-world challenges like occlusion. To tackle these challenges, we introduce Omni6D, a comprehensive RGBD dataset featuring a wide range of categories and varied backgrounds, elevating the task to a more realistic context. 1) The dataset comprises an extensive spectrum of 166 categories, 4688 instances adjusted to the canonical pose, and over 0.8 million captures, significantly broadening the scope for evaluation. 2) We introduce a symmetry-aware metric and conduct systematic benchmarks of existing algorithms on Omni6D, offering a thorough exploration of new challenges and insights. 3) Additionally, we propose an effective fine-tuning approach that adapts models from previous datasets to our extensive vocabulary setting. We believe this initiative will pave the way for new insights and substantial progress in both the industrial and academic fields, pushing forward the boundaries of general 6D pose estimation.
LayerPano3D: Layered 3D Panorama for Hyper-Immersive Scene Generation
Aug 23, 2024



3D immersive scene generation is a challenging yet critical task in computer vision and graphics. A desired virtual 3D scene should 1) exhibit omnidirectional view consistency, and 2) allow for free exploration in complex scene hierarchies. Existing methods either rely on successive scene expansion via inpainting or employ panorama representation to represent large FOV scene environments. However, the generated scene suffers from semantic drift during expansion and is unable to handle occlusion among scene hierarchies. To tackle these challenges, we introduce LayerPano3D, a novel framework for full-view, explorable panoramic 3D scene generation from a single text prompt. Our key insight is to decompose a reference 2D panorama into multiple layers at different depth levels, where each layer reveals the unseen space from the reference views via diffusion prior. LayerPano3D comprises multiple dedicated designs: 1) we introduce a novel text-guided anchor view synthesis pipeline for high-quality, consistent panorama generation. 2) We pioneer the Layered 3D Panorama as underlying representation to manage complex scene hierarchies and lift it into 3D Gaussians to splat detailed 360-degree omnidirectional scenes with unconstrained viewing paths. Extensive experiments demonstrate that our framework generates state-of-the-art 3D panoramic scene in both full view consistency and immersive exploratory experience. We believe that LayerPano3D holds promise for advancing 3D panoramic scene creation with numerous applications.
Tailor3D: Customized 3D Assets Editing and Generation with Dual-Side Images
Jul 08, 2024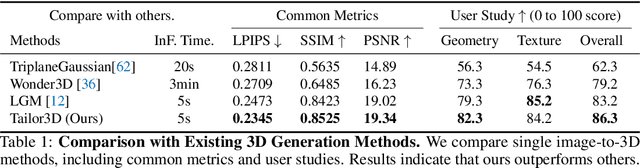
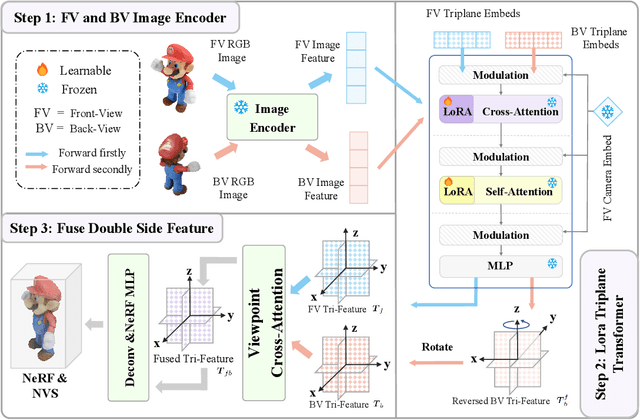
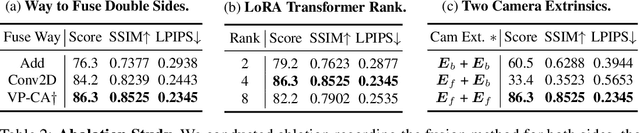
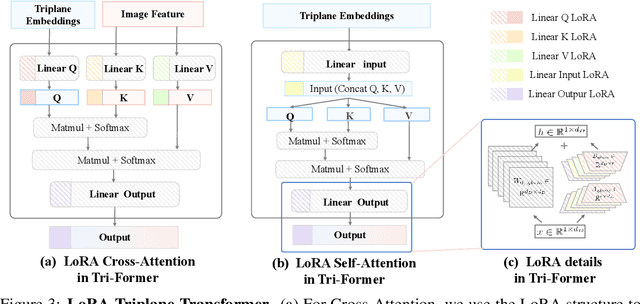
Recent advances in 3D AIGC have shown promise in directly creating 3D objects from text and images, offering significant cost savings in animation and product design. However, detailed edit and customization of 3D assets remains a long-standing challenge. Specifically, 3D Generation methods lack the ability to follow finely detailed instructions as precisely as their 2D image creation counterparts. Imagine you can get a toy through 3D AIGC but with undesired accessories and dressing. To tackle this challenge, we propose a novel pipeline called Tailor3D, which swiftly creates customized 3D assets from editable dual-side images. We aim to emulate a tailor's ability to locally change objects or perform overall style transfer. Unlike creating 3D assets from multiple views, using dual-side images eliminates conflicts on overlapping areas that occur when editing individual views. Specifically, it begins by editing the front view, then generates the back view of the object through multi-view diffusion. Afterward, it proceeds to edit the back views. Finally, a Dual-sided LRM is proposed to seamlessly stitch together the front and back 3D features, akin to a tailor sewing together the front and back of a garment. The Dual-sided LRM rectifies imperfect consistencies between the front and back views, enhancing editing capabilities and reducing memory burdens while seamlessly integrating them into a unified 3D representation with the LoRA Triplane Transformer. Experimental results demonstrate Tailor3D's effectiveness across various 3D generation and editing tasks, including 3D generative fill and style transfer. It provides a user-friendly, efficient solution for editing 3D assets, with each editing step taking only seconds to complete.
Gemini vs GPT-4V: A Preliminary Comparison and Combination of Vision-Language Models Through Qualitative Cases
Dec 22, 2023The rapidly evolving sector of Multi-modal Large Language Models (MLLMs) is at the forefront of integrating linguistic and visual processing in artificial intelligence. This paper presents an in-depth comparative study of two pioneering models: Google's Gemini and OpenAI's GPT-4V(ision). Our study involves a multi-faceted evaluation of both models across key dimensions such as Vision-Language Capability, Interaction with Humans, Temporal Understanding, and assessments in both Intelligence and Emotional Quotients. The core of our analysis delves into the distinct visual comprehension abilities of each model. We conducted a series of structured experiments to evaluate their performance in various industrial application scenarios, offering a comprehensive perspective on their practical utility. We not only involve direct performance comparisons but also include adjustments in prompts and scenarios to ensure a balanced and fair analysis. Our findings illuminate the unique strengths and niches of both models. GPT-4V distinguishes itself with its precision and succinctness in responses, while Gemini excels in providing detailed, expansive answers accompanied by relevant imagery and links. These understandings not only shed light on the comparative merits of Gemini and GPT-4V but also underscore the evolving landscape of multimodal foundation models, paving the way for future advancements in this area. After the comparison, we attempted to achieve better results by combining the two models. Finally, We would like to express our profound gratitude to the teams behind GPT-4V and Gemini for their pioneering contributions to the field. Our acknowledgments are also extended to the comprehensive qualitative analysis presented in 'Dawn' by Yang et al. This work, with its extensive collection of image samples, prompts, and GPT-4V-related results, provided a foundational basis for our analysis.