 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Elicitation of Language Models
Jun 11, 2025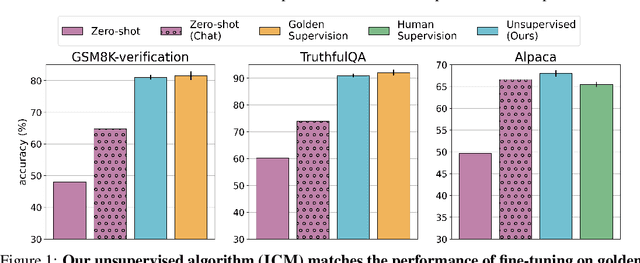

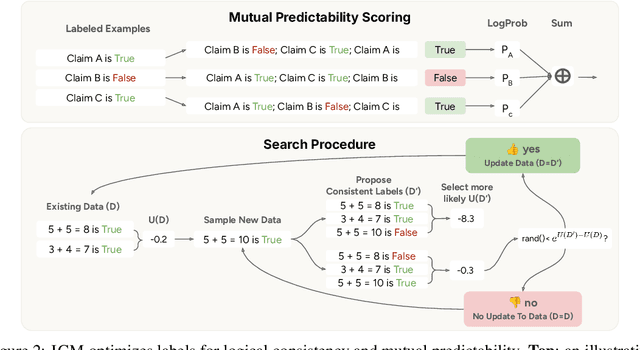

To steer pretrained language models for downstream tasks, today's post-training paradigm relies on humans to specify desired behaviors. However, for models with superhuman capabilities, it is difficult or impossible to get high-quality human supervision. To address this challenge, we introduce a new unsupervised algorithm, Internal Coherence Maximization (ICM), to fine-tune pretrained language models on their own generated labels, \emph{without external supervision}. On GSM8k-verification, TruthfulQA, and Alpaca reward modeling tasks, our method matches the performance of training on golden supervision and outperforms training on crowdsourced human supervision. On tasks where LMs' capabilities are strongly superhuman, our method can elicit those capabilities significantly better than training on human labels. Finally, we show that our method can improve the training of frontier LMs: we use our method to train an unsupervised reward model and use reinforcement learning to train a Claude 3.5 Haiku-based assistant. Both the reward model and the assistant outperform their human-supervised counterparts.
Scaling Laws for Precision
Nov 07, 2024Low precision training and inference affect both the quality and cost of language models, but current scaling laws do not account for this. In this work, we devise "precision-aware" scaling laws for both training and inference. We propose that training in lower precision reduces the model's "effective parameter count," allowing us to predict the additional loss incurred from training in low precision and post-train quantization. For inference, we find that the degradation introduced by post-training quantization increases as models are trained on more data, eventually making additional pretraining data actively harmful. For training, our scaling laws allow us to predict the loss of a model with different parts in different precisions, and suggest that training larger models in lower precision may be compute optimal. We unify the scaling laws for post and pretraining quantization to arrive at a single functional form that predicts degradation from training and inference in varied precisions. We fit on over 465 pretraining runs and validate our predictions on model sizes up to 1.7B parameters trained on up to 26B tokens.
Critique-out-Loud Reward Models
Aug 21, 2024Traditionally, reward models used for reinforcement learning from human feedback (RLHF) are trained to directly predict preference scores without leveraging the generation capabilities of the underlying large language model (LLM). This limits the capabilities of reward models as they must reason implicitly about the quality of a response, i.e., preference modeling must be performed in a single forward pass through the model. To enable reward models to reason explicitly about the quality of a response, we introduce Critique-out-Loud (CLoud) reward models. CLoud reward models operate by first generating a natural language critique of the assistant's response that is then used to predict a scalar reward for the quality of the response. We demonstrate the success of CLoud reward models for both Llama-3-8B and 70B base models: compared to classic reward models CLoud reward models improve pairwise preference classification accuracy on RewardBench by 4.65 and 5.84 percentage points for the 8B and 70B base models respectively. Furthermore, CLoud reward models lead to a Pareto improvement for win rate on ArenaHard when used as the scoring model for Best-of-N. Finally, we explore how to exploit the dynamic inference compute capabilities of CLoud reward models by performing self-consistency decoding for reward prediction.
Perplexed by Perplexity: Perplexity-Based Data Pruning With Small Reference Models
May 30, 2024In this work, we investigate whether small language models can determine high-quality subsets of large-scale text datasets that improve the performance of larger language models. While existing work has shown that pruning based on the perplexity of a larger model can yield high-quality data, we investigate whether smaller models can be used for perplexity-based pruning and how pruning is affected by the domain composition of the data being pruned. We demonstrate that for multiple dataset compositions, perplexity-based pruning of pretraining data can \emph{significantly} improve downstream task performance: pruning based on perplexities computed with a 125 million parameter model improves the average performance on downstream tasks of a 3 billion parameter model by up to 2.04 and achieves up to a $1.45\times$ reduction in pretraining steps to reach commensurate baseline performance. Furthermore, we demonstrate that such perplexity-based data pruning also yields downstream performance gains in the over-trained and data-constrained regimes.
Hydra: Sequentially-Dependent Draft Heads for Medusa Decoding
Feb 07, 2024To combat the memory bandwidth-bound nature of autoregressive LLM inference, previous research has proposed the speculative decoding framework. To perform speculative decoding, a small draft model proposes candidate continuations of the input sequence, that are then verified in parallel by the base model. One way to specify the draft model, as used in the recent Medusa decoding framework, is as a collection of light-weight heads, called draft heads, that operate on the base model's hidden states. To date, all existing draft heads have been sequentially independent, meaning that they speculate tokens in the candidate continuation independently of any preceding tokens in the candidate continuation. In this work, we propose Hydra heads, a sequentially dependent, drop-in replacement for standard draft heads that significantly improves speculation accuracy. Decoding with Hydra heads improves throughput compared to Medusa decoding with standard draft heads. We further explore the design space of Hydra head training objectives and architectures, and propose a carefully-tuned Hydra head recipe, which we call Hydra++, that improves decoding throughput by 1.31x and 2.71x compared to Medusa decoding and autoregressive decoding, respectively. Overall, Hydra heads are a simple intervention on standard draft heads that significantly improve the end-to-end speed of draft head based speculative decoding.
Striped Attention: Faster Ring Attention for Causal Transformers
Nov 15, 2023



To help address the growing demand for ever-longer sequence lengths in transformer models, Liu et al. recently proposed Ring Attention, an exact attention algorithm capable of overcoming per-device memory bottle- necks by distributing self-attention across multiple devices. In this paper, we study the performance characteristics of Ring Attention in the important special case of causal transformer models, and identify a key workload imbal- ance due to triangular structure of causal attention computations. We propose a simple extension to Ring Attention, which we call Striped Attention to fix this imbalance. Instead of devices having contiguous subsequences, each device has a subset of tokens distributed uniformly throughout the sequence, which we demonstrate leads to more even workloads. In experiments running Striped Attention on A100 GPUs and TPUv4s, we are able to achieve up to 1.45x end-to-end throughput improvements over the original Ring Attention algorithm on causal transformer training at a sequence length of 256k. Furthermore, on 16 TPUv4 chips, we were able to achieve 1.65x speedups at sequence lengths of 786k. We release the code for our experiments as open source
Dynamic Masking Rate Schedules for MLM Pretraining
May 24, 2023Most works on transformers trained with the Masked Language Modeling (MLM) objective use the original BERT model's fixed masking rate of 15%. Our work instead dynamically schedules the masking ratio throughout training. We found that linearly decreasing the masking rate from 30% to 15% over the course of pretraining improves average GLUE accuracy by 0.46% in BERT-base, compared to a standard 15% fixed rate. Further analyses demonstrate that the gains from scheduling come from being exposed to both high and low masking rate regimes. Our results demonstrate that masking rate scheduling is a simple way to improve the quality of masked language models and achieve up to a 1.89x speedup in pretraining.
The Effect of Data Dimensionality on Neural Network Prunability
Dec 01, 2022



Practitioners prune neural networks for efficiency gains and generalization improvements, but few scrutinize the factors determining the prunability of a neural network the maximum fraction of weights that pruning can remove without compromising the model's test accuracy. In this work, we study the properties of input data that may contribute to the prunability of a neural network. For high dimensional input data such as images, text, and audio, the manifold hypothesis suggests that these high dimensional inputs approximately lie on or near a significantly lower dimensional manifold. Prior work demonstrates that the underlying low dimensional structure of the input data may affect the sample efficiency of learning. In this paper, we investigate whether the low dimensional structure of the input data affects the prunability of a neural network.
3D Neural Field Generation using Triplane Diffusion
Nov 30, 2022



Diffusion models have emerged as the state-of-the-art for image generation, among other tasks. Here, we present an efficient diffusion-based model for 3D-aware generation of neural fields. Our approach pre-processes training data, such as ShapeNet meshes, by converting them to continuous occupancy fields and factoring them into a set of axis-aligned triplane feature representations. Thus, our 3D training scenes are all represented by 2D feature planes, and we can directly train existing 2D diffusion models on these representations to generate 3D neural fields with high quality and diversity, outperforming alternative approaches to 3D-aware generation. Our approach requires essential modifications to existing triplane factorization pipelines to make the resulting features easy to learn for the diffusion model. We demonstrate state-of-the-art results on 3D generation on several object classes from ShapeNet.