 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashOptim: Optimizers for Memory Efficient Training
Feb 26, 2026Standard mixed-precision training of neural networks requires many bytes of accelerator memory for each model parameter. These bytes reflect not just the parameter itself, but also its gradient and one or more optimizer state variables. With each of these values typically requiring 4 bytes, training even a 7 billion parameter model can be impractical for researchers with less than 100GB of accelerator memory. We introduce FlashOptim, a suite of optimizations that reduces per-parameter memory by over 50% while preserving model quality and API compatibility. Our approach introduces two key techniques. First, we improve master weight splitting by finding and exploiting a tight bound on its quantization error. Second, we design companding functions that greatly reduce the error in 8-bit optimizer state quantization. Together with 16-bit gradients, these techniques reduce AdamW memory from 16 bytes to 7 bytes per parameter, or 5 bytes with gradient release. They also cut model checkpoint sizes by more than half. Experiments with FlashOptim applied to SGD, AdamW, and Lion show no measurable quality degradation on any task from a collection of standard vision and language benchmarks, including Llama-3.1-8B finetuning.
$μ$nit Scaling: Simple and Scalable FP8 LLM Training
Feb 09, 2025Large Language Model training with 8-bit floating point (FP8) formats promises significant efficiency improvements, but reduced numerical precision makes training challenging. It is currently possible to train in FP8 only if one is willing to tune various hyperparameters, reduce model scale, or accept the overhead of computing dynamic scale factors. We demonstrate simple, scalable FP8 training that requires no dynamic scaling factors or special hyperparameters, even at large model sizes. Our method, $\mu$nit Scaling ($\mu$S), also enables simple hyperparameter transfer across model widths, matched numerics across training and inference, and other desirable properties. $\mu$nit Scaling is straightforward to implement, consisting of a set of minimal interventions based on a first-principles analysis of common transformer operations. We validate our method by training models from 1B to 13B parameters, performing all hidden linear layer computations in FP8. We achieve quality equal to higher precision baselines while also training up to 33% faster.
Dynamic Masking Rate Schedules for MLM Pretraining
May 24, 2023Most works on transformers trained with the Masked Language Modeling (MLM) objective use the original BERT model's fixed masking rate of 15%. Our work instead dynamically schedules the masking ratio throughout training. We found that linearly decreasing the masking rate from 30% to 15% over the course of pretraining improves average GLUE accuracy by 0.46% in BERT-base, compared to a standard 15% fixed rate. Further analyses demonstrate that the gains from scheduling come from being exposed to both high and low masking rate regimes. Our results demonstrate that masking rate scheduling is a simple way to improve the quality of masked language models and achieve up to a 1.89x speedup in pretraining.
Compute-Efficient Deep Learning: Algorithmic Trends and Opportunities
Oct 13, 2022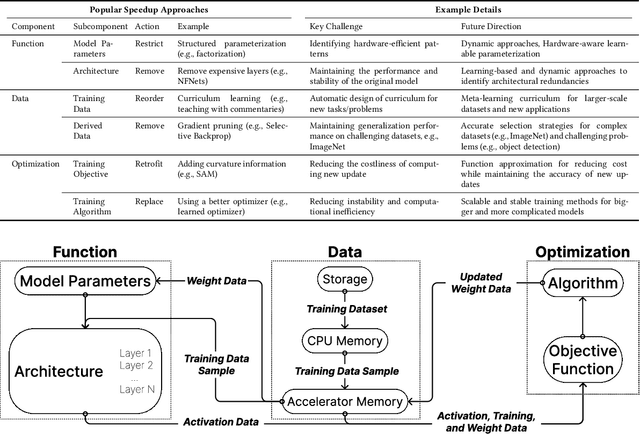
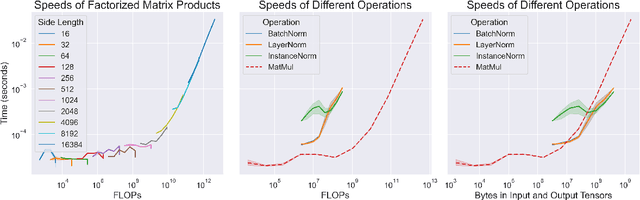

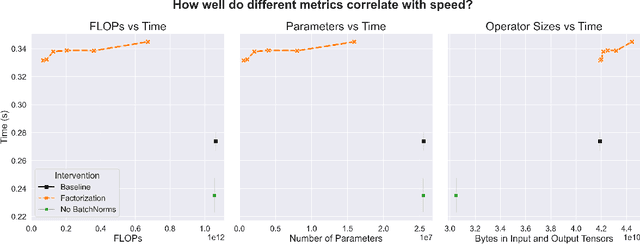
Although deep learning has made great progress in recent years, the exploding economic and environmental costs of training neural networks are becoming unsustainable. To address this problem, there has been a great deal of research on *algorithmically-efficient deep learning*, which seeks to reduce training costs not at the hardware or implementation level, but through changes in the semantics of the training program. In this paper, we present a structured and comprehensive overview of the research in this field. First, we formalize the *algorithmic speedup* problem, then we use fundamental building blocks of algorithmically efficient training to develop a taxonomy. Our taxonomy highlights commonalities of seemingly disparate methods and reveals current research gaps. Next, we present evaluation best practices to enable comprehensive, fair, and reliable comparisons of speedup techniques. To further aid research and applications, we discuss common bottlenecks in the training pipeline (illustrated via experiments) and offer taxonomic mitigation strategies for them. Finally, we highlight some unsolved research challenges and present promising future directions.
Fast Benchmarking of Accuracy vs. Training Time with Cyclic Learning Rates
Jun 02, 2022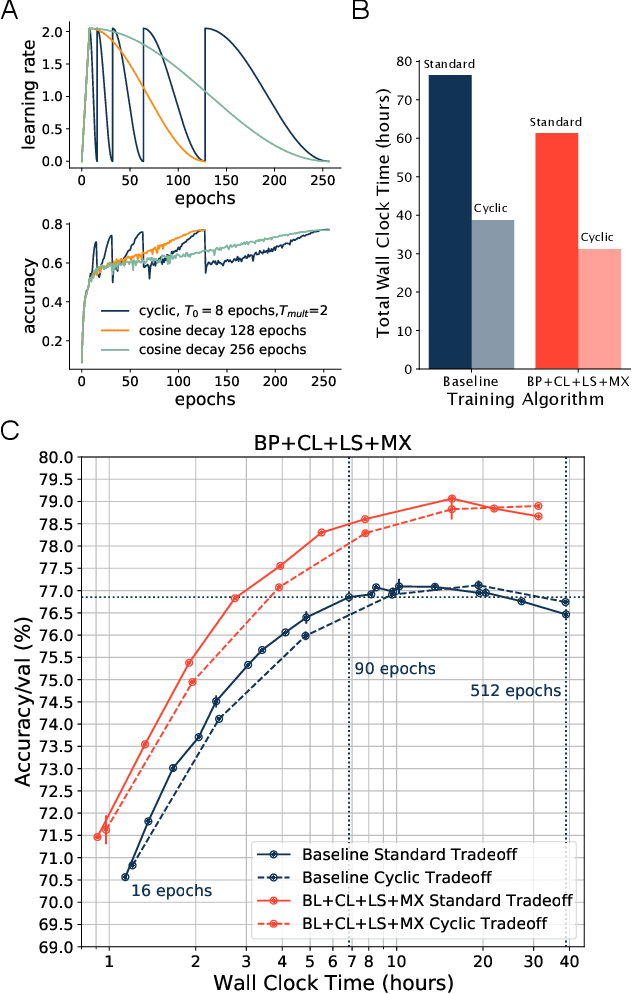
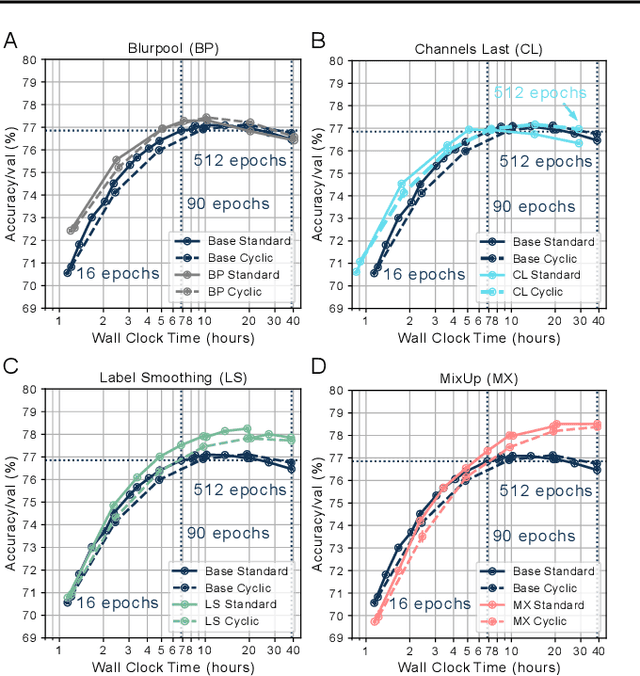
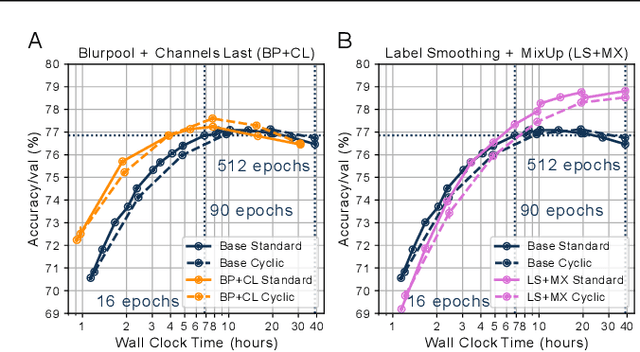
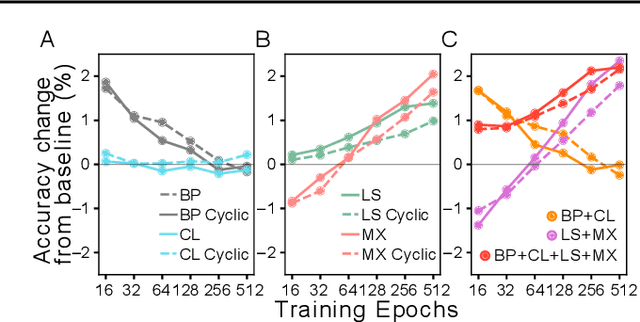
Benchmarking the tradeoff between neural network accuracy and training time is computationally expensive. Here we show how a multiplicative cyclic learning rate schedule can be used to construct a tradeoff curve in a single training run. We generate cyclic tradeoff curves for combinations of training methods such as Blurpool, Channels Last, Label Smoothing and MixUp, and highlight how these cyclic tradeoff curves can be used to evaluate the effects of algorithmic choices on network training efficiency.
Multiplying Matrices Without Multiplying
Jun 21, 2021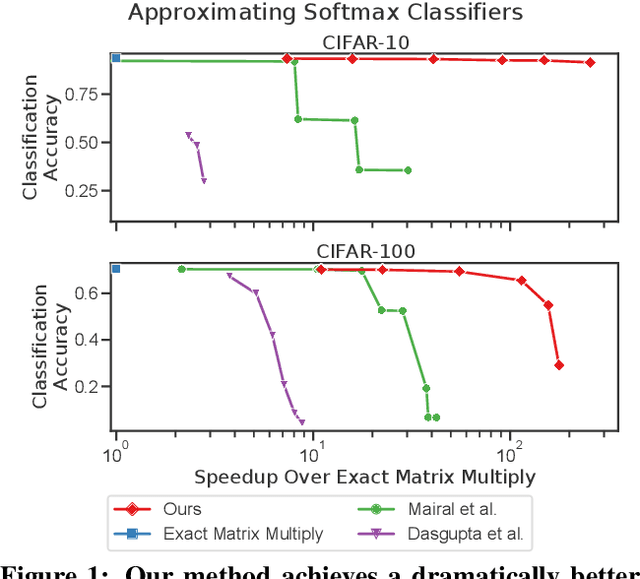
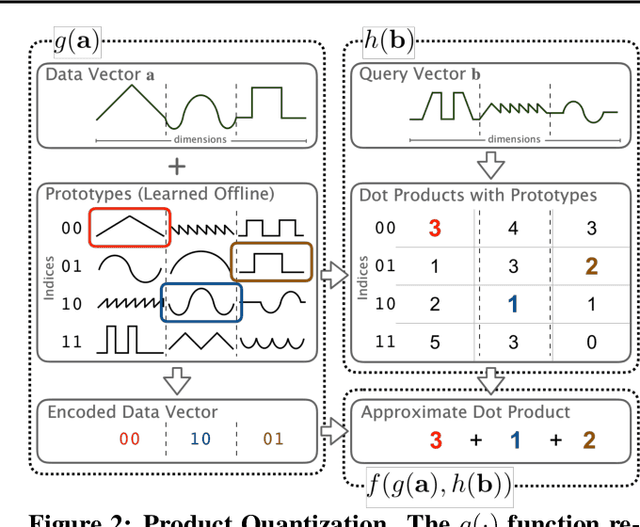
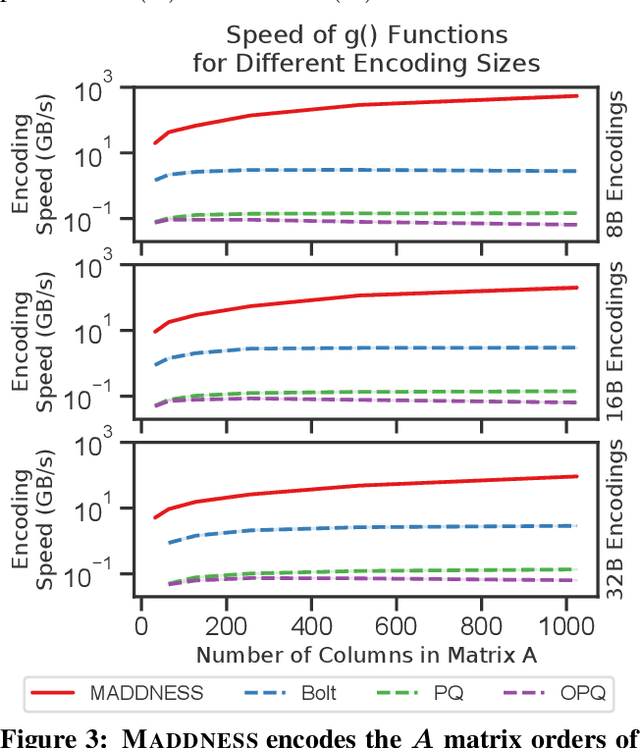
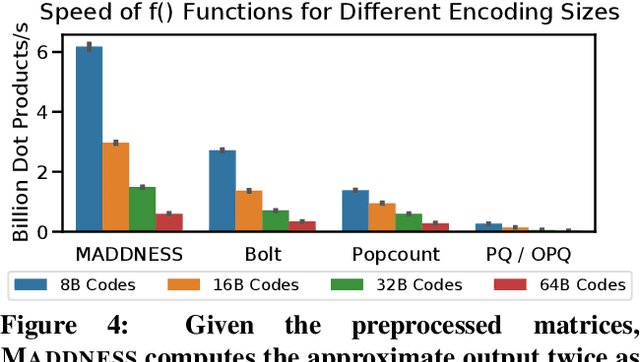
Multiplying matrices is among the most fundamental and compute-intensive operations in machine learning. Consequently, there has been significant work on efficiently approximating matrix multiplies. We introduce a learning-based algorithm for this task that greatly outperforms existing methods. Experiments using hundreds of matrices from diverse domains show that it often runs $100\times$ faster than exact matrix products and $10\times$ faster than current approximate methods. In the common case that one matrix is known ahead of time, our method also has the interesting property that it requires zero multiply-adds. These results suggest that a mixture of hashing, averaging, and byte shuffling$-$the core operations of our method$-$could be a more promising building block for machine learning than the sparsified, factorized, and/or scalar quantized matrix products that have recently been the focus of substantial research and hardware investment.
Causally-motivated Shortcut Removal Using Auxiliary Labels
Jun 03, 2021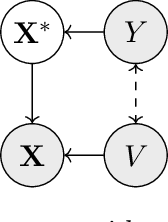

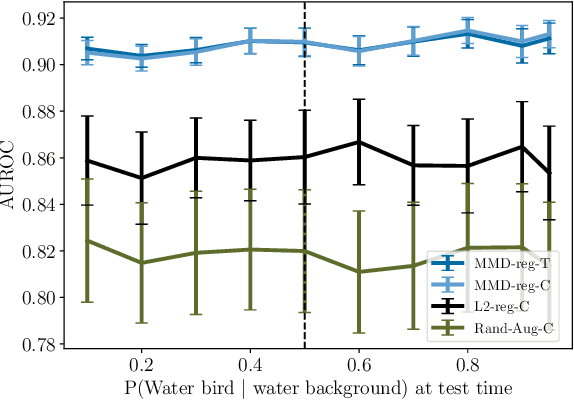
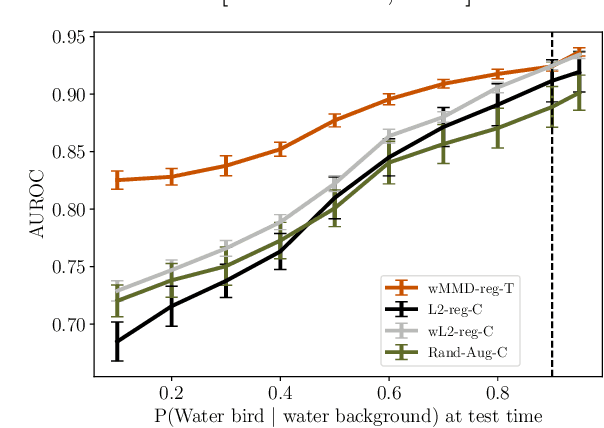
Robustness to certain forms of distribution shift is a key concern in many ML applications. Often, robustness can be formulated as enforcing invariances to particular interventions on the data generating process. Here, we study a flexible, causally-motivated approach to enforcing such invariances, paying special attention to shortcut learning, where a robust predictor can achieve optimal i.i.d generalization in principle, but instead it relies on spurious correlations or shortcuts in practice. Our approach uses auxiliary labels, typically available at training time, to enforce conditional independences between the latent factors that determine these labels. We show both theoretically and empirically that causally-motivated regularization schemes (a) lead to more robust estimators that generalize well under distribution shift, and (b) have better finite sample efficiency compared to usual regularization schemes, even in the absence of distribution shifts. Our analysis highlights important theoretical properties of training techniques commonly used in causal inference, fairness, and disentanglement literature.
When and Why Test-Time Augmentation Works
Nov 23, 2020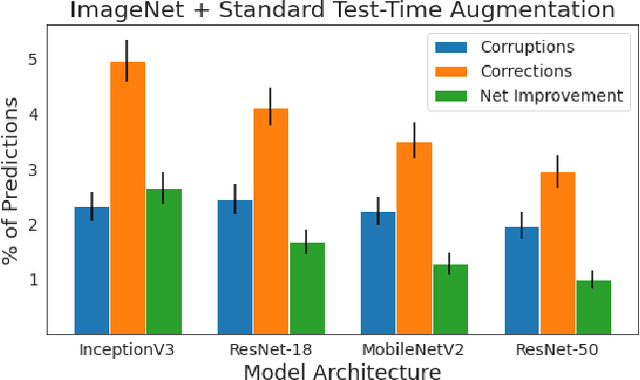
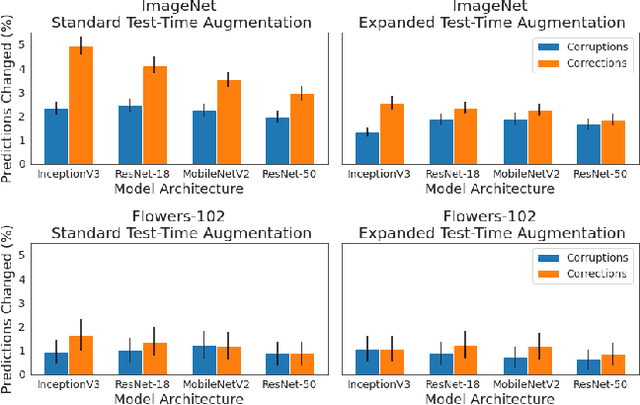
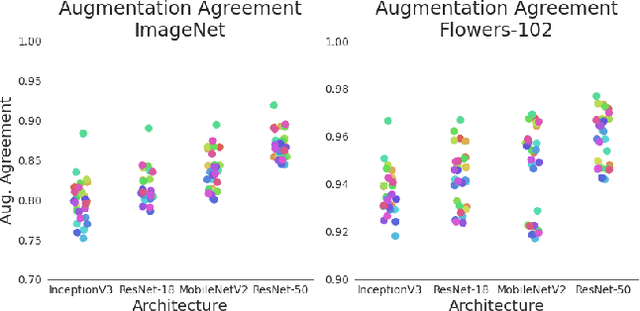
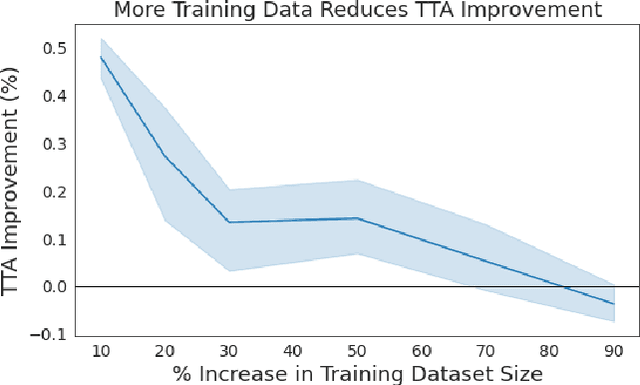
Test-time augmentation (TTA)---the aggregation of predictions across transformed versions of a test input---is a common practice in image classification. In this paper, we present theoretical and experimental analyses that shed light on 1) when test time augmentation is likely to be helpful and 2) when to use various test-time augmentation policies. A key finding is that even when TTA produces a net improvement in accuracy, it can change many correct predictions into incorrect predictions. We delve into when and why test-time augmentation changes a prediction from being correct to incorrect and vice versa. Our analysis suggests that the nature and amount of training data, the model architecture, and the augmentation policy all matter. Building on these insights, we present a learning-based method for aggregating test-time augmentations. Experiments across a diverse set of models, datasets, and augmentations show that our method delivers consistent improvements over existing approaches.
What is the State of Neural Network Pruning?
Mar 06, 2020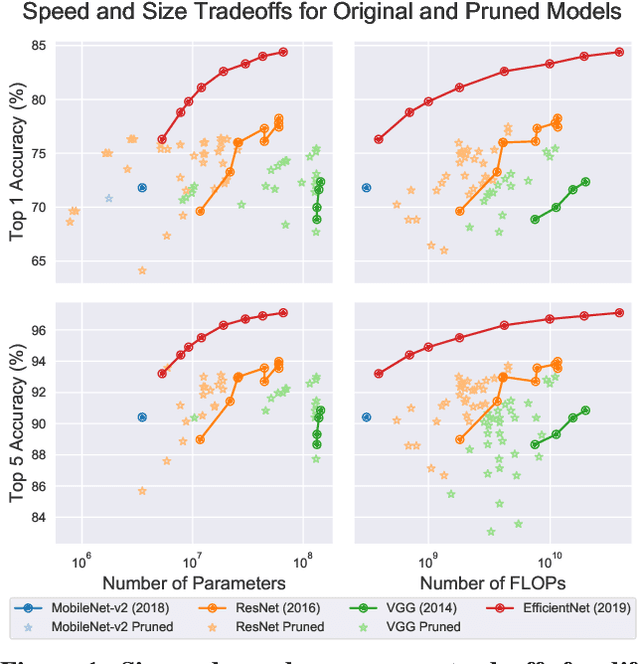
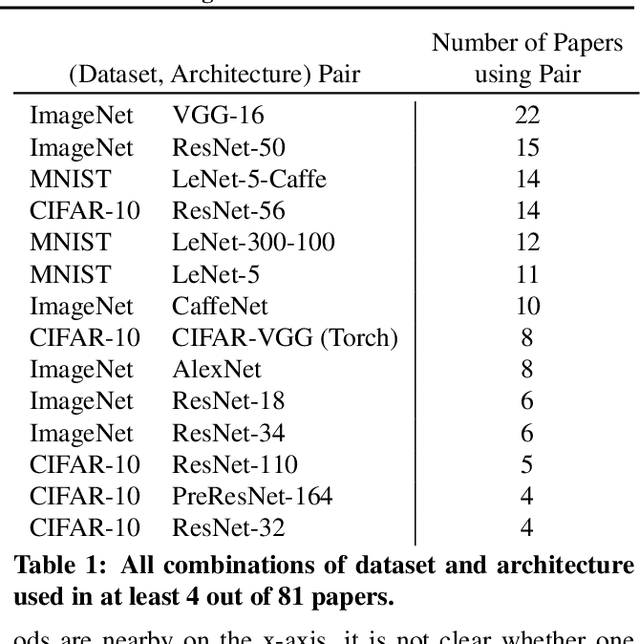
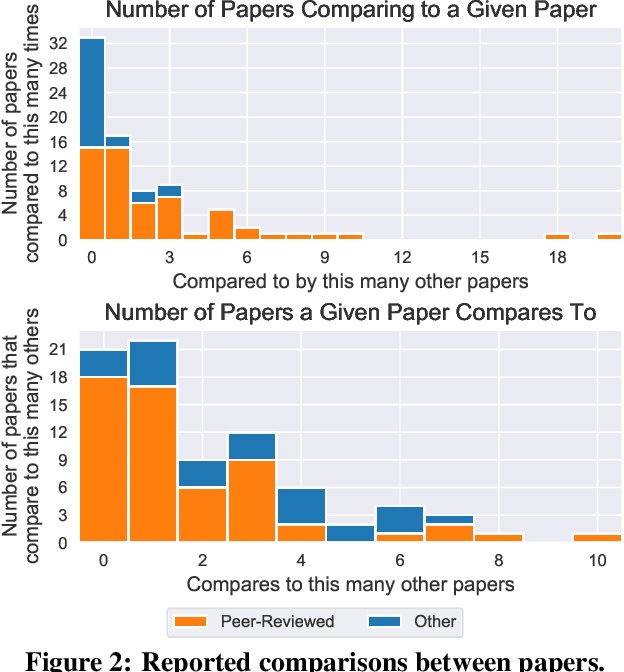
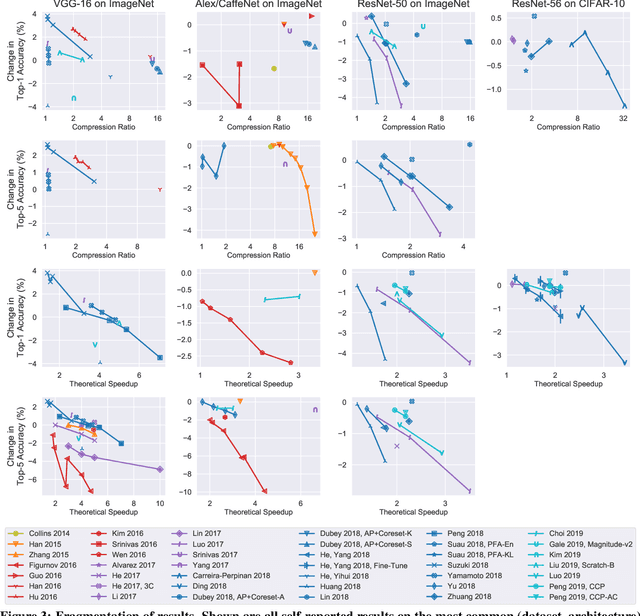
Neural network pruning---the task of reducing the size of a network by removing parameters---has been the subject of a great deal of work in recent years. We provide a meta-analysis of the literature, including an overview of approaches to pruning and consistent findings in the literature. After aggregating results across 81 papers and pruning hundreds of models in controlled conditions, our clearest finding is that the community suffers from a lack of standardized benchmarks and metrics. This deficiency is substantial enough that it is hard to compare pruning techniques to one another or determine how much progress the field has made over the past three decades. To address this situation, we identify issues with current practices, suggest concrete remedies, and introduce ShrinkBench, an open-source framework to facilitate standardized evaluations of pruning methods. We use ShrinkBench to compare various pruning techniques and show that its comprehensive evaluation can prevent common pitfalls when comparing pruning methods.
Multiple Instance Learning for ECG Risk Stratification
Dec 02, 2018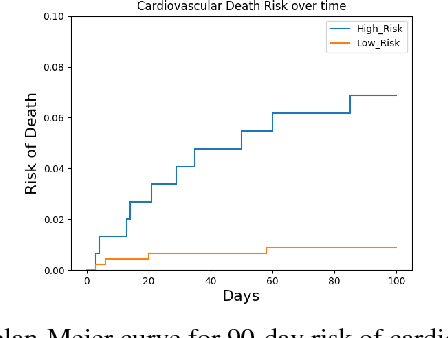

In this paper, we apply a multiple instance learning paradigm to signal-based risk stratification for cardiovascular outcomes. In contrast to methods that require hand-crafted features or domain knowledge, our method learns a representation with state-of-the-art predictive power from the raw ECG signal. We accomplish this by leveraging the multiple instance learning framework. This framework is particularly valuable to learning from biometric signals, where patient-level labels are available but signal segments are rarely annotated. We make two contributions in this paper: 1) reframing risk stratification for cardiovascular death (CVD) as a multiple instance learning problem, and 2) using this framework to design a new risk score, for which patients in the highest quartile are 15.9 times more likely to die of CVD within 90 days of hospital admission for an acute coronary syndrome.