 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
$μ$nit Scaling: Simple and Scalable FP8 LLM Training
Feb 09, 2025Large Language Model training with 8-bit floating point (FP8) formats promises significant efficiency improvements, but reduced numerical precision makes training challenging. It is currently possible to train in FP8 only if one is willing to tune various hyperparameters, reduce model scale, or accept the overhead of computing dynamic scale factors. We demonstrate simple, scalable FP8 training that requires no dynamic scaling factors or special hyperparameters, even at large model sizes. Our method, $\mu$nit Scaling ($\mu$S), also enables simple hyperparameter transfer across model widths, matched numerics across training and inference, and other desirable properties. $\mu$nit Scaling is straightforward to implement, consisting of a set of minimal interventions based on a first-principles analysis of common transformer operations. We validate our method by training models from 1B to 13B parameters, performing all hidden linear layer computations in FP8. We achieve quality equal to higher precision baselines while also training up to 33% faster.
Multi-Robot Coordination and Cooperation with Task Precedence Relationships
Sep 28, 2022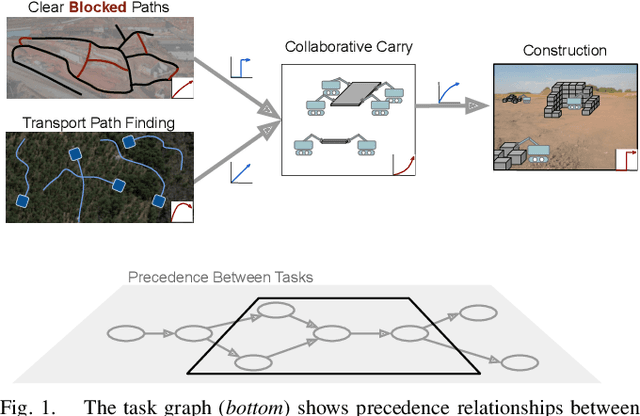

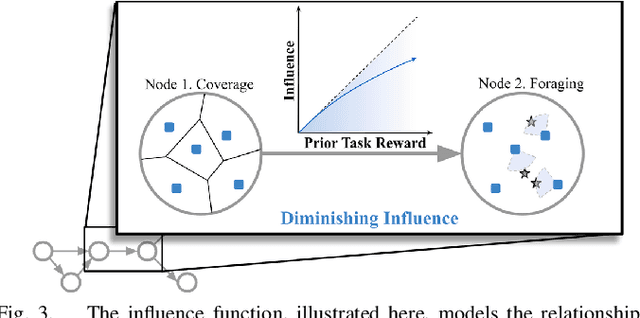
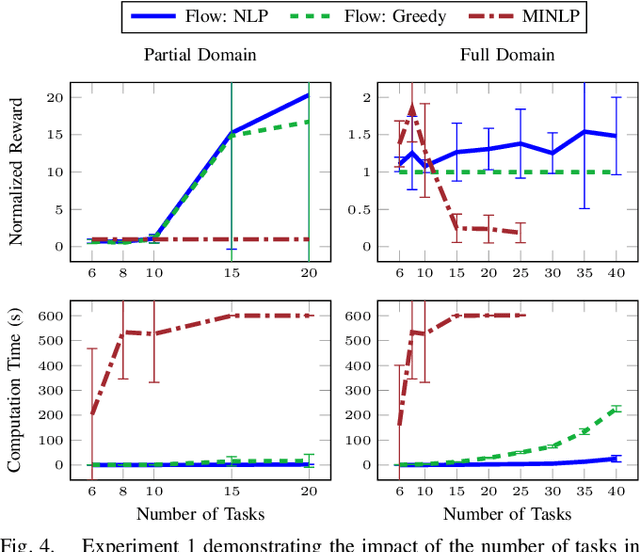
We propose a new formulation for the multi-robot task planning and allocation problem that incorporates (a) precedence relationships between tasks; (b) coordination for tasks allowing multiple robots to achieve increased efficiency; and (c) cooperation through the formation of robot coalitions for tasks that cannot be performed by individual robots alone. In our formulation, the tasks and the relationships between the tasks are specified by a task graph. We define a set of reward functions over the task graph's nodes and edges. These functions model the effect of robot coalition size on the task performance, and incorporate the influence of one task's performance on a dependent task. Solving this problem optimally is NP-hard. However, using the task graph formulation allows us to leverage min-cost network flow approaches to obtain approximate solutions efficiently. Additionally, we explore a mixed integer programming approach, which gives optimal solutions for small instances of the problem but is computationally expensive. We also develop a greedy heuristic algorithm as a baseline. Our modeling and solution approaches result in task plans that leverage task precedence relationships and robot coordination and cooperation to achieve high mission performance, even in large missions with many agents.