 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Exoplanets with Deep Learning. V. Improved Light Curve Classification for TESS Full Frame Image Observations
Jan 03, 2023The TESS mission produces a large amount of time series data, only a small fraction of which contain detectable exoplanetary transit signals. Deep learning techniques such as neural networks have proved effective at differentiating promising astrophysical eclipsing candidates from other phenomena such as stellar variability and systematic instrumental effects in an efficient, unbiased and sustainable manner. This paper presents a high quality dataset containing light curves from the Primary Mission and 1st Extended Mission full frame images and periodic signals detected via Box Least Squares (Kov\'acs et al. 2002; Hartman 2012). The dataset was curated using a thorough manual review process then used to train a neural network called Astronet-Triage-v2. On our test set, for transiting/eclipsing events we achieve a 99.6% recall (true positives over all data with positive labels) at a precision of 75.7% (true positives over all predicted positives). Since 90% of our training data is from the Primary Mission, we also test our ability to generalize on held-out 1st Extended Mission data. Here, we find an area under the precision-recall curve of 0.965, a 4% improvement over Astronet-Triage (Yu et al. 2019). On the TESS Object of Interest (TOI) Catalog through April 2022, a shortlist of planets and planet candidates, Astronet-Triage-v2 is able to recover 3577 out of 4140 TOIs, while Astronet-Triage only recovers 3349 targets at an equal level of precision. In other words, upgrading to Astronet-Triage-v2 helps save at least 200 planet candidates from being lost. The new model is currently used for planet candidate triage in the Quick-Look Pipeline (Huang et al. 2020a,b; Kunimoto et al. 2021).
Causally-motivated Shortcut Removal Using Auxiliary Labels
Jun 03, 2021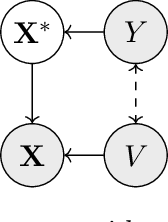

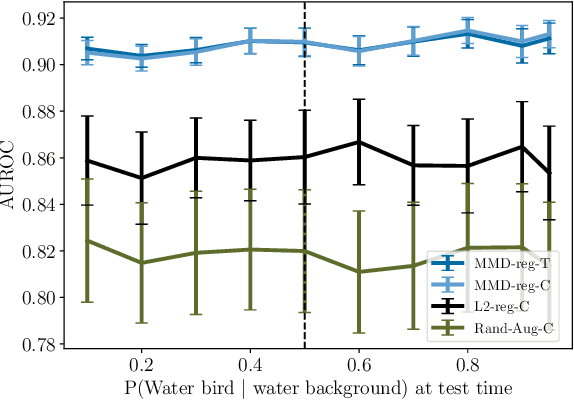
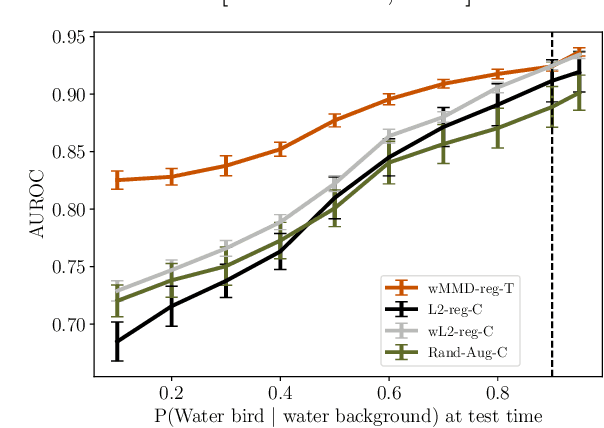
Robustness to certain forms of distribution shift is a key concern in many ML applications. Often, robustness can be formulated as enforcing invariances to particular interventions on the data generating process. Here, we study a flexible, causally-motivated approach to enforcing such invariances, paying special attention to shortcut learning, where a robust predictor can achieve optimal i.i.d generalization in principle, but instead it relies on spurious correlations or shortcuts in practice. Our approach uses auxiliary labels, typically available at training time, to enforce conditional independences between the latent factors that determine these labels. We show both theoretically and empirically that causally-motivated regularization schemes (a) lead to more robust estimators that generalize well under distribution shift, and (b) have better finite sample efficiency compared to usual regularization schemes, even in the absence of distribution shifts. Our analysis highlights important theoretical properties of training techniques commonly used in causal inference, fairness, and disentanglement literature.
Underspecification Presents Challenges for Credibility in Modern Machine Learning
Nov 06, 2020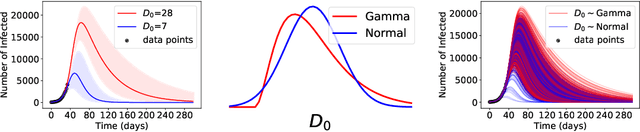


ML models often exhibit unexpectedly poor behavior when they are deployed in real-world domains. We identify underspecification as a key reason for these failures. An ML pipeline is underspecified when it can return many predictors with equivalently strong held-out performance in the training domain. Underspecification is common in modern ML pipelines, such as those based on deep learning. Predictors returned by underspecified pipelines are often treated as equivalent based on their training domain performance, but we show here that such predictors can behave very differently in deployment domains. This ambiguity can lead to instability and poor model behavior in practice, and is a distinct failure mode from previously identified issues arising from structural mismatch between training and deployment domains. We show that this problem appears in a wide variety of practical ML pipelines, using examples from computer vision, medical imaging, natural language processing, clinical risk prediction based on electronic health records, and medical genomics. Our results show the need to explicitly account for underspecification in modeling pipelines that are intended for real-world deployment in any domain.
On Robustness and Transferability of Convolutional Neural Networks
Jul 16, 2020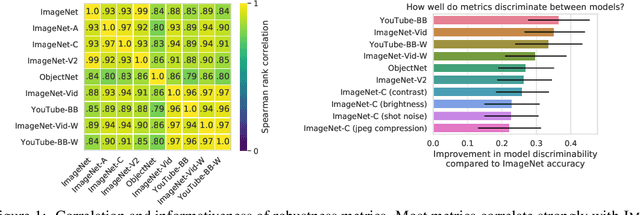

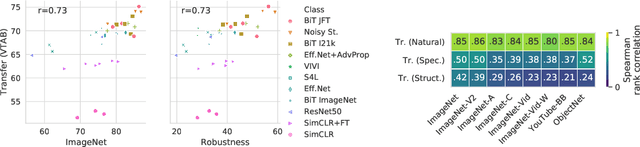
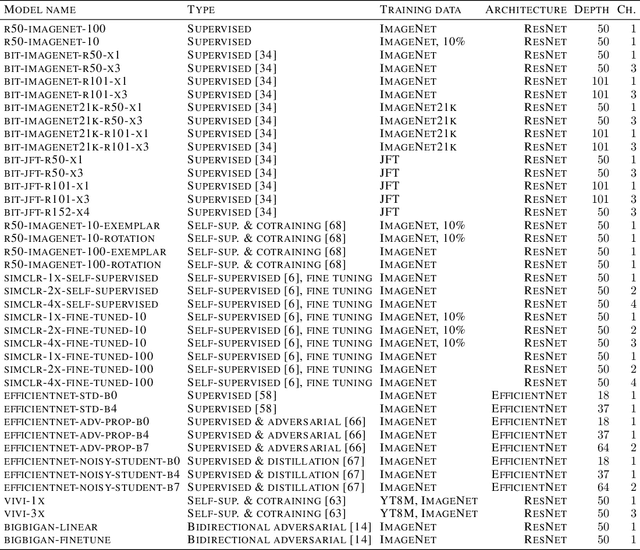
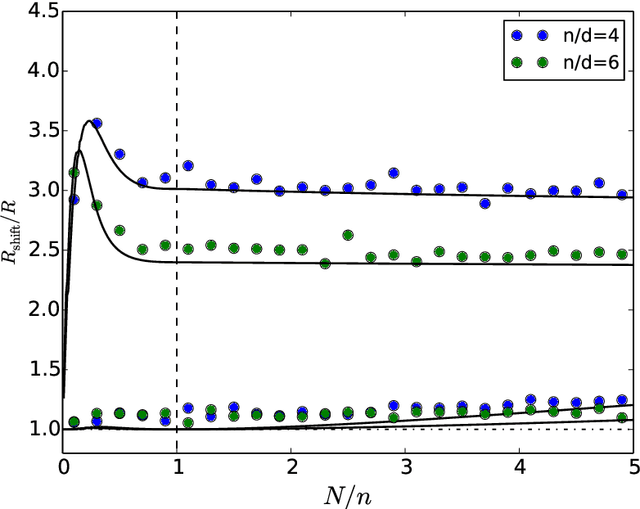
Modern deep convolutional networks (CNNs) are often criticized for not generalizing under distributional shifts. However, several recent breakthroughs in transfer learning suggest that these networks can cope with severe distribution shifts and successfully adapt to new tasks from a few training examples. In this work we revisit the out-of-distribution and transfer performance of modern image classification CNNs and investigate the impact of the pre-training data size, the model scale, and the data preprocessing pipeline. We find that increasing both the training set and model sizes significantly improve the distributional shift robustness. Furthermore, we show that, perhaps surprisingly, simple changes in the preprocessing such as modifying the image resolution can significantly mitigate robustness issues in some cases. Finally, we outline the shortcomings of existing robustness evaluation datasets and introduce a synthetic dataset we use for a systematic analysis across common factors of variation. \end{abstract}
AutoGraph: Imperative-style Coding with Graph-based Performance
Oct 16, 2018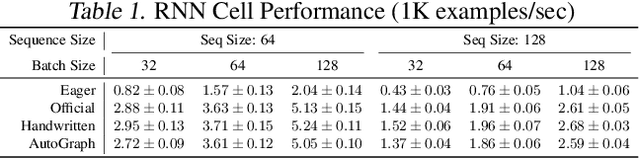


There is a perceived trade-off between machine learning code that is easy to write, and machine learning code that is scalable or fast to execute. In machine learning, imperative style libraries like Autograd and PyTorch are easy to write, but suffer from high interpretive overhead and are not easily deployable in production or mobile settings. Graph-based libraries like TensorFlow and Theano benefit from whole-program optimization and can be deployed broadly, but make expressing complex models more cumbersome. We describe how the use of staged programming in Python, via source code transformation, offers a midpoint between these two library design patterns, capturing the benefits of both. A key insight is to delay all type-dependent decisions until runtime, via dynamic dispatch. We instantiate these principles in AutoGraph, a software system that improves the programming experience of the TensorFlow library, and demonstrate usability improvements with no loss in performance compared to native TensorFlow graphs. We also show that our system is backend agnostic, and demonstrate targeting an alternate IR with characteristics not found in TensorFlow graphs.
Tangent: Automatic differentiation using source-code transformation for dynamically typed array programming
Sep 26, 2018The need to efficiently calculate first- and higher-order derivatives of increasingly complex models expressed in Python has stressed or exceeded the capabilities of available tools. In this work, we explore techniques from the field of automatic differentiation (AD) that can give researchers expressive power, performance and strong usability. These include source-code transformation (SCT), flexible gradient surgery, efficient in-place array operations, higher-order derivatives as well as mixing of forward and reverse mode AD. We implement and demonstrate these ideas in the Tangent software library for Python, the first AD framework for a dynamic language that uses SCT.
Tangent: Automatic Differentiation Using Source Code Transformation in Python
Nov 07, 2017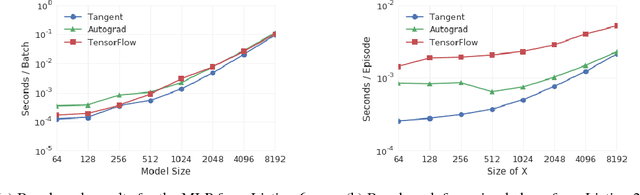
Automatic differentiation (AD) is an essential primitive for machine learning programming systems. Tangent is a new library that performs AD using source code transformation (SCT) in Python. It takes numeric functions written in a syntactic subset of Python and NumPy as input, and generates new Python functions which calculate a derivative. This approach to automatic differentiation is different from existing packages popular in machine learning, such as TensorFlow and Autograd. Advantages are that Tangent generates gradient code in Python which is readable by the user, easy to understand and debug, and has no runtime overhead. Tangent also introduces abstractions for easily injecting logic into the generated gradient code, further improving usability.