 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePopulation-Based Black-Box Optimization for Biological Sequence Design
Jun 05, 2020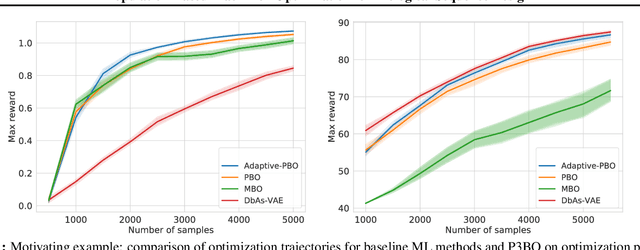
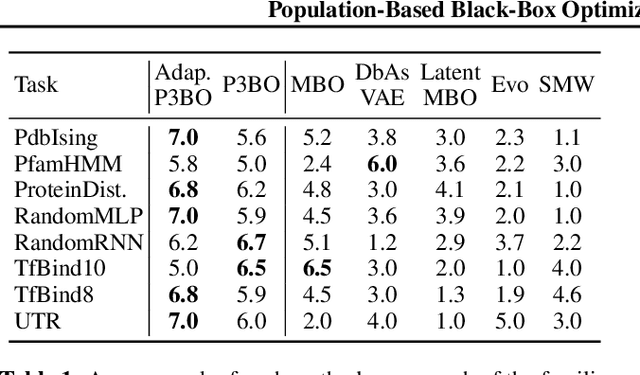
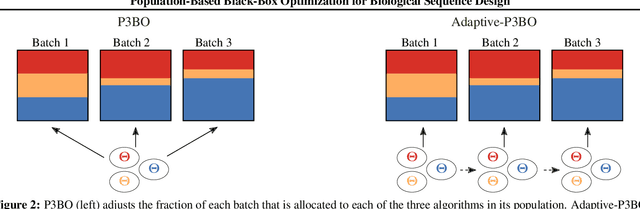
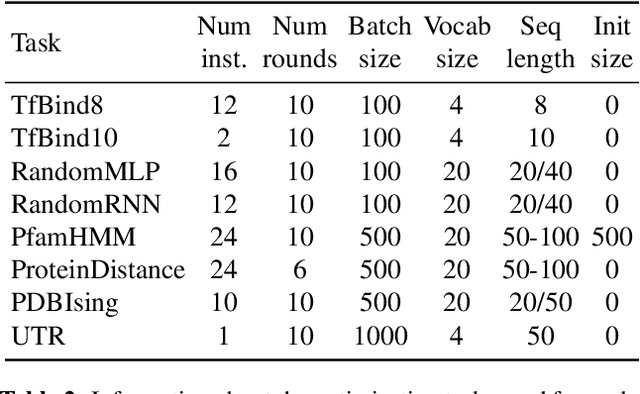
The use of black-box optimization for the design of new biological sequences is an emerging research area with potentially revolutionary impact. The cost and latency of wet-lab experiments requires methods that find good sequences in few experimental rounds of large batches of sequences--a setting that off-the-shelf black-box optimization methods are ill-equipped to handle. We find that the performance of existing methods varies drastically across optimization tasks, posing a significant obstacle to real-world applications. To improve robustness, we propose Population-Based Black-Box Optimization (P3BO), which generates batches of sequences by sampling from an ensemble of methods. The number of sequences sampled from any method is proportional to the quality of sequences it previously proposed, allowing P3BO to combine the strengths of individual methods while hedging against their innate brittleness. Adapting the hyper-parameters of each of the methods online using evolutionary optimization further improves performance. Through extensive experiments on in-silico optimization tasks, we show that P3BO outperforms any single method in its population, proposing higher quality sequences as well as more diverse batches. As such, P3BO and Adaptive-P3BO are a crucial step towards deploying ML to real-world sequence design.
Fair treatment allocations in social networks
Nov 01, 2019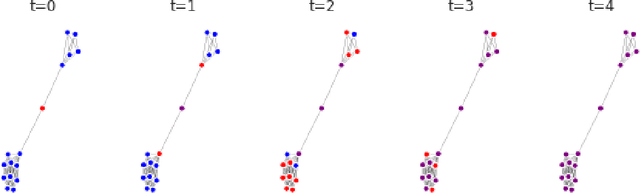

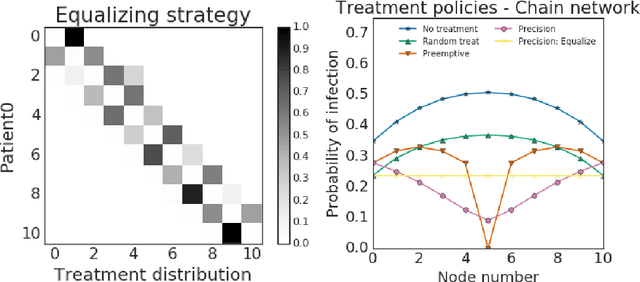
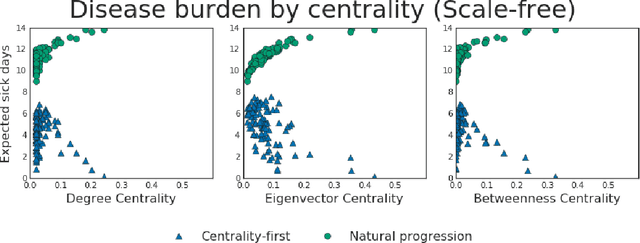
Simulations of infectious disease spread have long been used to understand how epidemics evolve and how to effectively treat them. However, comparatively little attention has been paid to understanding the fairness implications of different treatment strategies -- that is, how might such strategies distribute the expected disease burden differentially across various subgroups or communities in the population? In this work, we define the precision disease control problem -- the problem of optimally allocating vaccines in a social network in a step-by-step fashion -- and we use the ML Fairness Gym to simulate epidemic control and study it from both an efficiency and fairness perspective. We then present an exploratory analysis of several different environments and discuss the fairness implications of different treatment strategies.
Can You Trust Your Model's Uncertainty? Evaluating Predictive Uncertainty Under Dataset Shift
Jun 06, 2019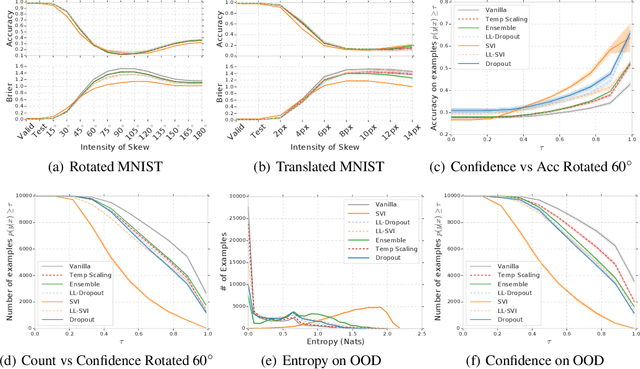
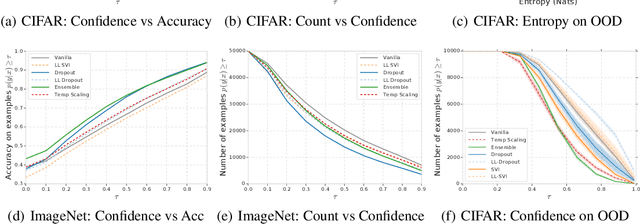
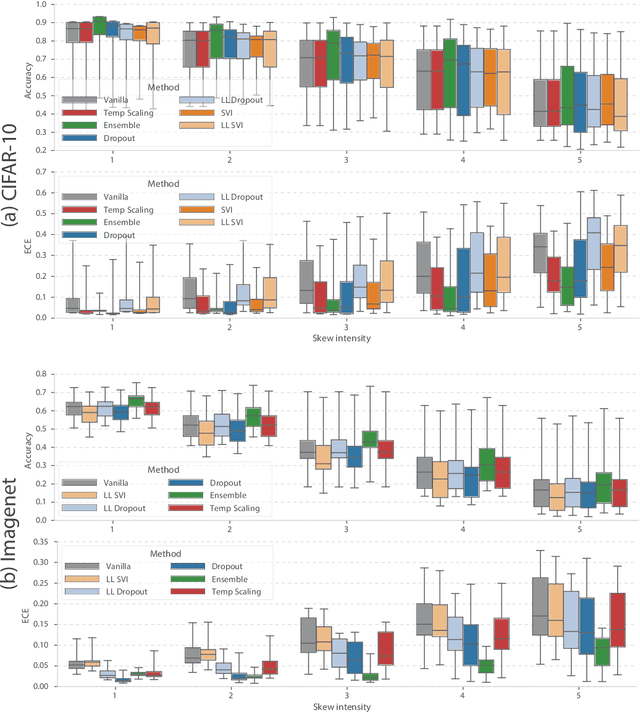
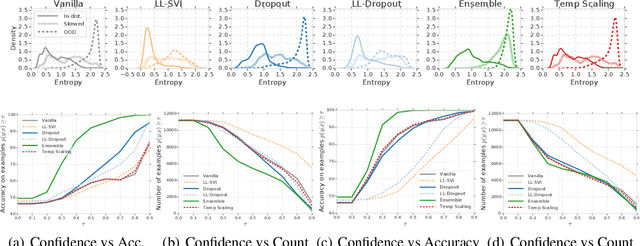
Modern machine learning methods including deep learning have achieved great success in predictive accuracy for supervised learning tasks, but may still fall short in giving useful estimates of their predictive {\em uncertainty}. Quantifying uncertainty is especially critical in real-world settings, which often involve input distributions that are shifted from the training distribution due to a variety of factors including sample bias and non-stationarity. In such settings, well calibrated uncertainty estimates convey information about when a model's output should (or should not) be trusted. Many probabilistic deep learning methods, including Bayesian-and non-Bayesian methods, have been proposed in the literature for quantifying predictive uncertainty, but to our knowledge there has not previously been a rigorous large-scale empirical comparison of these methods under dataset shift. We present a large-scale benchmark of existing state-of-the-art methods on classification problems and investigate the effect of dataset shift on accuracy and calibration. We find that traditional post-hoc calibration does indeed fall short, as do several other previous methods. However, some methods that marginalize over models give surprisingly strong results across a broad spectrum of tasks.
Avoiding a Tragedy of the Commons in the Peer Review Process
Dec 18, 2018
Peer review is the foundation of scientific publication, and the task of reviewing has long been seen as a cornerstone of professional service. However, the massive growth in the field of machine learning has put this community benefit under stress, threatening both the sustainability of an effective review process and the overall progress of the field. In this position paper, we argue that a tragedy of the commons outcome may be avoided by emphasizing the professional aspects of this service. In particular, we propose a rubric to hold reviewers to an objective standard for review quality. In turn, we also propose that reviewers be given appropriate incentive. As one possible such incentive, we explore the idea of financial compensation on a per-review basis. We suggest reasonable funding models and thoughts on long term effects.
AutoGraph: Imperative-style Coding with Graph-based Performance
Oct 16, 2018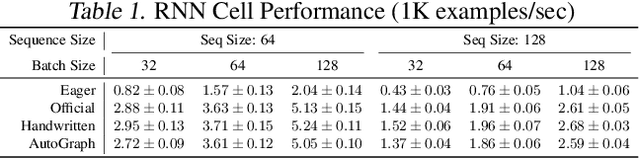


There is a perceived trade-off between machine learning code that is easy to write, and machine learning code that is scalable or fast to execute. In machine learning, imperative style libraries like Autograd and PyTorch are easy to write, but suffer from high interpretive overhead and are not easily deployable in production or mobile settings. Graph-based libraries like TensorFlow and Theano benefit from whole-program optimization and can be deployed broadly, but make expressing complex models more cumbersome. We describe how the use of staged programming in Python, via source code transformation, offers a midpoint between these two library design patterns, capturing the benefits of both. A key insight is to delay all type-dependent decisions until runtime, via dynamic dispatch. We instantiate these principles in AutoGraph, a software system that improves the programming experience of the TensorFlow library, and demonstrate usability improvements with no loss in performance compared to native TensorFlow graphs. We also show that our system is backend agnostic, and demonstrate targeting an alternate IR with characteristics not found in TensorFlow graphs.
TensorFlow Estimators: Managing Simplicity vs. Flexibility in High-Level Machine Learning Frameworks
Aug 08, 2017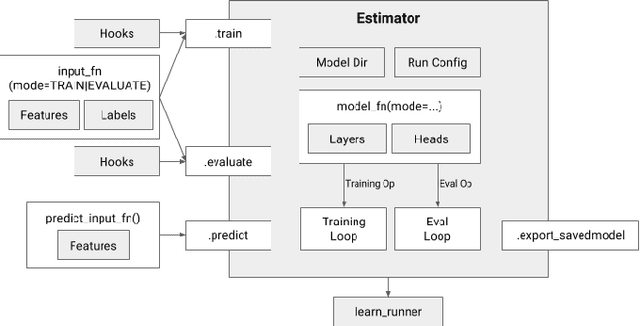
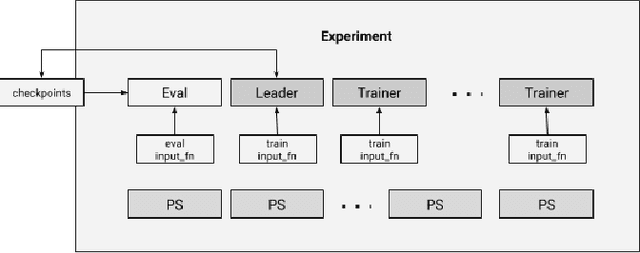
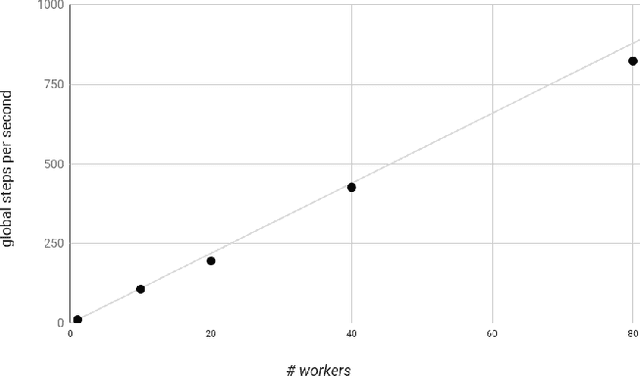
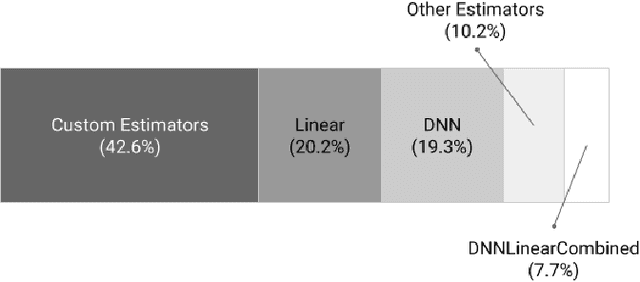
We present a framework for specifying, training, evaluating, and deploying machine learning models. Our focus is on simplifying cutting edge machine learning for practitioners in order to bring such technologies into production. Recognizing the fast evolution of the field of deep learning, we make no attempt to capture the design space of all possible model architectures in a domain- specific language (DSL) or similar configuration language. We allow users to write code to define their models, but provide abstractions that guide develop- ers to write models in ways conducive to productionization. We also provide a unifying Estimator interface, making it possible to write downstream infrastructure (e.g. distributed training, hyperparameter tuning) independent of the model implementation. We balance the competing demands for flexibility and simplicity by offering APIs at different levels of abstraction, making common model architectures available out of the box, while providing a library of utilities designed to speed up experimentation with model architectures. To make out of the box models flexible and usable across a wide range of problems, these canned Estimators are parameterized not only over traditional hyperparameters, but also using feature columns, a declarative specification describing how to interpret input data. We discuss our experience in using this framework in re- search and production environments, and show the impact on code health, maintainability, and development speed.