 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Attention with Performers
Sep 30, 2020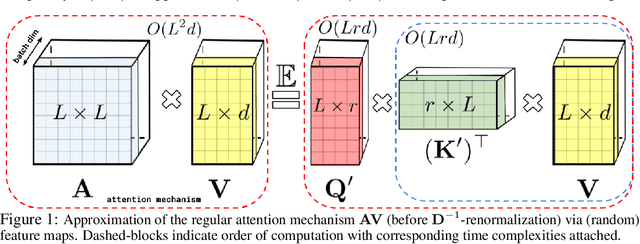
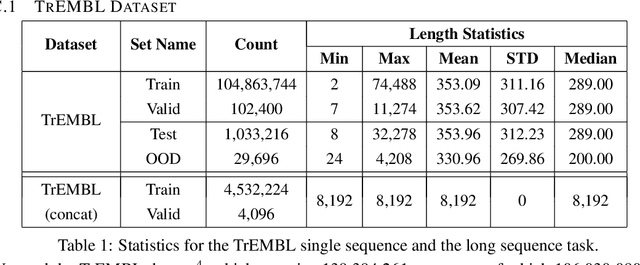
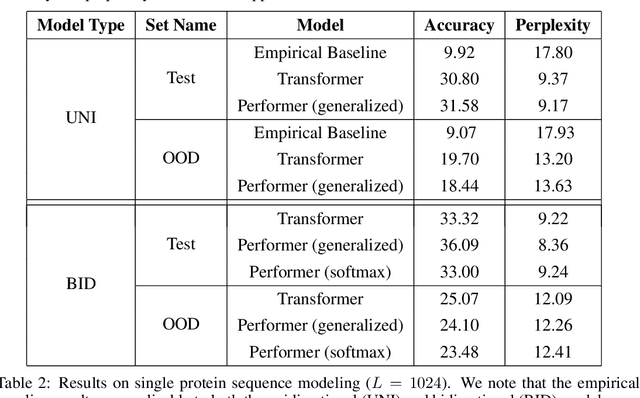
We introduce Performers, Transformer architectures which can estimate regular (softmax) full-rank-attention Transformers with provable accuracy, but using only linear (as opposed to quadratic) space and time complexity, without relying on any priors such as sparsity or low-rankness. To approximate softmax attention-kernels, Performers use a novel Fast Attention Via positive Orthogonal Random features approach (FAVOR+), which may be of independent interest for scalable kernel methods. FAVOR+ can be also used to efficiently model kernelizable attention mechanisms beyond softmax. This representational power is crucial to accurately compare softmax with other kernels for the first time on large-scale tasks, beyond the reach of regular Transformers, and investigate optimal attention-kernels. Performers are linear architectures fully compatible with regular Transformers and with strong theoretical guarantees: unbiased or nearly-unbiased estimation of the attention matrix, uniform convergence and low estimation variance. We tested Performers on a rich set of tasks stretching from pixel-prediction through text models to protein sequence modeling. We demonstrate competitive results with other examined efficient sparse and dense attention methods, showcasing effectiveness of the novel attention-learning paradigm leveraged by Performers.
Population-Based Black-Box Optimization for Biological Sequence Design
Jun 05, 2020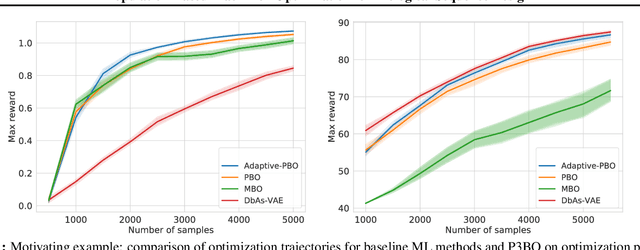
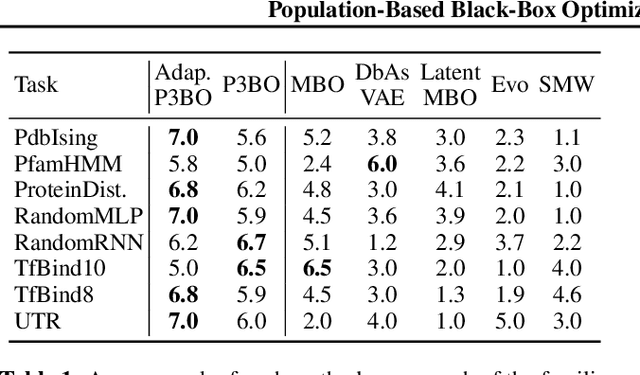
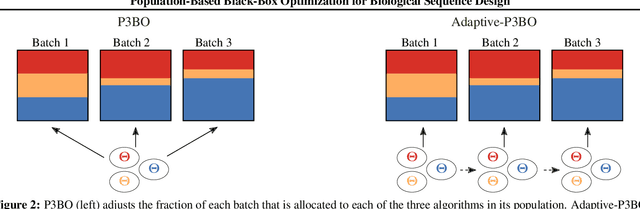
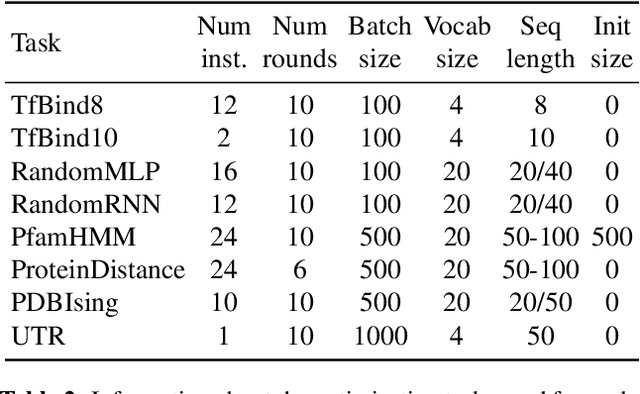
The use of black-box optimization for the design of new biological sequences is an emerging research area with potentially revolutionary impact. The cost and latency of wet-lab experiments requires methods that find good sequences in few experimental rounds of large batches of sequences--a setting that off-the-shelf black-box optimization methods are ill-equipped to handle. We find that the performance of existing methods varies drastically across optimization tasks, posing a significant obstacle to real-world applications. To improve robustness, we propose Population-Based Black-Box Optimization (P3BO), which generates batches of sequences by sampling from an ensemble of methods. The number of sequences sampled from any method is proportional to the quality of sequences it previously proposed, allowing P3BO to combine the strengths of individual methods while hedging against their innate brittleness. Adapting the hyper-parameters of each of the methods online using evolutionary optimization further improves performance. Through extensive experiments on in-silico optimization tasks, we show that P3BO outperforms any single method in its population, proposing higher quality sequences as well as more diverse batches. As such, P3BO and Adaptive-P3BO are a crucial step towards deploying ML to real-world sequence design.
Direct Optimization through $\arg \max$ for Discrete Variational Auto-Encoder
Oct 11, 2018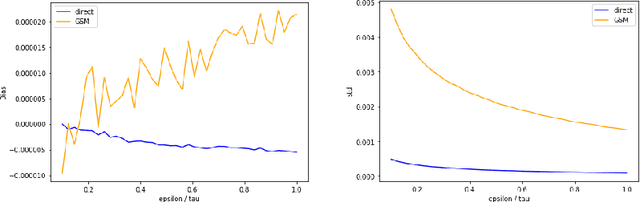

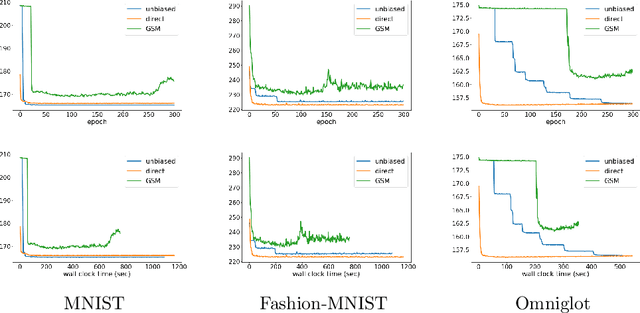
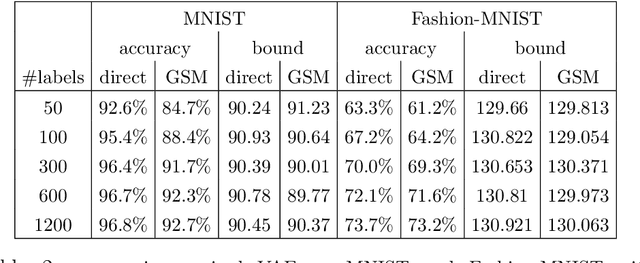
Reparameterization of variational auto-encoders with continuous latent spaces is an effective method for reducing the variance of their gradient estimates. However, using the same approach when latent variables are discrete is problematic, due to the resulting non-differentiable objective. In this work, we present a direct optimization method that propagates gradients through a non-differentiable $\arg \max$ prediction operation. We apply this method to discrete variational auto-encoders, by modeling a discrete random variable by the $\arg \max$ function of the Gumbel-Max perturbation model.
The Variational Homoencoder: Learning to learn high capacity generative models from few examples
Jul 24, 2018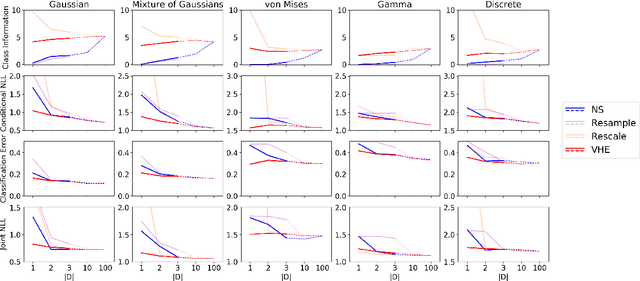


Hierarchical Bayesian methods can unify many related tasks (e.g. k-shot classification, conditional and unconditional generation) as inference within a single generative model. However, when this generative model is expressed as a powerful neural network such as a PixelCNN, we show that existing learning techniques typically fail to effectively use latent variables. To address this, we develop a modification of the Variational Autoencoder in which encoded observations are decoded to new elements from the same class. This technique, which we call a Variational Homoencoder (VHE), produces a hierarchical latent variable model which better utilises latent variables. We use the VHE framework to learn a hierarchical PixelCNN on the Omniglot dataset, which outperforms all existing models on test set likelihood and achieves strong performance on one-shot generation and classification tasks. We additionally validate the VHE on natural images from the YouTube Faces database. Finally, we develop extensions of the model that apply to richer dataset structures such as factorial and hierarchical categories.
Evaluating Prerequisite Qualities for Learning End-to-End Dialog Systems
Apr 19, 2016


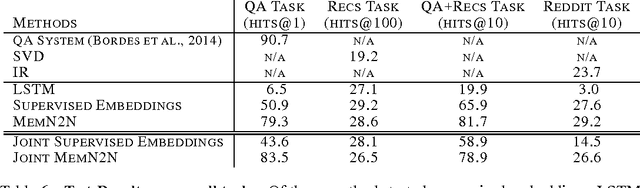
A long-term goal of machine learning is to build intelligent conversational agents. One recent popular approach is to train end-to-end models on a large amount of real dialog transcripts between humans (Sordoni et al., 2015; Vinyals & Le, 2015; Shang et al., 2015). However, this approach leaves many questions unanswered as an understanding of the precise successes and shortcomings of each model is hard to assess. A contrasting recent proposal are the bAbI tasks (Weston et al., 2015b) which are synthetic data that measure the ability of learning machines at various reasoning tasks over toy language. Unfortunately, those tests are very small and hence may encourage methods that do not scale. In this work, we propose a suite of new tasks of a much larger scale that attempt to bridge the gap between the two regimes. Choosing the domain of movies, we provide tasks that test the ability of models to answer factual questions (utilizing OMDB), provide personalization (utilizing MovieLens), carry short conversations about the two, and finally to perform on natural dialogs from Reddit. We provide a dataset covering 75k movie entities and with 3.5M training examples. We present results of various models on these tasks, and evaluate their performance.