 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIRS-Bench: a Suite of Tasks for Frontier AI Research Science Agents
Feb 09, 2026LLM agents hold significant promise for advancing scientific research. To accelerate this progress, we introduce AIRS-Bench (the AI Research Science Benchmark), a suite of 20 tasks sourced from state-of-the-art machine learning papers. These tasks span diverse domains, including language modeling, mathematics, bioinformatics, and time series forecasting. AIRS-Bench tasks assess agentic capabilities over the full research lifecycle -- including idea generation, experiment analysis and iterative refinement -- without providing baseline code. The AIRS-Bench task format is versatile, enabling easy integration of new tasks and rigorous comparison across different agentic frameworks. We establish baselines using frontier models paired with both sequential and parallel scaffolds. Our results show that agents exceed human SOTA in four tasks but fail to match it in sixteen others. Even when agents surpass human benchmarks, they do not reach the theoretical performance ceiling for the underlying tasks. These findings indicate that AIRS-Bench is far from saturated and offers substantial room for improvement. We open-source the AIRS-Bench task definitions and evaluation code to catalyze further development in autonomous scientific research.
Aerial Assistance System for Automated Firefighting during Turntable Ladder Operations
Nov 18, 2025Fires in industrial facilities pose special challenges to firefighters, e.g., due to the sheer size and scale of the buildings. The resulting visual obstructions impair firefighting accuracy, further compounded by inaccurate assessments of the fire's location. Such imprecision simultaneously increases the overall damage and prolongs the fire-brigades operation unnecessarily. We propose an automated assistance system for firefighting using a motorized fire monitor on a turntable ladder with aerial support from an unmanned aerial vehicle (UAV). The UAV flies autonomously within an obstacle-free flight funnel derived from geodata, detecting and localizing heat sources. An operator supervises the operation on a handheld controller and selects a fire target in reach. After the selection, the UAV automatically plans and traverses between two triangulation poses for continued fire localization. Simultaneously, our system steers the fire monitor to ensure the water jet reaches the detected heat source. In preliminary tests, our assistance system successfully localized multiple heat sources and directed a water jet towards the fires.
How to Deploy a 10-km Interferometric Radio Telescope on the Moon with Just Four Tethered Robots
Sep 06, 2022

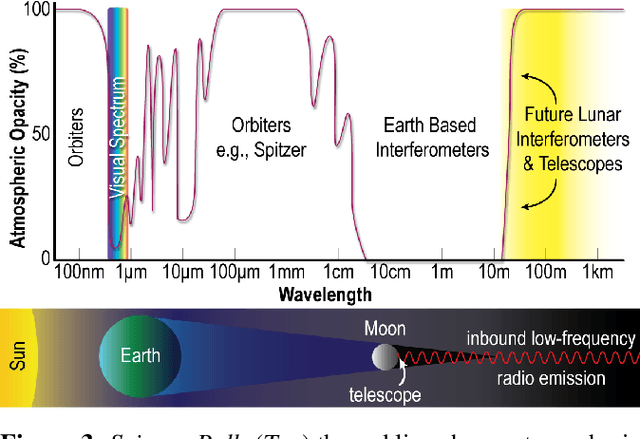
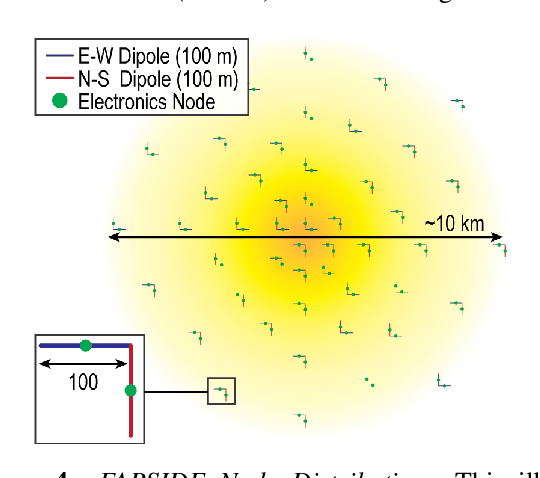
The Far-side Array for Radio Science Investigations of the Dark ages and Exoplanets (FARSIDE) is a proposed mission concept to the lunar far side that seeks to deploy and operate an array of 128 dual-polarization, dipole antennas over a region of 100 square kilometers. The resulting interferometric radio telescope would provide unprecedented radio images of distant star systems, allowing for the investigation of faint radio signatures of coronal mass ejections and energetic particle events and could also lead to the detection of magnetospheres around exoplanets within their parent star's habitable zone. Simultaneously, FARSIDE would also measure the "Dark Ages" of the early Universe at a global 21-cm signal across a range of red shifts (z approximately 50-100). Each discrete antenna node in the array is connected to a central hub (located at the lander) via a communication and power tether. Nodes are driven by cold=operable electronics that continuously monitor an extremely wide-band of frequencies (200 kHz to 40 MHz), which surpass the capabilities of Earth-based telescopes by two orders of magnitude. Achieving this ground-breaking capability requires a robust deployment strategy on the lunar surface, which is feasible with existing, high TRL technologies (demonstrated or under active development) and is capable of delivery to the surface on next-generation commercial landers, such as Blue Origin's Blue Moon Lander. This paper presents an antenna packaging, placement, and surface deployment trade study that leverages recent advances in tethered mobile robots under development at NASA's Jet Propulsion Laboratory, which are used to deploy a flat, antenna-embedded, tape tether with optical communication and power transmission capabilities.
* 8 pages, 17 figures, IEEE Aerospace Conference Proceedings, 2021
The Second Conversational Intelligence Challenge (ConvAI2)
Jan 31, 2019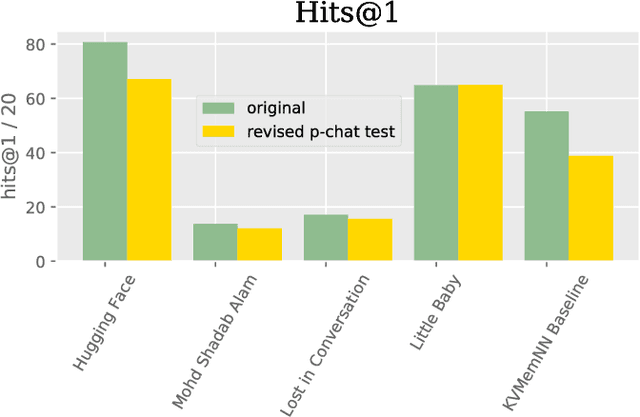

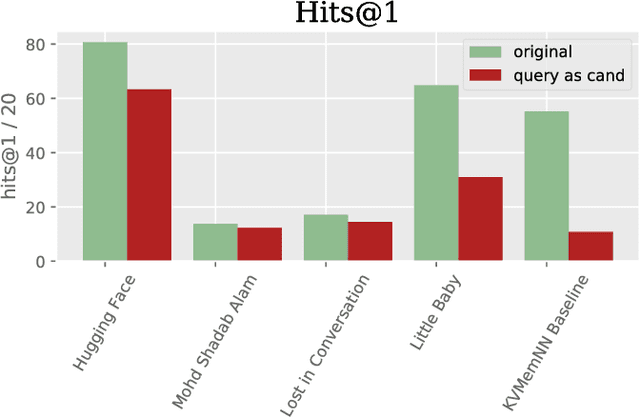
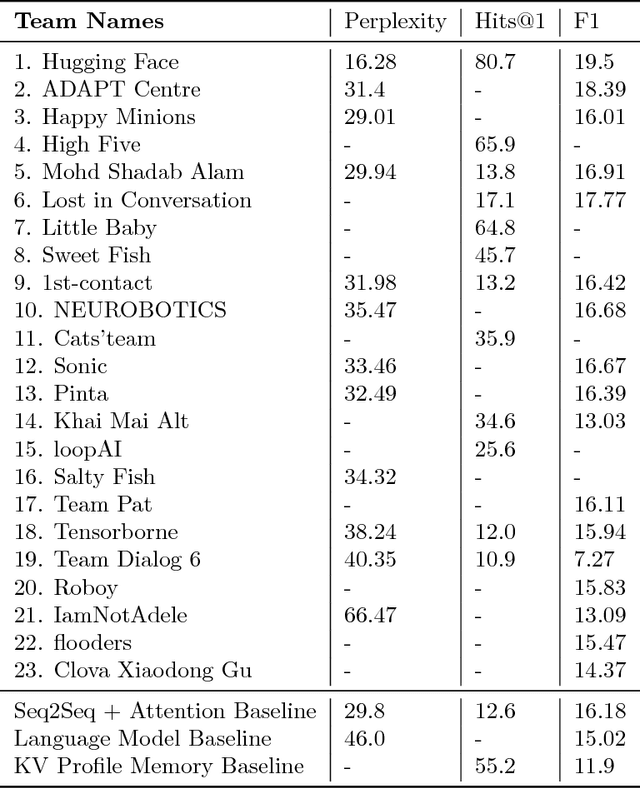
We describe the setting and results of the ConvAI2 NeurIPS competition that aims to further the state-of-the-art in open-domain chatbots. Some key takeaways from the competition are: (i) pretrained Transformer variants are currently the best performing models on this task, (ii) but to improve performance on multi-turn conversations with humans, future systems must go beyond single word metrics like perplexity to measure the performance across sequences of utterances (conversations) -- in terms of repetition, consistency and balance of dialogue acts (e.g. how many questions asked vs. answered).
Key-Value Memory Networks for Directly Reading Documents
Oct 10, 2016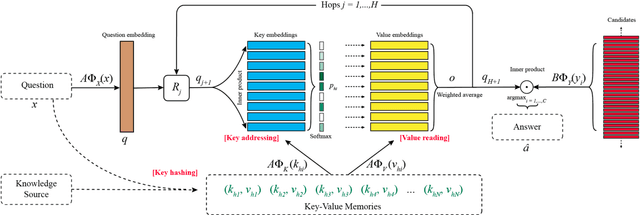

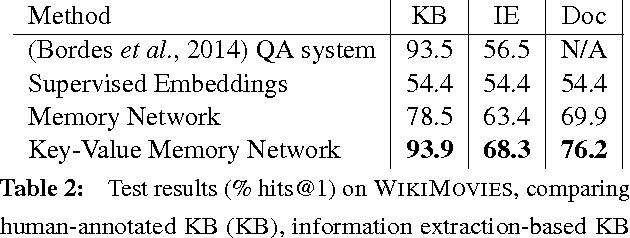

Directly reading documents and being able to answer questions from them is an unsolved challenge. To avoid its inherent difficulty, question answering (QA) has been directed towards using Knowledge Bases (KBs) instead, which has proven effective. Unfortunately KBs often suffer from being too restrictive, as the schema cannot support certain types of answers, and too sparse, e.g. Wikipedia contains much more information than Freebase. In this work we introduce a new method, Key-Value Memory Networks, that makes reading documents more viable by utilizing different encodings in the addressing and output stages of the memory read operation. To compare using KBs, information extraction or Wikipedia documents directly in a single framework we construct an analysis tool, WikiMovies, a QA dataset that contains raw text alongside a preprocessed KB, in the domain of movies. Our method reduces the gap between all three settings. It also achieves state-of-the-art results on the existing WikiQA benchmark.
Evaluating Prerequisite Qualities for Learning End-to-End Dialog Systems
Apr 19, 2016


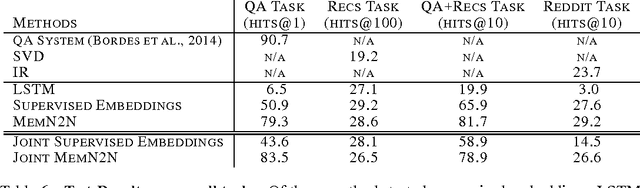
A long-term goal of machine learning is to build intelligent conversational agents. One recent popular approach is to train end-to-end models on a large amount of real dialog transcripts between humans (Sordoni et al., 2015; Vinyals & Le, 2015; Shang et al., 2015). However, this approach leaves many questions unanswered as an understanding of the precise successes and shortcomings of each model is hard to assess. A contrasting recent proposal are the bAbI tasks (Weston et al., 2015b) which are synthetic data that measure the ability of learning machines at various reasoning tasks over toy language. Unfortunately, those tests are very small and hence may encourage methods that do not scale. In this work, we propose a suite of new tasks of a much larger scale that attempt to bridge the gap between the two regimes. Choosing the domain of movies, we provide tasks that test the ability of models to answer factual questions (utilizing OMDB), provide personalization (utilizing MovieLens), carry short conversations about the two, and finally to perform on natural dialogs from Reddit. We provide a dataset covering 75k movie entities and with 3.5M training examples. We present results of various models on these tasks, and evaluate their performance.