 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining language models to follow instructions with human feedback
Mar 04, 2022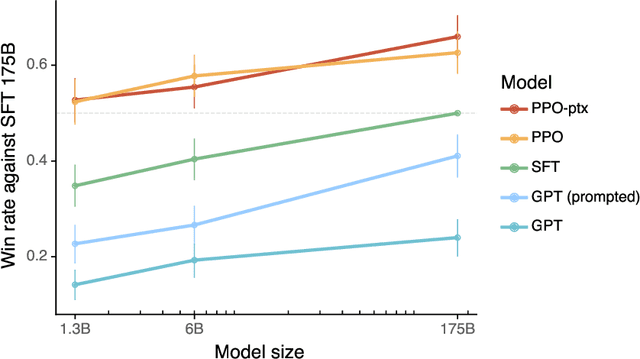

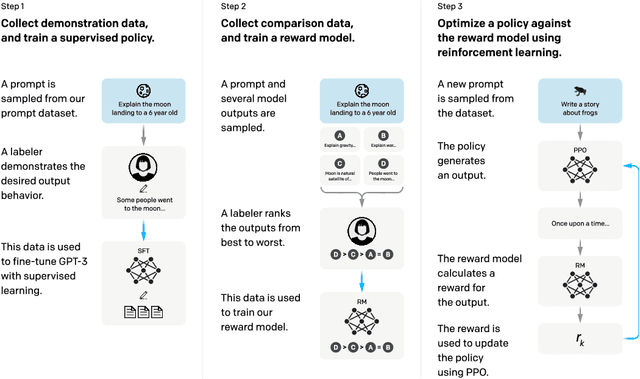

Making language models bigger does not inherently make them better at following a user's intent. For example, large language models can generate outputs that are untruthful, toxic, or simply not helpful to the user. In other words, these models are not aligned with their users. In this paper, we show an avenue for aligning language models with user intent on a wide range of tasks by fine-tuning with human feedback. Starting with a set of labeler-written prompts and prompts submitted through the OpenAI API, we collect a dataset of labeler demonstrations of the desired model behavior, which we use to fine-tune GPT-3 using supervised learning. We then collect a dataset of rankings of model outputs, which we use to further fine-tune this supervised model using reinforcement learning from human feedback. We call the resulting models InstructGPT. In human evaluations on our prompt distribution, outputs from the 1.3B parameter InstructGPT model are preferred to outputs from the 175B GPT-3, despite having 100x fewer parameters. Moreover, InstructGPT models show improvements in truthfulness and reductions in toxic output generation while having minimal performance regressions on public NLP datasets. Even though InstructGPT still makes simple mistakes, our results show that fine-tuning with human feedback is a promising direction for aligning language models with human intent.
Recursively Summarizing Books with Human Feedback
Sep 27, 2021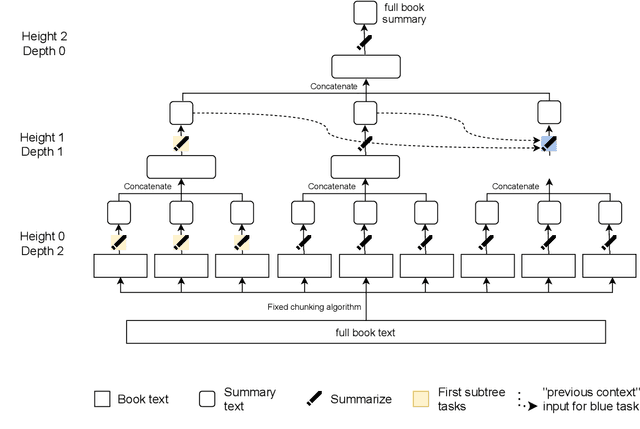
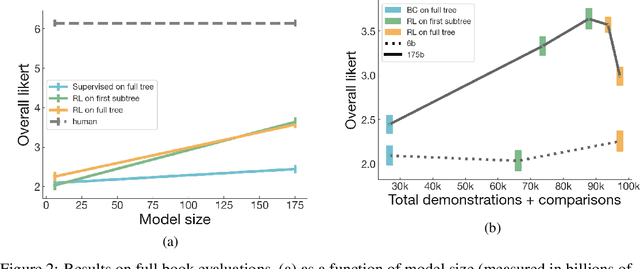
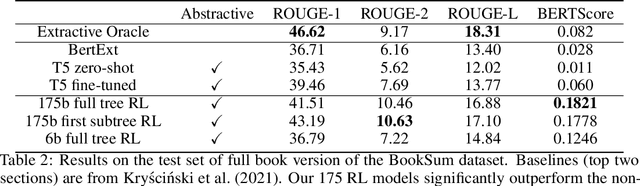
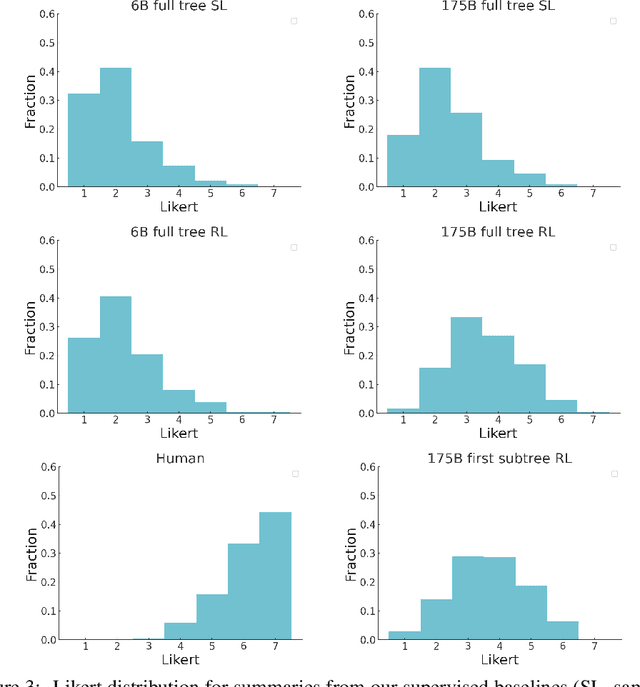
A major challenge for scaling machine learning is training models to perform tasks that are very difficult or time-consuming for humans to evaluate. We present progress on this problem on the task of abstractive summarization of entire fiction novels. Our method combines learning from human feedback with recursive task decomposition: we use models trained on smaller parts of the task to assist humans in giving feedback on the broader task. We collect a large volume of demonstrations and comparisons from human labelers, and fine-tune GPT-3 using behavioral cloning and reward modeling to do summarization recursively. At inference time, the model first summarizes small sections of the book and then recursively summarizes these summaries to produce a summary of the entire book. Our human labelers are able to supervise and evaluate the models quickly, despite not having read the entire books themselves. Our resulting model generates sensible summaries of entire books, even matching the quality of human-written summaries in a few cases ($\sim5\%$ of books). We achieve state-of-the-art results on the recent BookSum dataset for book-length summarization. A zero-shot question-answering model using these summaries achieves state-of-the-art results on the challenging NarrativeQA benchmark for answering questions about books and movie scripts. We release datasets of samples from our model.
Learning to summarize from human feedback
Sep 02, 2020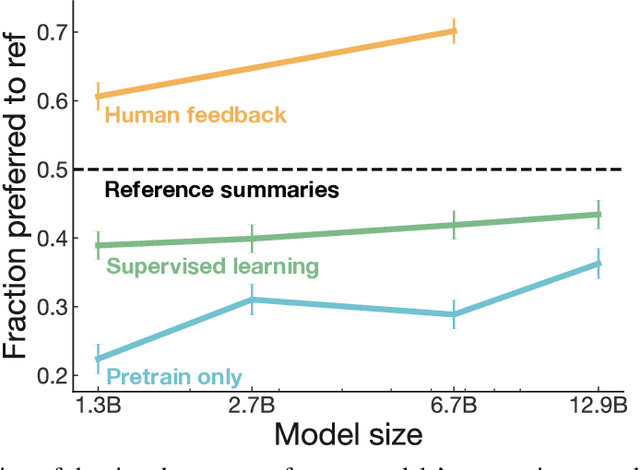
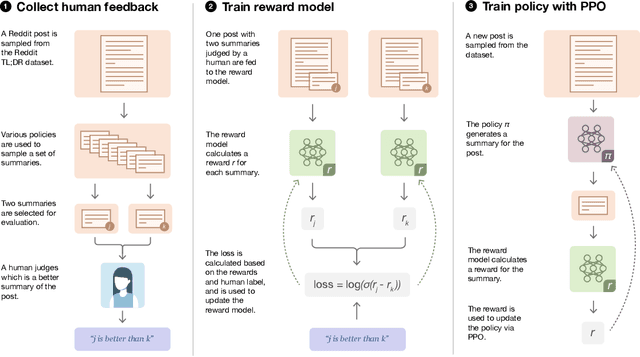
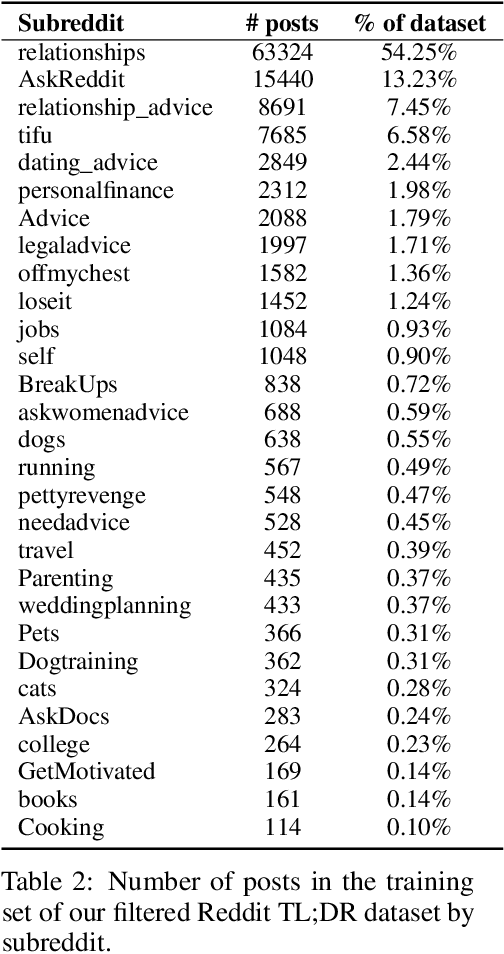
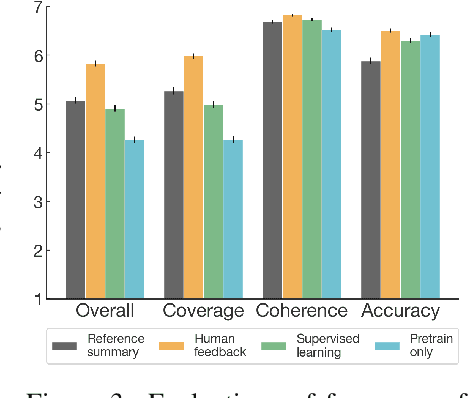
As language models become more powerful, training and evaluation are increasingly bottlenecked by the data and metrics used for a particular task. For example, summarization models are often trained to predict human reference summaries and evaluated using ROUGE, but both of these metrics are rough proxies for what we really care about---summary quality. In this work, we show that it is possible to significantly improve summary quality by training a model to optimize for human preferences. We collect a large, high-quality dataset of human comparisons between summaries, train a model to predict the human-preferred summary, and use that model as a reward function to fine-tune a summarization policy using reinforcement learning. We apply our method to a version of the TL;DR dataset of Reddit posts and find that our models significantly outperform both human reference summaries and much larger models fine-tuned with supervised learning alone. Our models also transfer to CNN/DM news articles, producing summaries nearly as good as the human reference without any news-specific fine-tuning. We conduct extensive analyses to understand our human feedback dataset and fine-tuned models. We establish that our reward model generalizes to new datasets, and that optimizing our reward model results in better summaries than optimizing ROUGE according to humans. We hope the evidence from our paper motivates machine learning researchers to pay closer attention to how their training loss affects the model behavior they actually want.
Ideas for Improving the Field of Machine Learning: Summarizing Discussion from the NeurIPS 2019 Retrospectives Workshop
Jul 21, 2020This report documents ideas for improving the field of machine learning, which arose from discussions at the ML Retrospectives workshop at NeurIPS 2019. The goal of the report is to disseminate these ideas more broadly, and in turn encourage continuing discussion about how the field could improve along these axes. We focus on topics that were most discussed at the workshop: incentives for encouraging alternate forms of scholarship, re-structuring the review process, participation from academia and industry, and how we might better train computer scientists as scientists. Videos from the workshop can be accessed at https://slideslive.com/neurips/west-114-115-retrospectives-a-venue-for-selfreflection-in-ml-research
Learning an Unreferenced Metric for Online Dialogue Evaluation
May 01, 2020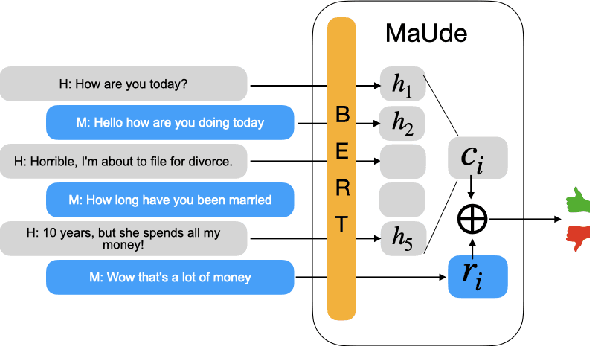
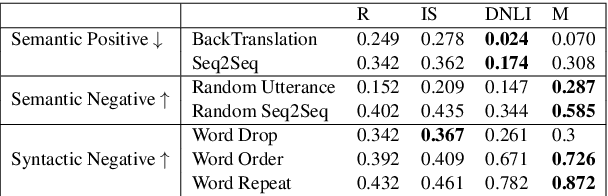
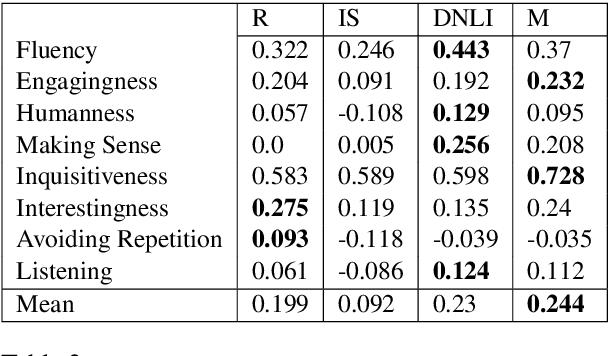

Evaluating the quality of a dialogue interaction between two agents is a difficult task, especially in open-domain chit-chat style dialogue. There have been recent efforts to develop automatic dialogue evaluation metrics, but most of them do not generalize to unseen datasets and/or need a human-generated reference response during inference, making it infeasible for online evaluation. Here, we propose an unreferenced automated evaluation metric that uses large pre-trained language models to extract latent representations of utterances, and leverages the temporal transitions that exist between them. We show that our model achieves higher correlation with human annotations in an online setting, while not requiring true responses for comparison during inference.
On the interaction between supervision and self-play in emergent communication
Feb 04, 2020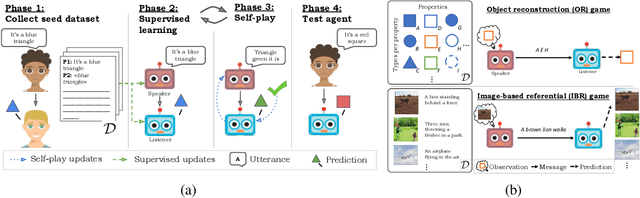
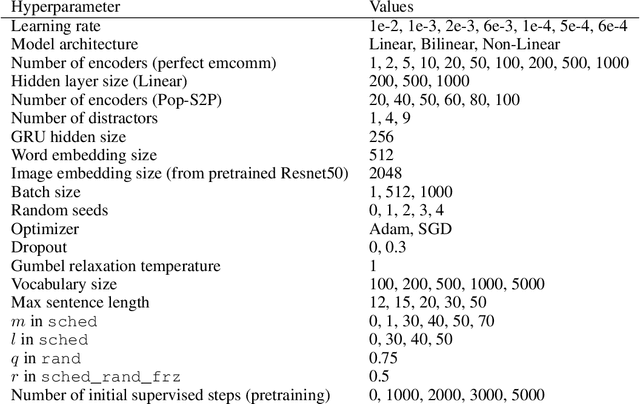
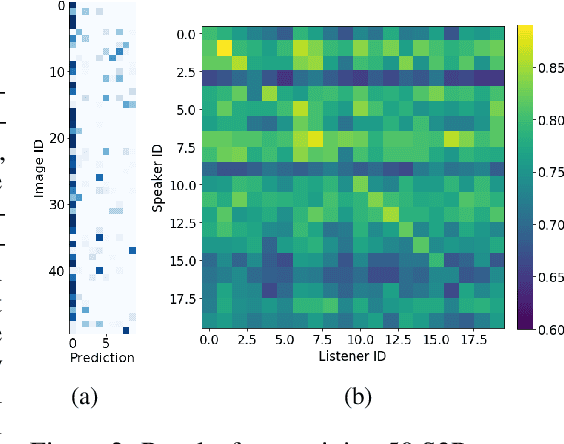
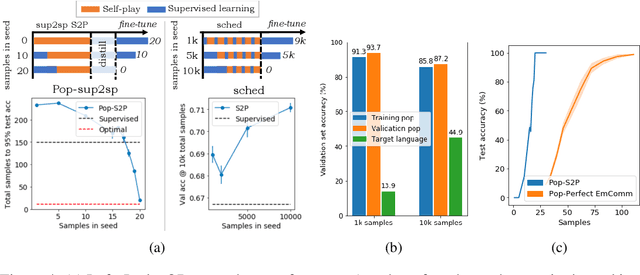
A promising approach for teaching artificial agents to use natural language involves using human-in-the-loop training. However, recent work suggests that current machine learning methods are too data inefficient to be trained in this way from scratch. In this paper, we investigate the relationship between two categories of learning signals with the ultimate goal of improving sample efficiency: imitating human language data via supervised learning, and maximizing reward in a simulated multi-agent environment via self-play (as done in emergent communication), and introduce the term supervised self-play (S2P) for algorithms using both of these signals. We find that first training agents via supervised learning on human data followed by self-play outperforms the converse, suggesting that it is not beneficial to emerge languages from scratch. We then empirically investigate various S2P schedules that begin with supervised learning in two environments: a Lewis signaling game with symbolic inputs, and an image-based referential game with natural language descriptions. Lastly, we introduce population based approaches to S2P, which further improves the performance over single-agent methods.
On the Pitfalls of Measuring Emergent Communication
Mar 12, 2019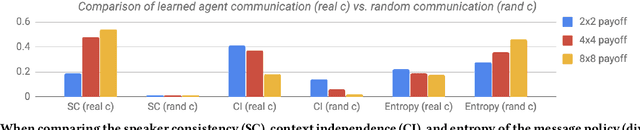
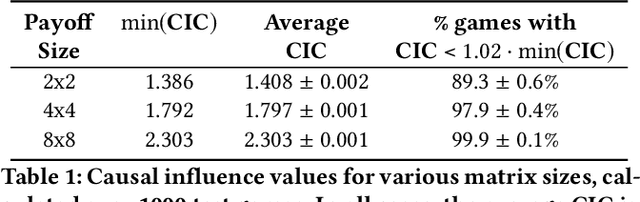
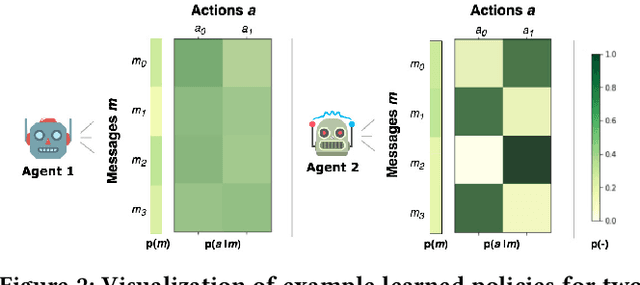
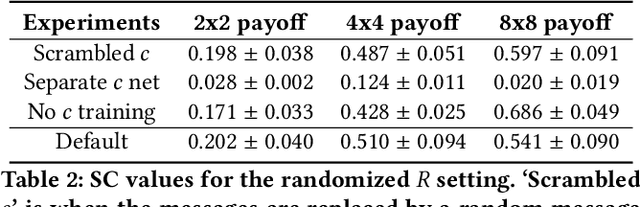
How do we know if communication is emerging in a multi-agent system? The vast majority of recent papers on emergent communication show that adding a communication channel leads to an increase in reward or task success. This is a useful indicator, but provides only a coarse measure of the agent's learned communication abilities. As we move towards more complex environments, it becomes imperative to have a set of finer tools that allow qualitative and quantitative insights into the emergence of communication. This may be especially useful to allow humans to monitor agents' behaviour, whether for fault detection, assessing performance, or even building trust. In this paper, we examine a few intuitive existing metrics for measuring communication, and show that they can be misleading. Specifically, by training deep reinforcement learning agents to play simple matrix games augmented with a communication channel, we find a scenario where agents appear to communicate (their messages provide information about their subsequent action), and yet the messages do not impact the environment or other agent in any way. We explain this phenomenon using ablation studies and by visualizing the representations of the learned policies. We also survey some commonly used metrics for measuring emergent communication, and provide recommendations as to when these metrics should be used.
The Second Conversational Intelligence Challenge (ConvAI2)
Jan 31, 2019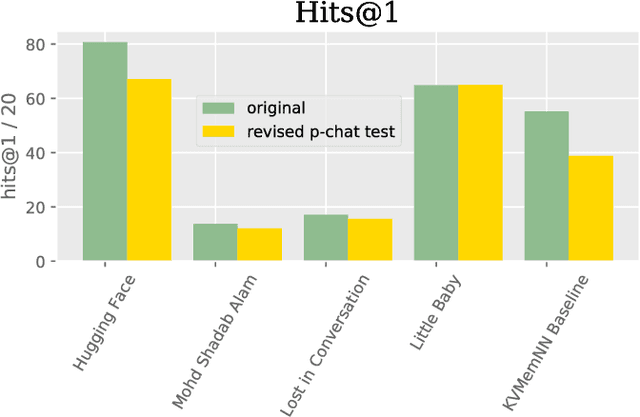

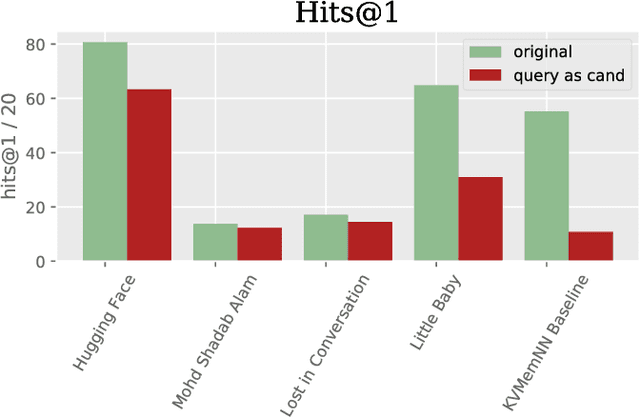
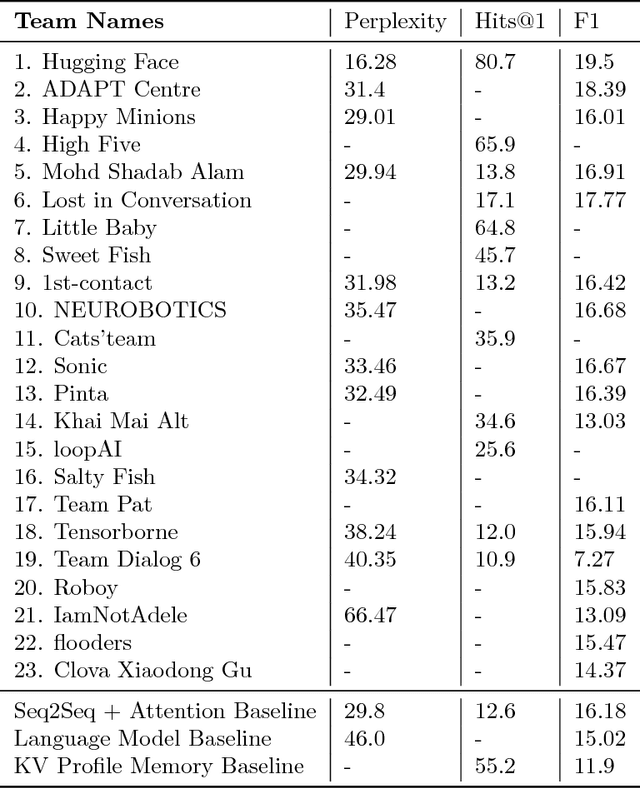
We describe the setting and results of the ConvAI2 NeurIPS competition that aims to further the state-of-the-art in open-domain chatbots. Some key takeaways from the competition are: (i) pretrained Transformer variants are currently the best performing models on this task, (ii) but to improve performance on multi-turn conversations with humans, future systems must go beyond single word metrics like perplexity to measure the performance across sequences of utterances (conversations) -- in terms of repetition, consistency and balance of dialogue acts (e.g. how many questions asked vs. answered).
Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments
Jan 16, 2018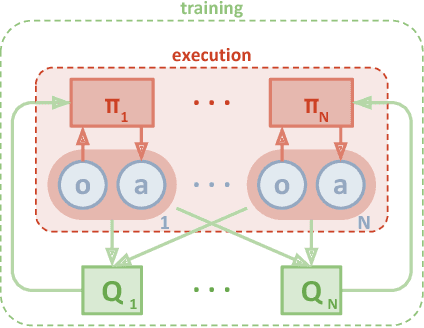
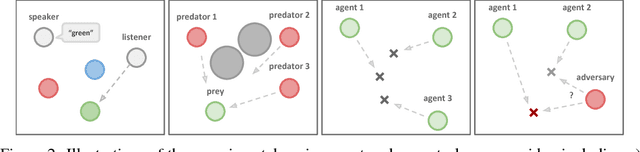
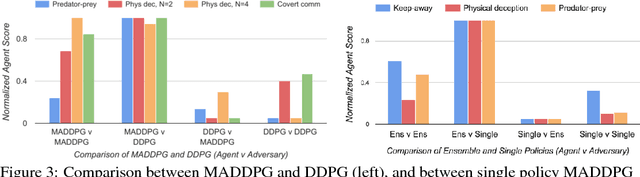
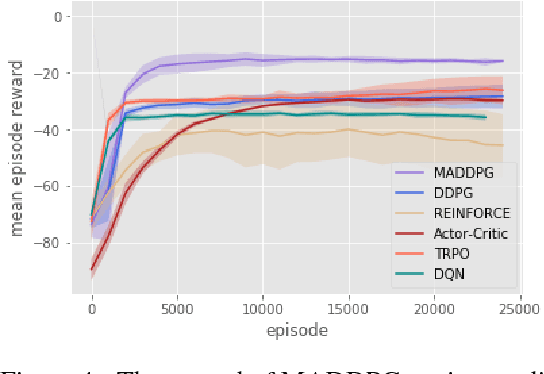
We explore deep reinforcement learning methods for multi-agent domains. We begin by analyzing the difficulty of traditional algorithms in the multi-agent case: Q-learning is challenged by an inherent non-stationarity of the environment, while policy gradient suffers from a variance that increases as the number of agents grows. We then present an adaptation of actor-critic methods that considers action policies of other agents and is able to successfully learn policies that require complex multi-agent coordination. Additionally, we introduce a training regimen utilizing an ensemble of policies for each agent that leads to more robust multi-agent policies. We show the strength of our approach compared to existing methods in cooperative as well as competitive scenarios, where agent populations are able to discover various physical and informational coordination strategies.
Towards an Automatic Turing Test: Learning to Evaluate Dialogue Responses
Jan 16, 2018
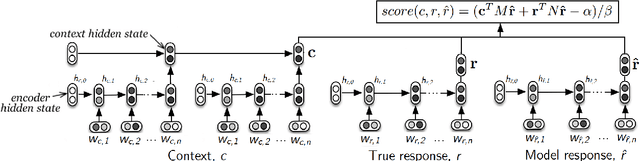
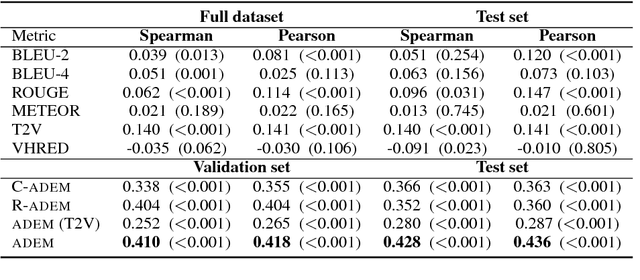
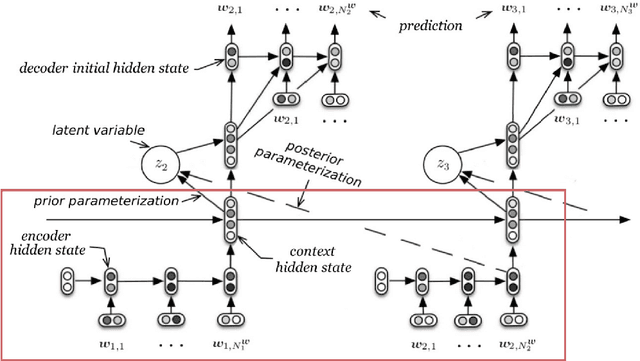
Automatically evaluating the quality of dialogue responses for unstructured domains is a challenging problem. Unfortunately, existing automatic evaluation metrics are biased and correlate very poorly with human judgements of response quality. Yet having an accurate automatic evaluation procedure is crucial for dialogue research, as it allows rapid prototyping and testing of new models with fewer expensive human evaluations. In response to this challenge, we formulate automatic dialogue evaluation as a learning problem. We present an evaluation model (ADEM) that learns to predict human-like scores to input responses, using a new dataset of human response scores. We show that the ADEM model's predictions correlate significantly, and at a level much higher than word-overlap metrics such as BLEU, with human judgements at both the utterance and system-level. We also show that ADEM can generalize to evaluating dialogue models unseen during training, an important step for automatic dialogue evaluation.
* ACL 2017